![[AINews] Thinking Machines' Native Interaction Models - TML-Interaction-Small 276B-A12B - advances SOTA Realtime Voice and kills standard VAD](https://substackcdn.com/image/fetch/$s_!LR03!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F02190942-3f50-4067-ae03-97c6b504b3a3_1490x1592.png)
[AINews] Thinking Machines的原生交互模型 - TML-Interaction-Small 276B-A12B - 推进SOTA实时语音并淘汰标准VAD
Latent Space2369 字 (约 10 分钟)
90
Thinking Machines发布TML-Interaction-Small 276B-A12B模型,采用2760亿参数MoE架构与120亿活跃参数,实现<200ms端到端延迟,显著超越GPT-4o和Gemini 3.1-Flash,在实时语音交互、时间对齐微回合与视觉主动性任务上达到SOTA,彻底淘汰传统VAD机制。
入选理由:TML-Interaction-Small为276B参数MoE模型,仅12B激活参数,实现<200ms端到端延迟。
精选文章#AI#语音交互#MoE#实时系统#模型架构中文
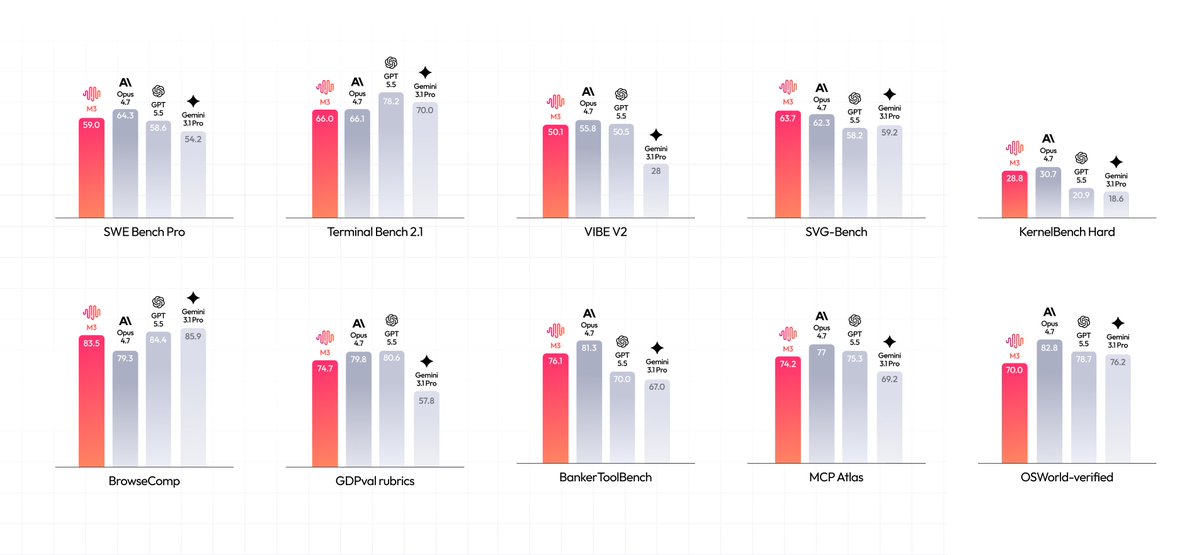

![[AINews] FrontierCode: Benchmarking for Code Quality over Slop](https://substackcdn.com/image/fetch/$s_!sdBk!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F0acd2026-8f85-4504-a5f3-6a0cd82d0b6a_2170x1604.png)