Mellum2 开源:适用于AI工作流的快速模型

TL;DR · AI 摘要
Mellum2是JetBrains开源的12B参数AI模型,采用MoE架构使每token仅激活2.5B参数,推理速度比同类模型快50%,专为软件工程环境设计,适用于路由、RAG管道和私有AI部署等场景。
核心要点
- Mellum2采用MoE架构,12B参数模型每token仅激活2.5B参数,推理速度比同类模型快50%,显著降低生产环境延迟和成本
- 该模型专注于自然语言和代码处理,不支持多模态,使其在软件工程场景中表现更优,同时保持轻量高效
- JetBrains提出'焦点模型'理念,认为AI系统应由多个高效、专业化的模型组成,Mellum2是这一理念的实践,适用于高频率任务
结构提纲
按章节快速跳转。
Mellum2是JetBrains开源的12B参数AI模型,采用MoE架构设计,专为解决生产环境中的延迟、吞吐量和成本问题而构建。
Mellum2采用Mixture-of-Experts设计,12B总参数中每token仅激活2.5B参数,推理时间比同类模型减少超过50%。
- ·应用场景
Mellum2适用于AI工作流路由、低延迟RAG管道构建、复杂工作流中的子代理以及私有本地AI部署等场景。
JetBrains提出AI系统应由协调的系统而非单一模型组成,Mellum2作为焦点模型能高效处理高频任务。
开发者可通过Hugging Face平台尝试Mellum2,适用于软件工程AI系统构建、RAG管道和代理工作流等场景。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- Mellum2开源模型
- 架构特点
- MoE设计
- 12B参数,2.5B激活
- 性能优势
- 推理速度提升50%
- 低延迟、高吞吐
- 应用场景
- AI工作流路由
- RAG管道构建
- 私有AI部署
金句 / Highlights
值得收藏与分享的关键句。
Mellum2是通过其架构和专注、高效的设计来解决生产规模系统瓶颈的。
Mellum2在推理时间上比同类模型减少了一半,这对生产级部署是一个决定性优势。
在JetBrains,我们认为未来属于协调系统,而不是单一模型。前沿模型将继续推动极限,但实用的AI产品也需要焦点模型:能够高效处理高频任务的快速、专业组件。

Supercharge your tools with AI-powered features inside many JetBrains products
Mellum2 Goes Open Source: A Fast Model for AI Workflows


June 1, 2026
Trained from scratch and designed for practical deployment, Mellum2 is built for routing, Q&A, sub-agents, and private AI use in software engineering systems.
Today, we’re open-sourcing Mellum2, a 12B model engineered to solve the hardest parts of production AI: latency, throughput, and cost. Built from scratch and released under the Apache 2.0 license, Mellum2 offers a high-performance, cost-efficient alternative for your infrastructure.
Mellum began with code completion; now we’ve evolved it to handle both natural language and code. It is now a versatile tool ready to power routing, summarization, and intermediate reasoning steps across your modern AI workflows.
Whether you want to experiment, fine-tune, or deploy at scale, Mellum2 is ready to run in your own systems.
Architecture and performance
Mellum2 is engineered to solve the bottlenecks of production-scale systems through its architecture and focused, efficiency-driven design.
- Mixture-of-Experts (MoE) design: The model features 12B total parameters, but because it uses a MoE design, only 2.5B parameters are active per token. This reduces compute costs while enabling high-throughput, low-latency inference for real-time workloads.
- Specialized focus: Unlike many modern models, Mellum2 is not multimodal. It is trained specifically on natural language and code data. This specialization ensures the model excels in software engineering environments while remaining lean and fast.
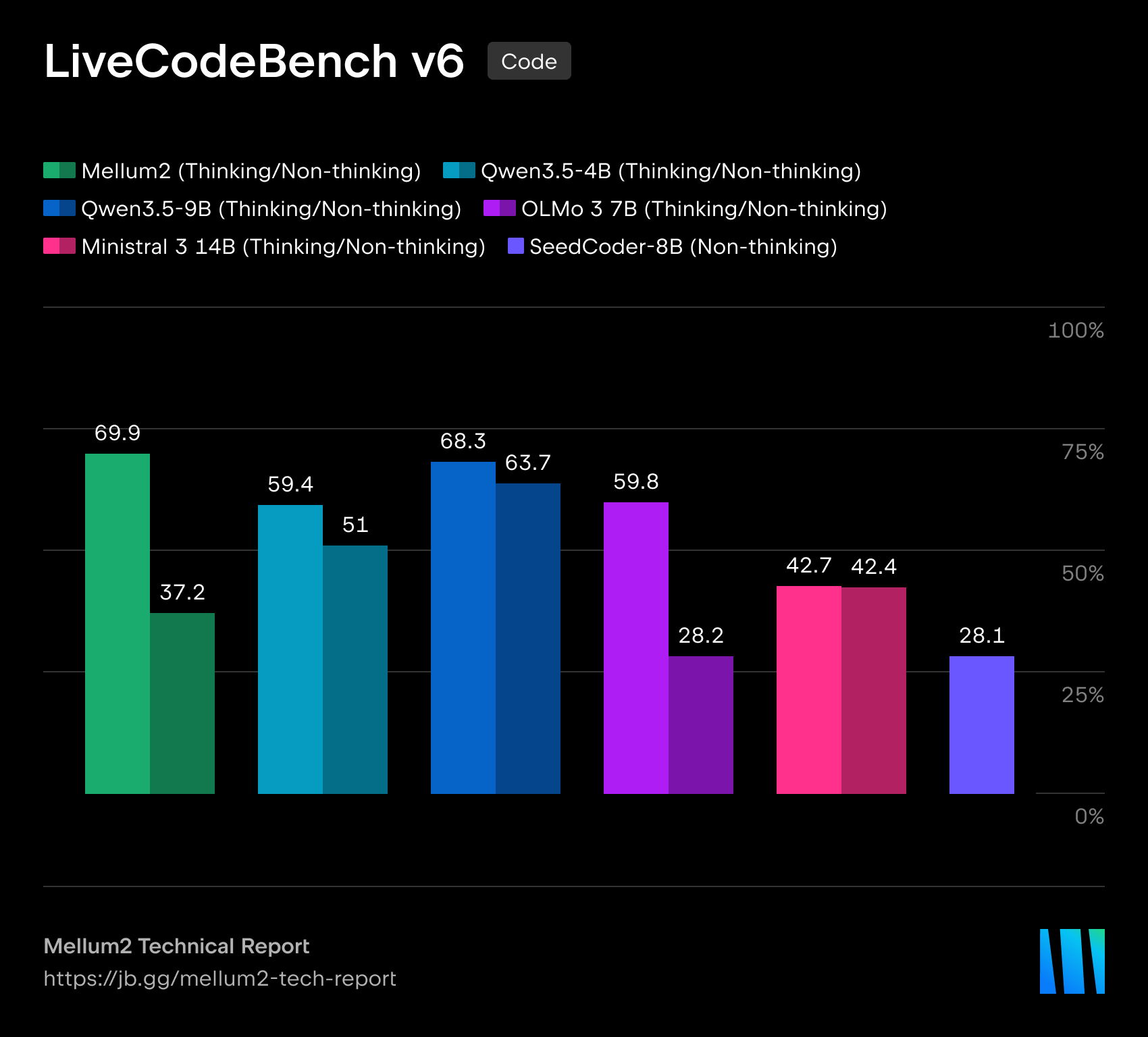
In our technical report, we detail our model’s performance across code generation, science, math, and reasoning benchmarks. Mellum2 is competitive with other similar-sized models while cutting inference time to less than half – a definitive advantage for production-grade deployments.

Key use cases for Mellum2
- Route and orchestrate AI workloads: Use Mellum2 to analyze incoming prompts and help select the right model or tool for each task.
- Build low-latency RAG pipelines: Retrieve relevant context, use Mellum2 to summarize it, and generate responses instantly.
- Power fast sub-agents in complex workflows: Break down agent pipelines into steps like context gathering, planning, and validation. Use Mellum2 for fast, specialized tasks instead of relying on a single large model.
- Enable private, local AI deployment: Run Mellum2 locally or self-host it to keep code and data fully under your control.
The “focal model” philosophy: Why focused models scale better
As AI systems become more complex, performance bottlenecks shift from raw capability to latency, throughput, and cost at scale. Not every task requires the largest model. Many steps in modern AI systems are repetitive, latency-sensitive, and high-frequency. These steps benefit from a fast and reliable model that can be efficiently routed, hosted, and controlled.
At JetBrains, we believe the future belongs to coordinated systems, not single models. Frontier models will continue to push the limits, but practical AI products also require focal models: fast, specialized components that handle high-frequency tasks efficiently.
That’s the role we see for Mellum2 in the next generation of AI software tooling.
Get started with Mellum2
If you’re building AI systems for software engineering – whether inside an IDE, in a RAG pipeline, as part of an agent workflow, or fully on your own infrastructure – we’d love for you to try Mellum2.
Open source is how better tools get made.
[](https://blog.jetbrains.com/ai/2026/06/mellum2-goes-open-source-a-fast-model-for-ai-workflows/#)
- Architecture and performance
- Key use cases for Mellum2
- The “focal model” philosophy: Why focused models scale better
- Get started with Mellum2