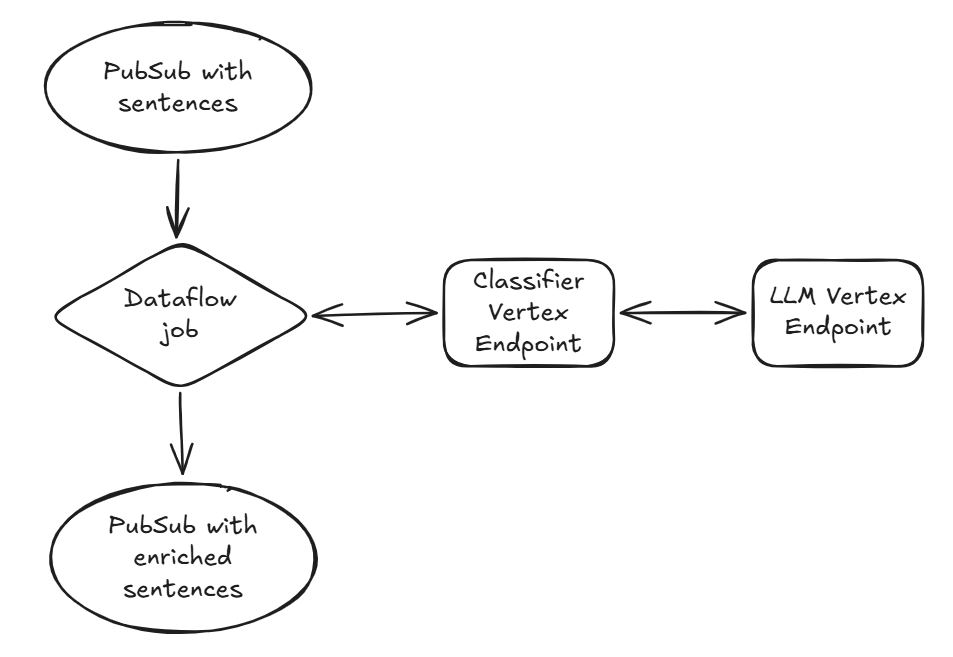
Trustpilot 如何使用 Gemma 构建实时数据增强架构
Google Cloud Blog992 字 (约 4 分钟)
92
Trustpilot 使用微调的 Gemma 模型构建了实时数据增强架构,处理百万级评论,延迟低、成本可控,性能接近教师模型且独立可控。
入选理由:采用 google/gemma-2-9b 基础模型,通过共识标注生成高质量训练集,微调后准确率仅比教师模型低几个百分点。
精选文章#Gemma#Dataflow#LLM#实时架构#微调英文
产品
别名:vlm
High-throughput and memory-efficient inference and serving engine for LLMs.
已跟踪 15 条高相关材料
最近变化
2026-06-04 · 70B参数模型仅加载权重需约140GB显存,每个活跃请求还需独立KV Cache存储上下文。
为什么值得关注
vLLM 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
How Trustpilot built a real-time architecture for data enrichment using Gemma
Google Cloud Blog · 9.2 分
Trustpilot 使用微调的 Gemma 模型构建了实时数据增强架构,处理百万级评论,延迟低、成本可控,性能接近教师模型且独立可控。
英伟达重新思考AI TCO:为何每Token成本才是唯一重要的指标
量子位 · 9.2 分
英伟达提出以每Token成本作为AI基础设施的核心经济指标,取代传统的算力成本或每美元FLOPS评估方式,强调全栈优化对降低推理成本、提升商业价值的关键作用。
Build real-time voice applications with Amazon SageMaker AI and vLLM
AWS Machine Learning Blog · 8.7 分
AWS推出SageMaker AI与vLLM结合方案,实现双向流式语音转文本推理,支持实时语音助手、直播字幕等应用,显著降低延迟并消除手工构建流式传输管道的负担。
已收录 15 条与 vLLM 相关的内容,按评分排序。
Trustpilot 使用微调的 Gemma 模型构建了实时数据增强架构,处理百万级评论,延迟低、成本可控,性能接近教师模型且独立可控。
入选理由:采用 google/gemma-2-9b 基础模型,通过共识标注生成高质量训练集,微调后准确率仅比教师模型低几个百分点。
英伟达提出以每Token成本作为AI基础设施的核心经济指标,取代传统的算力成本或每美元FLOPS评估方式,强调全栈优化对降低推理成本、提升商业价值的关键作用。
入选理由:每Token成本是衡量AI基础设施经济效益的核心指标,直接反映实际产出效率。
AWS推出SageMaker AI与vLLM结合方案,实现双向流式语音转文本推理,支持实时语音助手、直播字幕等应用,显著降低延迟。
入选理由:SageMaker AI提供原生HTTP/2双向流式传输(端口8443),自动处理HTTP/2事件流与WebSocket协议转换
本地部署LLM代理需解决推理速度与长会话状态管理问题,通过优化vLLM服务器和结构化世界状态,可将单次调用耗时从15秒降至2秒以内,支持科学工作流的可复现性需求。
入选理由:使用vLLM优化推理性能,单次调用耗时从15秒降至2秒内
vLLM 模型在高并发场景下存在吞 Token 的严重问题,范式团队已修复该漏洞。
入选理由:vLLM 在高并发场景中存在吞 Token 的严重缺陷。
课程讲授如何利用vLLM高效部署开源大模型,涉及量化、分页注意力等技术。
入选理由:70亿参数大模型需约140GB内存,可能需要多GPU支持单次请求。
Cognition以260亿美元估值完成10亿美元D轮融资,成为最大独立AI智能体实验室;ARR预计年底超10亿美元;推理优化转向架构级改进,EAGLE 3.1、vLLM等显著提升长上下文稳定性与吞吐效率。
入选理由:Cognition D轮融资10亿美元,估值达260亿美元, 成为最大独立AI智能体实验室(2026年5月)
高效服务LLM的核心在于通过量化和vLLM智能内存管理解决70B模型140GB显存及KV Cache瓶颈,实现低延迟高并发部署。
入选理由:70B参数模型仅加载权重需约140GB显存,每个活跃请求还需独立KV Cache存储上下文。
TokenSpeed 是一个专为代理型工作负载优化的新型开源 LLM 推理引擎,具备高性能 KV 缓存管理、高效调度器和跨芯片支持的模块化内核架构。
入选理由:TokenSpeed 实现了媲美 TensorRT-LLM 的性能与接近 vLLM 的易用性。
NVIDIA 研究提出将 speculative decoding 引入 NeMo-RL + vLLM 架构,实现 RL 后训练 rollout 阶段无损加速:8B 模型吞吐提升 1.8 倍,235B 模型端到端预计提速 2.5 倍。
入选理由:RLHF/RLAIF 后训练的 rollout 阶段已成为性能瓶颈
Google 宣布其模型权重与主流开源生态兼容,可在 Hugging Face 和 Kaggle 直接下载,降低部署门槛。
入选理由:Gemma 4 权重与 llama.cpp、vLLM、Ollama 等生态兼容,便于本地部署与推理。
DeepLearning.AI联合RedHat推出vLLM推理优化免费短课,教授开源模型量化、vLLM部署及速度成本精度基准测试方法。
入选理由:课程涵盖开源LLM量化技术,直接降低显存占用与推理成本。
Cohere发布了其迄今为止最强大的大语言模型Command A+,优化为能在最少硬件上运行,并以开源形式发布。
入选理由:Cohere推出最强LLM模型Command A+
文章描述了范式团队修复vLLM中一个隐藏的性能问题,该问题在高并发场景下会导致Token处理异常。
入选理由:vLLM存在高并发下吞Token的性能缺陷
NVIDIA AI 官方账号转发 vLLM 项目启动链接,并附带指向 NVIDIA-NeMo/RL GitHub 仓库的短链,内容无技术细节或上下文。
入选理由:仅含推广性短链接,无代码说明、性能数据或使用指南




![[AINews] Cognition raises $1B in $26B Series D](https://substackcdn.com/image/fetch/$s_!l_fo!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc283a27b-c506-4ee9-8b9a-47650b429a01_2534x1694.png)