从正则到视觉模型:哪种 RAG 技术适合你的问题
Towards Data Science4997 字 (约 20 分钟)
90
RAG 技术并非万能,应根据文档结构和问题控制程度选择合适方法:模板化文档用正则表达式,客服对话需 LLM 判断语调,工程图纸必须使用视觉模型。
入选理由:模板化文档(如保险单、银行流水)适合用正则表达式提取字段,避免使用高成本的 RAG 流程。
精选文章#RAG#LLM#文档智能#视觉模型#企业AI英文
概念
别名:Large Language Model
大语言模型,本文讨论的应用架构演进的基础技术底座。
已跟踪 30 条高相关材料
最近变化
2026-06-04 · 神经符号 AI 将在经济性、数据与能耗上大幅优于 LLM,有望带来巨额利润。
为什么值得关注
LLM 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
From Regex to Vision Models: Which RAG Technique Fits Which Problem
Towards Data Science · 9 分
RAG 技术并非万能,应根据文档结构和问题控制程度选择合适方法:模板化文档用正则表达式,客服对话需 LLM 判断语调,工程图纸必须使用视觉模型。
Your Enterprise Data Deserves Better Than a Chatbot
Gradient Flow · 8.7 分
企业数据治理不应依赖聊天机器人,关系型与时间序列数据正迎来专用基础模型的突破,KumoRFM-2在少标注下超越监督与通用基模,但高风险金融与医疗场景需谨慎验证与治理。
Fragments: Dodgy metrics for AI usage, history of tech removing jobs, benchmarking closed and open m...
Martin Fowler(@martinfowler) · 8.5 分
Martin Fowler 指出当前 AI 使用存在虚假指标、技术替代人力的历史模式、闭源与开源模型的基准测试差异,以及大语言模型加剧代码冗余和低质量产出的问题。
已收录 30 条与 LLM 相关的内容,按评分排序。
RAG 技术并非万能,应根据文档结构和问题控制程度选择合适方法:模板化文档用正则表达式,客服对话需 LLM 判断语调,工程图纸必须使用视觉模型。
入选理由:模板化文档(如保险单、银行流水)适合用正则表达式提取字段,避免使用高成本的 RAG 流程。
企业数据治理不应依赖聊天机器人,关系型与时间序列数据正迎来专用基础模型的突破,KumoRFM-2在少标注下超越监督与通用基模,但高风险金融与医疗场景需谨慎验证与治理。
入选理由:KumoRFM-2仅用少量标注即可在多表关系数据上预测,超越监督基线与通用基模,显著降低数据科学管线复杂度。
Martin Fowler 指出当前 AI 使用存在虚假指标、技术替代人力的历史模式、闭源与开源模型的基准测试差异,以及大语言模型加剧代码冗余和低质量产出的问题。
入选理由:AI 使用中的‘虚假指标’如 token 数量无法真实反映价值,应关注实际任务完成度。
FDE角色在AI领域复兴,但AI工程师职位将远多于FDEs,因为公司偏好内部员工以保持选项灵活性,避免vendor lock-in。
入选理由:FDEs需技术、沟通和业务技能,用于定制agentic workflows(如OpenAI/Anthropic的实践)。
Amazon Quick Research 通过整合 PubMed 等生物医学数据库与 LLM 合成能力,将罕见癌症研究的数据集成周期从数周缩短至小时级,支持版本化修订与可追溯引用报告生成。
入选理由:使用 Amazon Quick Research 可将多源异构生物医学数据(如 PubMed、ClinicalTrials.gov)的整合时间从数周压缩至数小时。
作者反思AI工具滥用导致大量无用项目堆积,认为取消AI订阅是回归专注力的必要手段;AI虽强大但鼓励低质量、碎片化产出,反而削弱工程深度与产品价值。
入选理由:作者列出30+用AI构建的项目,仅SaaS存活,其余皆无维护价值且耗时耗能。
LLM 是交互式虚构作品的合成产物,而非真实存在的实体,用户与其互动时实际是在与模拟角色交流。
入选理由:LLM 的回应并非来自神经网络本身,而是基于虚构角色的模拟输出。
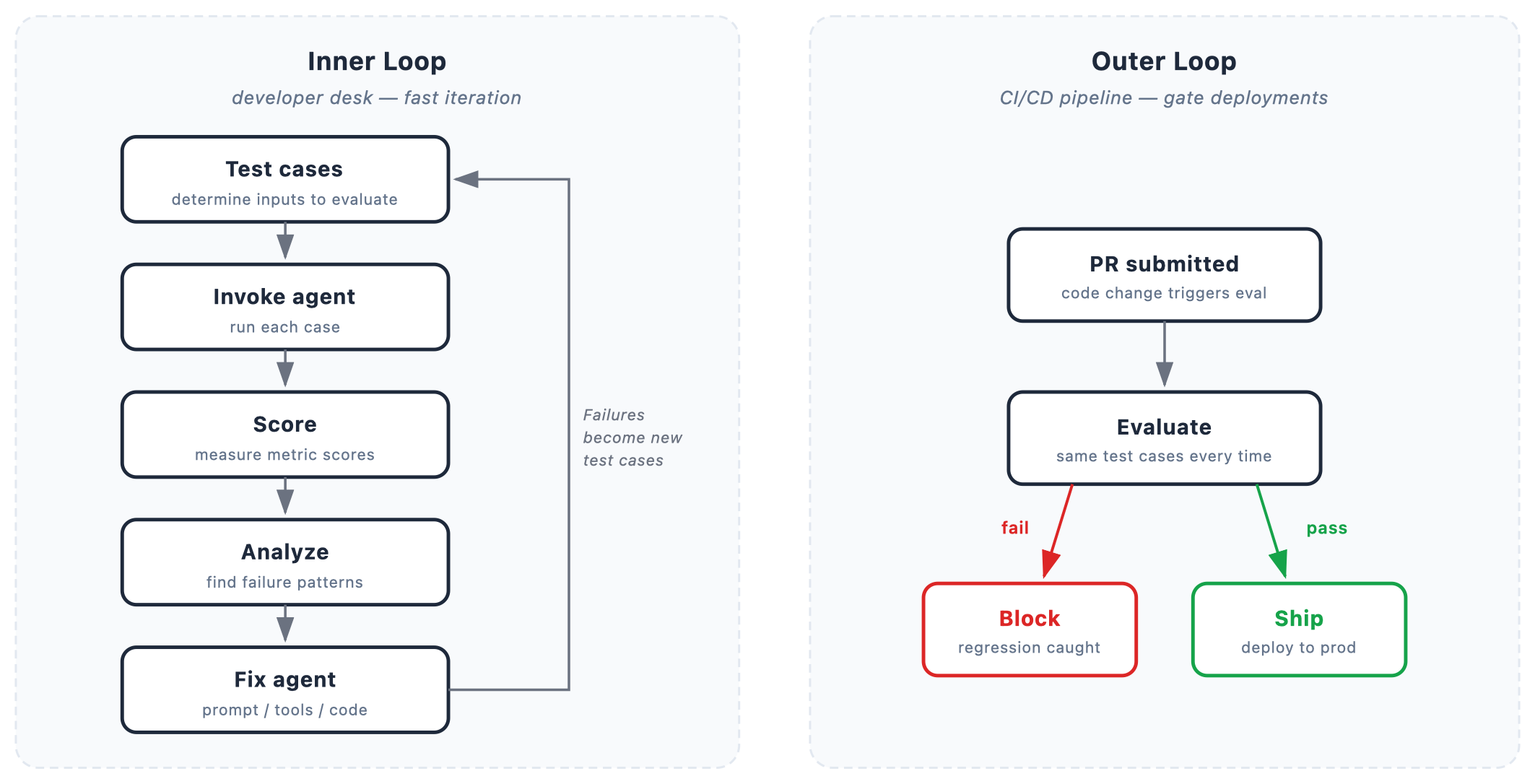
Amazon Bedrock AgentCore 提供版本化数据集管理,确保代理测试的稳定性和可重复性,提升开发与 CI/CD 流程中的评估质量。
入选理由:Amazon Bedrock AgentCore 支持预定义场景和用户模拟场景两种测试模式。
Ollama 是运行本地语言模型的强大工具,通过 Modelfile 和环境变量可优化模型性能与硬件效率。
入选理由:通过 Ollama Modelfile 可封装模型参数,简化本地模型调用流程。
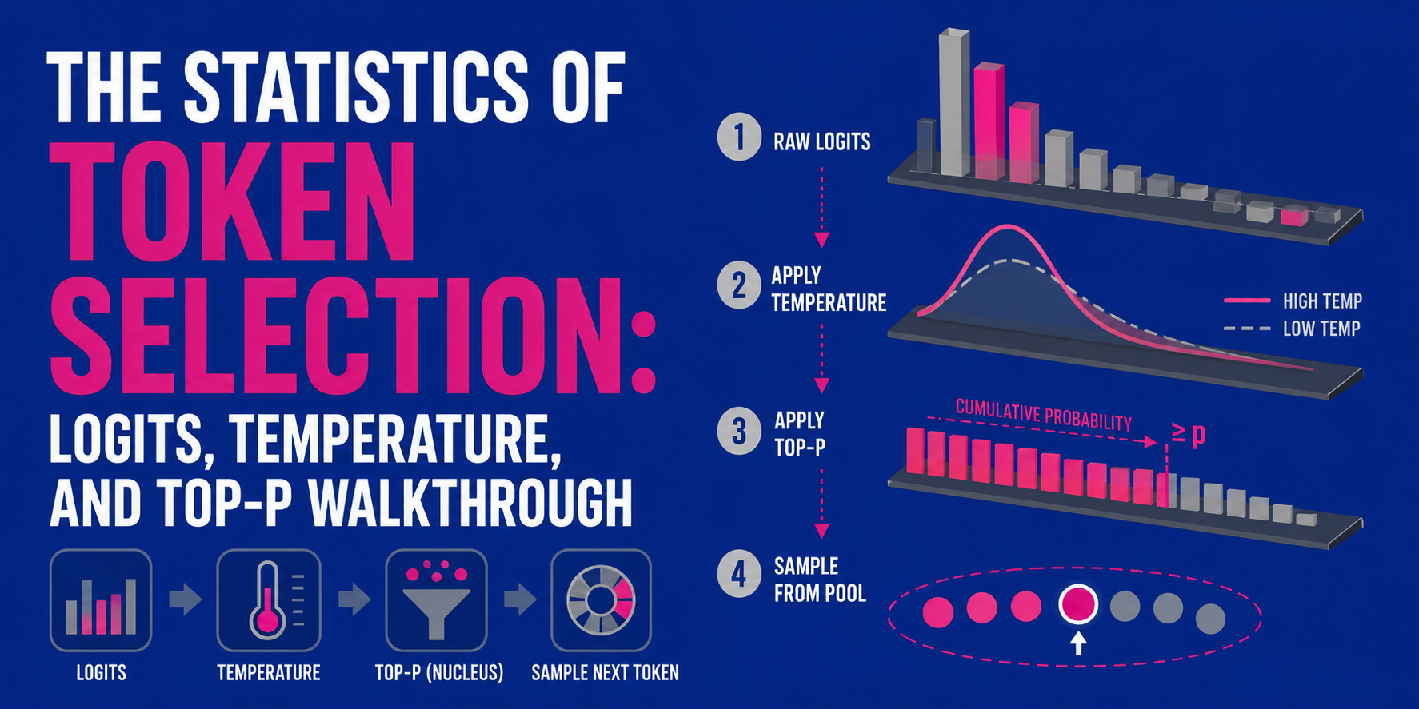
文章介绍了大语言模型(LLM)中的token选择机制,包括logits、temperature和top-p的原理及其在输出生成中的作用。
入选理由:logits是模型输出的原始未归一化分数,通过softmax转换为概率分布。
Simon Willison认为2026年4月,OpenAI和Anthropic找到了产品市场契合点,预计Anthropic即将实现盈利。
入选理由:2026年4月,OpenAI和Anthropic找到了产品市场契合点。
大多数AI代理在生产环境中失败是因为它们的架构设计不当,而不是能力不足。正确的架构应该将决策层和编排层分开,而不是让单一模型承担所有任务。
入选理由:AI代理失败的原因在于架构设计不当,而非能力不足。
Martin Fowler 在 GOTO 领导者峰会上讨论了 LLM-augmented 编程的经验,包括 Kent Beck 和 Ian Johnson 的案例研究。
入选理由:LLM-augmented 编程需要谨慎管理,避免过度依赖。
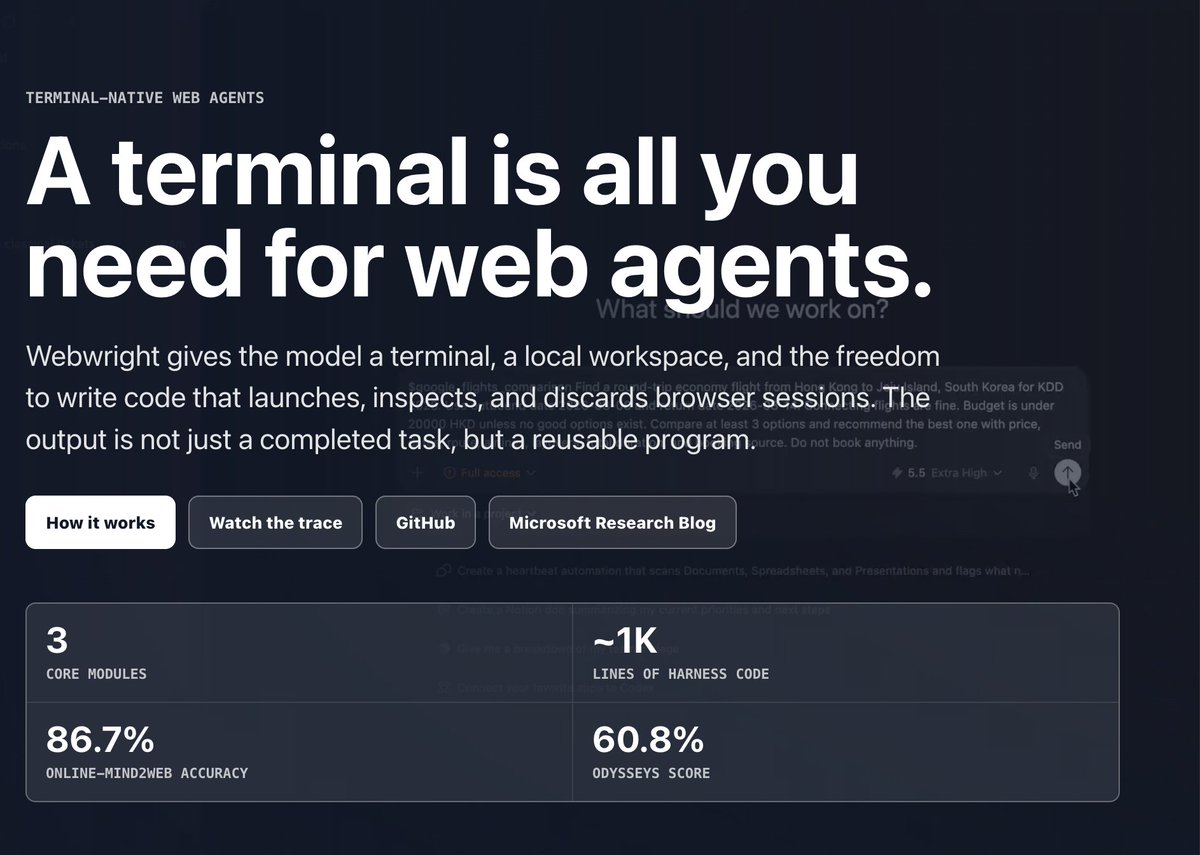
微软发布了终端原生 Web Agent 框架 Webwright,采用“代码即动作”设计,让 LLM 写 Playwright 脚本,性能表现优异,适用于多种后端平台。
入选理由:Webwright 使用 LLM 写 Playwright 脚本,将网页操作变成可运行的 Python 程序。
使用AI编写高质量代码虽然速度较慢,但通过多模型审查可以有效发现并修复大量错误,提升代码库的整体健康状况。
入选理由:AI可以有效发现代码中的大量错误。
异构智能是未来AI发展的关键范式,通过融合不同架构、规模和硬件的模型协同工作,提升复杂问题解决效率。
入选理由:当前AI发展正从同质化向异构化演进,如Mixture of Experts和多代理系统已初现端倪。
Gary Marcus 预测神经符号 AI 将在经济性、数据与能耗上显著优于 LLM,成为下一个盈利风口;而 LLM 除芯片外整体盈利有限。
入选理由:神经符号 AI 将在经济性、数据与能耗上大幅优于 LLM,有望带来巨额利润。
文章探讨了视频代理模型的未来趋势,指出其核心智能来源于大语言模型(LLMs),而非视频数据训练。作者Ethan He分享了构建前沿视频系统的关键技术挑战。
入选理由:视频代理模型的核心智能主要来自LLMs,而非视频数据训练。
ComfyUI新增支持OpenRouter模型,用户可直接在工作流中调用20+模型,提升灵活性。
入选理由:ComfyUI新增支持OpenRouter,允许直接调用20+模型。
Firecrawl 推出新工具,通过监控页面变化减少 90% 的 LLM 令牌消耗,提升 AI 数据处理效率。
入选理由:Firecrawl 的监控工具可减少 90% 的 LLM 令牌使用。
介绍了一个名为 Browser Use Terminal 的项目,结合 Rust 和 TUI 在浏览器中实现高效工作,利用 LLM 提供自由度。
入选理由:Browser Use Terminal 使用 Rust 和 TUI 在浏览器中实现高效工作。
LLM应用架构正分化为原子化技能包与组件化最佳实践两条路径,前者拆解个人能力供灵活调用,后者封装场景Workflow提升交付效率。
入选理由:向下原子化路径将人的能力拆解为针对具体任务的独立技能包,支持用户按需灵活调用。
提供Hermes桌面端的完整安装与配置指南:从官网下载安装包,安装约需10–15分钟并自动合并现有实例;首次启动在设置中连接远程后端(粘贴会话令牌与远程URL)、配置API密钥与消息应用;选择LLM模型(如DeepSeek V4 Pro),可启用视觉、网页提取与压缩等能力。
入选理由:安装包下载后自动完成Hermes代理完整安装,约需10–15分钟,会与现有实例合并,无需卸载。
作者认为AI代理在软件开发中的应用将是一大失误,因其无法真正编程,只能模拟代码分布。
入选理由:AI代理不能真正编程,仅能模仿代码分布,输出质量差且不易识别
Browser-use 团队开源了一款基于 Rust 的终端 TUI 工具,可通过自然语言控制浏览器操作,结合自研 LLM 引擎与 Chrome DevTools Protocol 实现自动化。
入选理由:该工具使用 Rust 编写,具备高性能和内存安全特性。
Cosmos 平台支持在客户或 Augment Code 环境部署,兼容任意 LLM,提供可观测性、可审计性和人工监督,助力规模化部署 AI 代理。
入选理由:Cosmos 可在客户本地或云端部署,保障数据主权与合规。
一款开源的 AI 日报工具,整合 23 个数据源并用 LLM 自动生成中文摘要。
入选理由:工具整合 GitHub Trending、X 推文等 23 个数据源
NVIDIA AI 发布 DynoSim 工具,用于模拟大语言模型部署中性能与成本的权衡,但仅提供链接未展开技术细节,实用价值有限。
入选理由:DynoSim 工具可模拟 LLM 部署中模型后端、张量并行形状、预填充/解码拆分等参数组合的帕累托前沿。
微调大模型以提升智能体技能、记忆管理、上下文工程、路由效率和知识库维护将成为关键趋势,受Karpathy关于LLM知识库的讨论启发。
入选理由:微调模型可显著改善智能体在记忆管理与上下文工程中的表现。
增加多智能体系统代理数量不一定提升性能,集体智能可能源于交互设计而非代理数量。
入选理由:增加代理数量对系统性能影响有限,需优化交互设计。