将 600 亿参数大模型装进手机的瓶颈,终于被中国 AI 公司突破了
爱范儿2653 字 (约 11 分钟)
92
中国AI公司突破三值量化技术,使600亿参数模型可在手机运行,节省6倍显存且性能损失极小。
入选理由:三值量化可节省6倍显存,保留97%模型能力,支持在8GB内存手机运行600亿参数模型。
精选文章#AI模型#三值量化#昇腾芯片#端侧AI#模型压缩中文
概念
别名:Mixture of Experts
混合专家模型架构,通过稀疏激活实现大参数量下的高效推理。
已跟踪 14 条高相关材料
最近变化
2026-06-04 · Nemotron 3 Ultra采用550B参数MoE架构,是面向前沿智能的开源模型。
为什么值得关注
MoE 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
已收录 14 条与 MoE 相关的内容,按评分排序。
中国AI公司突破三值量化技术,使600亿参数模型可在手机运行,节省6倍显存且性能损失极小。
入选理由:三值量化可节省6倍显存,保留97%模型能力,支持在8GB内存手机运行600亿参数模型。
DeepSeek通过多项底层技术创新构建低成本高效能模型体系,旨在撬动中国10万亿美元AI硬件生态并实现自身万亿美元市值。
入选理由:DeepSeek V4 Pro在100万上下文中仅需5.48GB HBM显存,远低于竞品的60-89GB。
DeepSeek通过多项技术创新大幅降低大模型推理中的KV缓存需求,推动中国AI硬件生态发展,目标打造价值10万亿美元的产业巨兽。
入选理由:DeepSeek V4 Pro仅需5.48GB HBM,相比GLM5的60GB和Qwen3-235B-A22B的89GB显著节省显存
Thinking Machines发布TML-Interaction-Small 276B-A12B模型,采用2760亿参数MoE架构与120亿活跃参数,实现<200ms端到端延迟,显著超越GPT-4o和Gemini 3.1-Flash,在实时语音交互、时间对齐微回合与视觉主动性任务上达到SOTA,彻底淘汰传统VAD机制。
入选理由:TML-Interaction-Small为276B参数MoE模型,仅12B激活参数,实现<200ms端到端延迟。
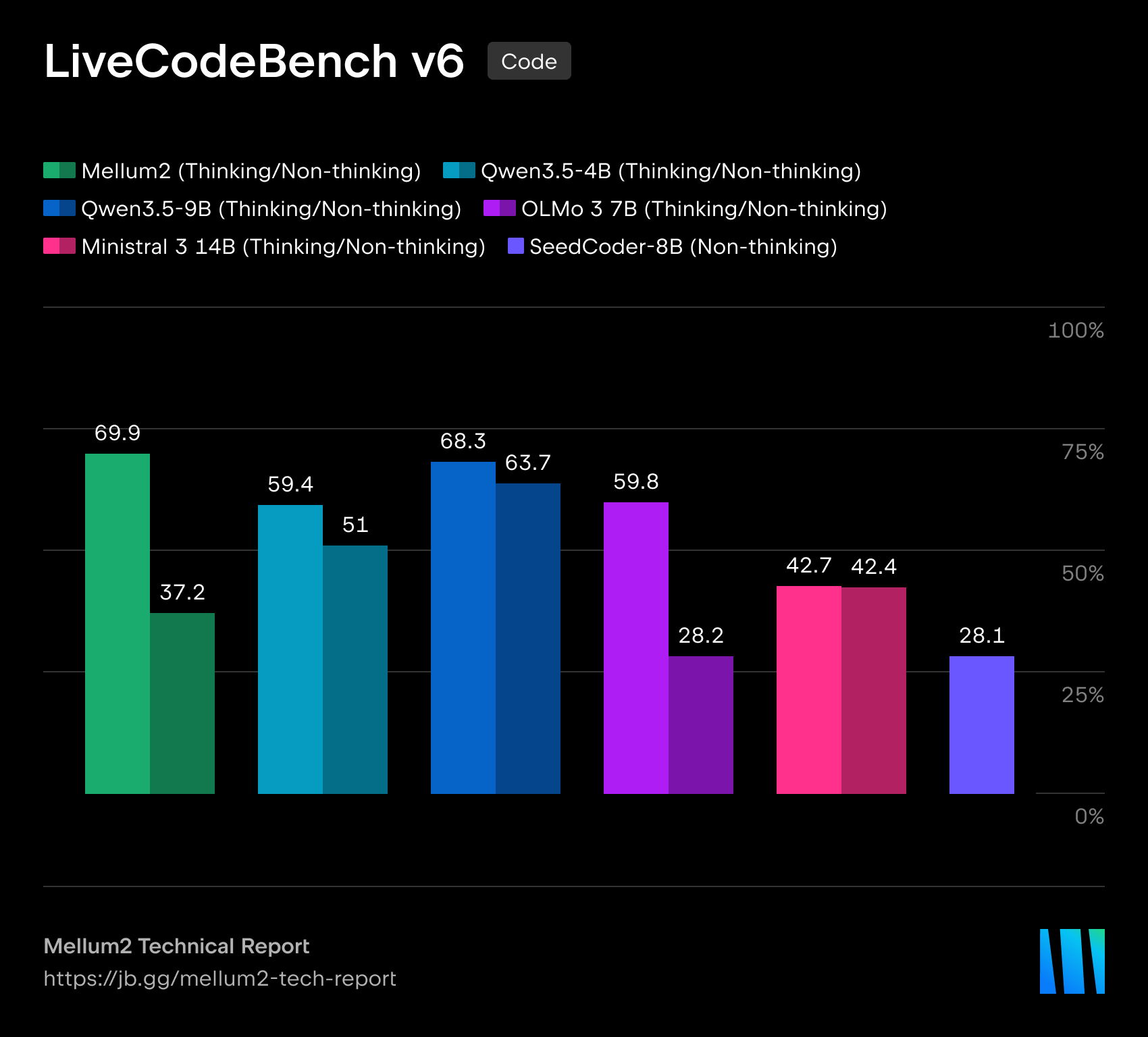
Mellum2是JetBrains开源的12B参数AI模型,采用MoE架构使每token仅激活2.5B参数,推理速度比同类模型快50%,专为软件工程环境设计,适用于路由、RAG管道和私有AI部署等场景。
入选理由:Mellum2采用MoE架构,12B参数模型每token仅激活2.5B参数,推理速度比同类模型快50%,显著降低生产环境延迟和成本
阶跃星辰发布的 Step 3.7 Flash 是面向生产级 AI Agent 的新一代 Flash 模型,具备原生多模态理解、高吞吐低延迟和联网搜索增强能力,在编程任务中性能接近 Claude Opus 4.6 的 97%,但成本仅为后者约 1/9,适合高频、复杂、真实工作流场景。
入选理由:Step 3.7 Flash 采用稀疏 MoE 架构,激活参数仅 11B,最高生成速度达 400 Tokens/s,支持 40 个 Agent 并行运行。
Step 3.7 Flash 是一个支持多模态的 MoE 模型,仅激活 11B 参数即可处理 196B 参数规模的任务,适用于编码、代理工作流和结构化输出。
入选理由:Step 3.7 Flash 模型通过激活 11B 参数处理 196B 参数规模任务,显著降低计算成本。
文章提出了一种新的序列级负载均衡方法Moving Quantile Balancing(MQB),可在不依赖辅助损失的情况下实现MoE模型中的细粒度均衡。
入选理由:MQB方法基于Quantile Balancing演化而来,适用于序列级负载均衡。
Perplexity 发布了关于如何在 NVIDIA GB200 NVL72 Blackwell 机架上部署 Qwen3 235B 模型的研究,GB200 在大规模 MoE 模型的高吞吐量推理方面优于 Hopper。
入选理由:Qwen3 235B 模型在 NVIDIA GB200 上实现了高效的高吞吐量推理。
NVLS 全归约延迟显著改善,从 H200 的 586.1 微秒降至 GB200 的 313.3 微秒,MoE 预填充和解码吞吐量也有显著提升。
入选理由:NVLS all-reduce latency drops from 586.1µs on H200 to 313.3µs on GB200.
NVIDIA发布550B参数MoE开源模型Nemotron 3 Ultra,专为长时运行Agent设计,推理速度提升5倍且复杂任务成本降低30%。
入选理由:Nemotron 3 Ultra采用550B参数MoE架构,是面向前沿智能的开源模型。
ZEDA 是一种新型 MoE 技术,通过自蒸馏实现动态专家跳过,提升推理效率并赋予模型算力预算意识。
入选理由:ZEDA 使用自蒸馏方法使 MoE 模型跳过一半专家,提升推理效率。
MACE论文提出基于MoE架构的音乐驱动舞蹈视频生成方法,提升动作与节奏的同步性,可能应用于抖音等平台的AI跳舞视频。
入选理由:MACE使用MoE架构实现音乐到舞蹈动作的高精度对齐,提升生成视频的真实感。
NVIDIA推出Nemotron 3 Ultra开源模型,宣称推理速度提升5倍、运行成本降低30%,但未提供架构细节和实证数据。
入选理由:Nemotron 3 Ultra采用SSM与MoE混合架构,推理速度比现有开源模型快5倍。


![[AINews] Thinking Machines' Native Interaction Models - TML-Interaction-Small 276B-A12B - advances SOTA Realtime Voice and kills standard VAD](https://substackcdn.com/image/fetch/$s_!LR03!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F02190942-3f50-4067-ae03-97c6b504b3a3_1490x1592.png)