![[AINews] FrontierCode: Benchmarking for Code Quality over Slop](https://substackcdn.com/image/fetch/$s_!sdBk!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F0acd2026-8f85-4504-a5f3-6a0cd82d0b6a_2170x1604.png)
[AINews] FrontierCode: Benchmarking for Code Quality over Slop
Latent Space1922 字 (约 8 分钟)
85
FrontierCode 是一项新的代码质量评估基准,专注于衡量代码是否可合并,而非仅通过单元测试。
入选理由:FrontierCode 由开源维护者耗时 40 多小时构建,旨在评估代码是否可合并。
精选文章#FrontierCode#代码质量#AI 工程#基准测试英文
公司
别名:epochai
发布 FrontierCode 的研究团队。
已跟踪 7 条高相关材料
最近变化
2026-06-09 · FrontierCode 由开源维护者耗时 40 多小时构建,旨在评估代码是否可合并。
为什么值得关注
Epoch AI 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
[AINews] FrontierCode: Benchmarking for Code Quality over Slop
Latent Space · 8.5 分
FrontierCode 是一项新的代码质量评估基准,专注于衡量代码是否可合并,而非仅通过单元测试。
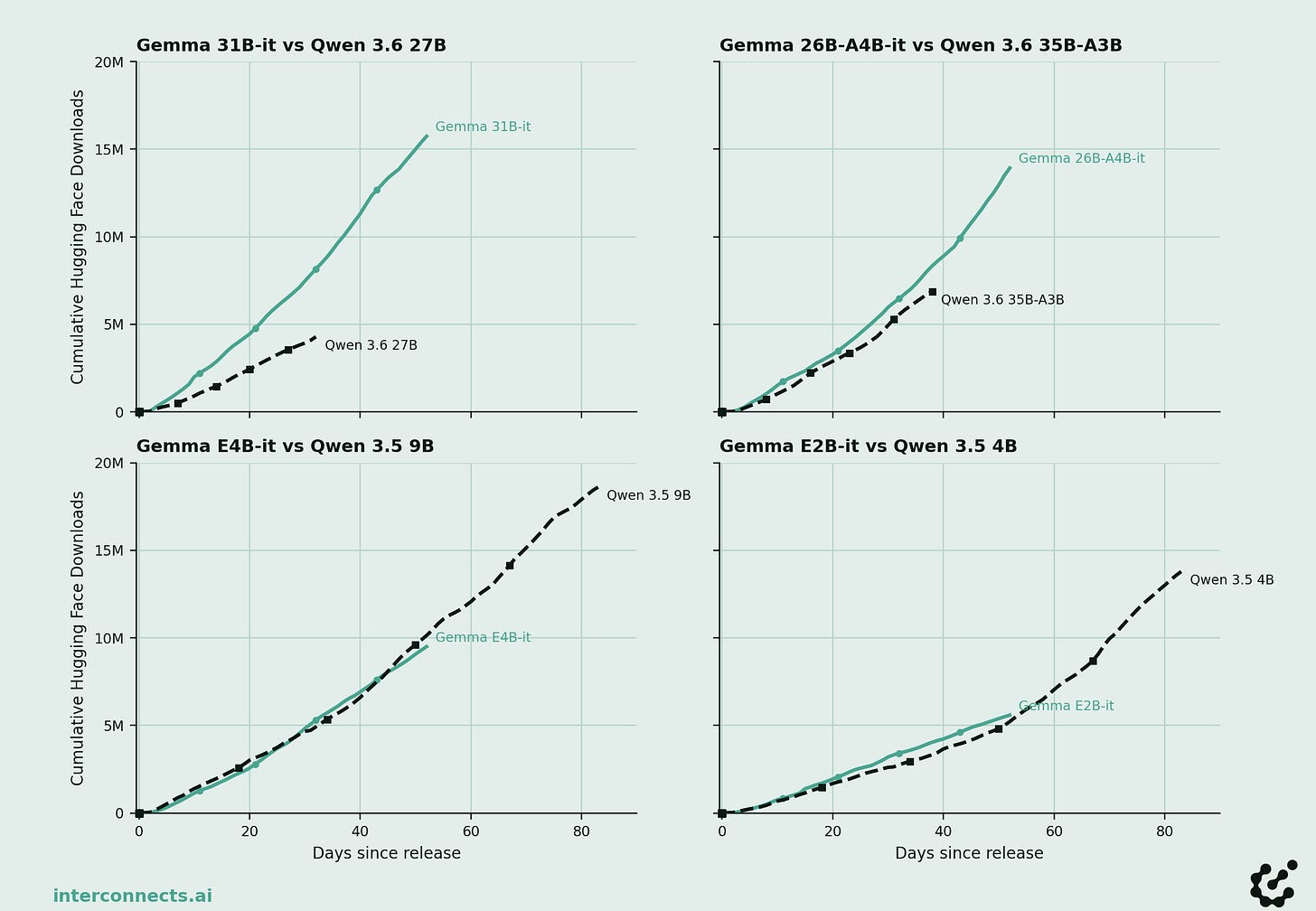
Latest open artifacts (#21): Open model bonanza! Gemma 4, DeepSeek V4, Kimi K2.6, MiMo 2.5, GLM-5.1 & others. On CAISI's V4 assessment.
Interconnects AI · 8.5 分
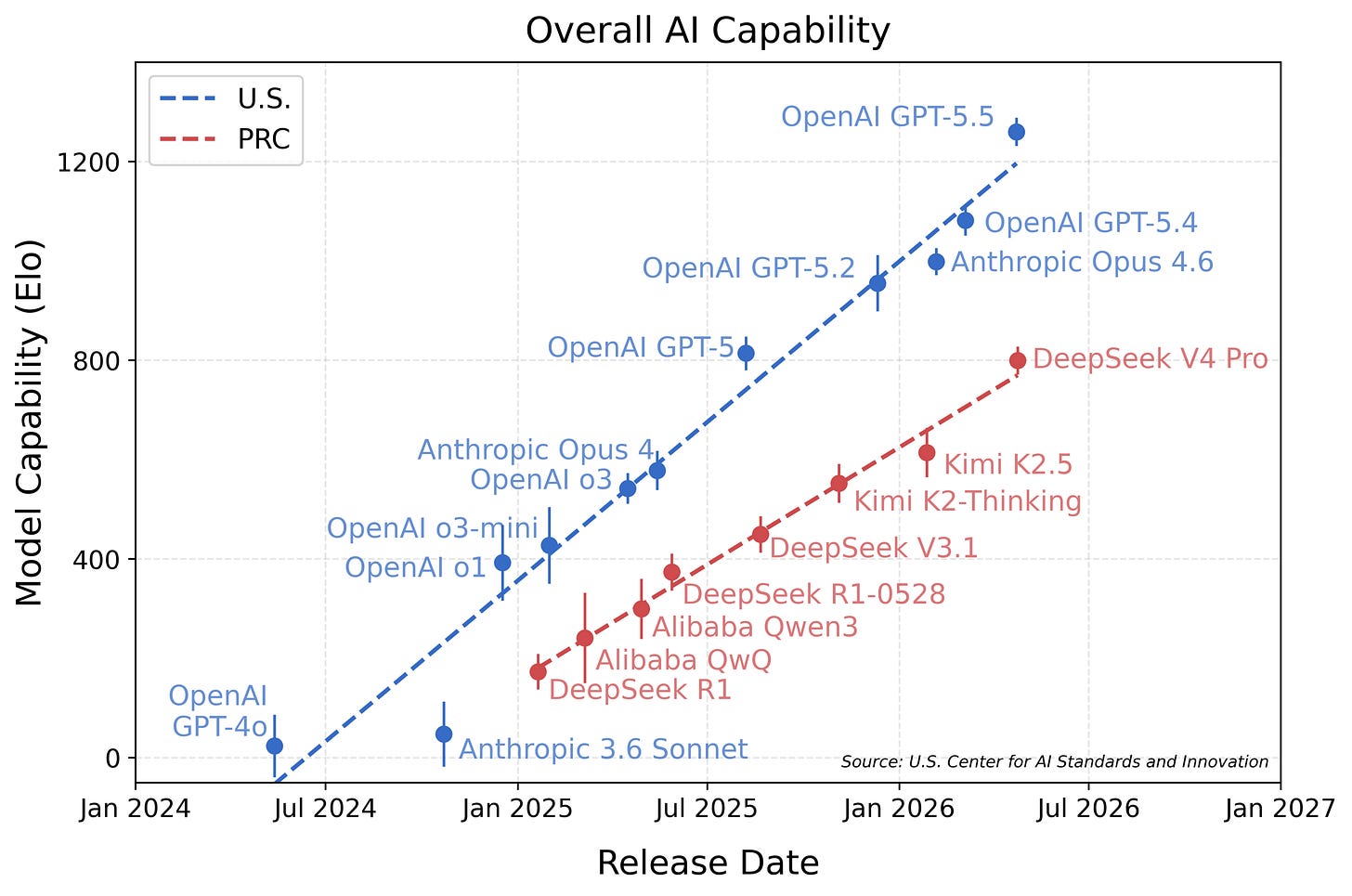
中国开源模型与美国前沿模型能力差距持续扩大,CAISI评估显示差距达3-7个月。
How open model ecosystems compound
Interconnects AI · 8.5 分
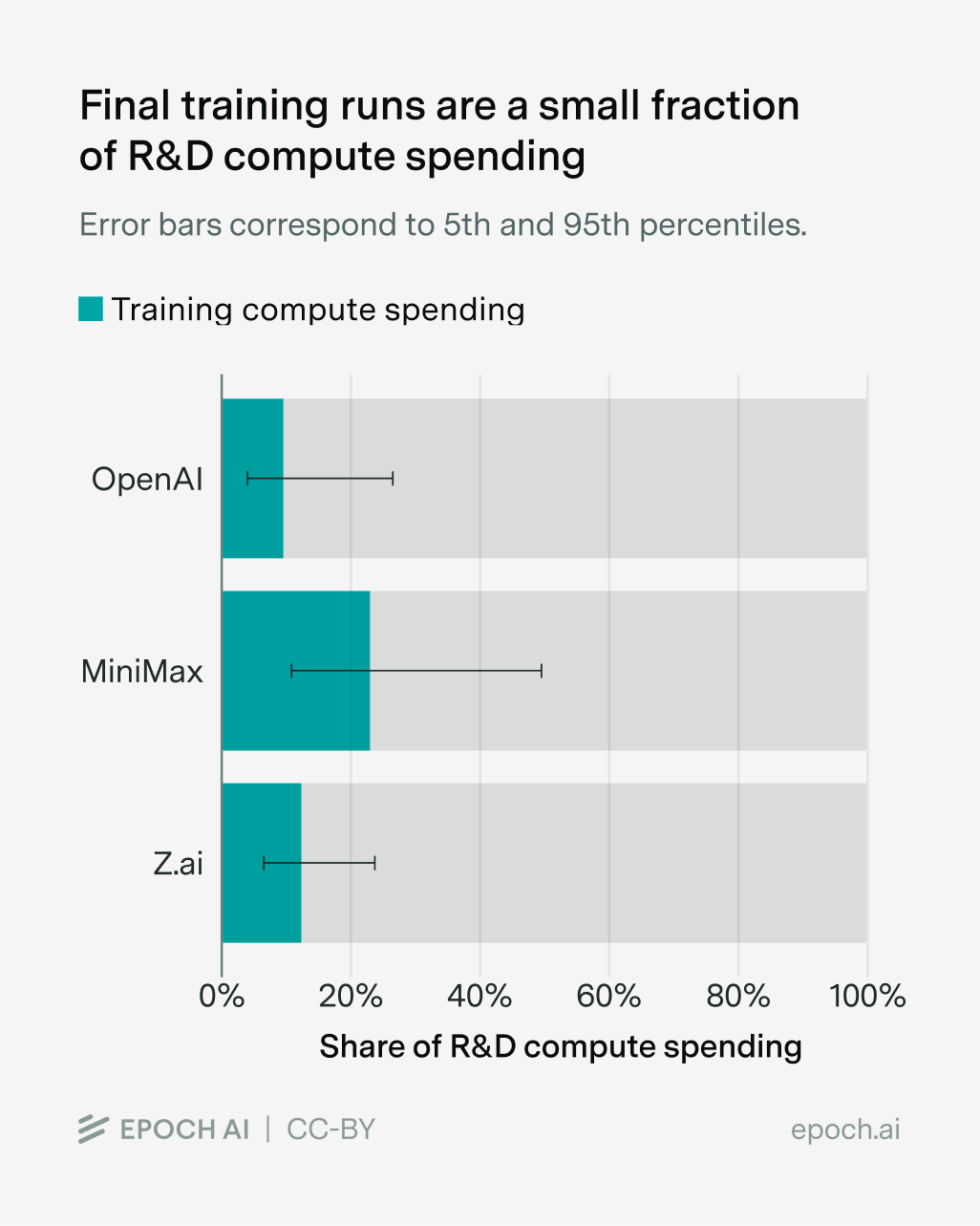
中国开放的AI生态系统通过减少重复研发计算成本,提高了模型开发的效率和可持续性。
已收录 7 条与 Epoch AI 相关的内容,按评分排序。
FrontierCode 是一项新的代码质量评估基准,专注于衡量代码是否可合并,而非仅通过单元测试。
入选理由:FrontierCode 由开源维护者耗时 40 多小时构建,旨在评估代码是否可合并。
中国开源模型与美国前沿模型能力差距持续扩大,CAISI评估显示差距达3-7个月。
入选理由:CAISI评估显示中国开源模型在多个基准测试中落后于美国模型,差距达3-7个月。
中国开放的AI生态系统通过减少重复研发计算成本,提高了模型开发的效率和可持续性。
入选理由:中国AI生态系统的开放性减少了重复的研发计算成本,使实验室能够持续更长时间。
当前 AI 评估(evals)存在严重缺陷,过度依赖客观指标易误导判断,但合理构建、解读并嵌入 agent 流程仍具关键价值。
入选理由:当前主流 eval(如 Epoch AI、OpenAI 的 benchmark)存在‘虚假精确性’,模型分数相近时实际能力差异显著。
作者预测2026年将是AI发展的关键一年,开放模型将面临更多挑战和机遇。
入选理由:2026年将是AI发展的关键一年,开放模型将面临更多挑战和机遇。
AI芯片中内存成本已占近三分之二,凸显存储性能瓶颈对整体算力效率的影响。
入选理由:AI芯片内存成本达63%,远超其他组件。
FrontierMath评测发现约三分之一题目存在致命错误,Epoch AI将发布修正后的数据集。
入选理由:FrontierMath Tiers 1-4中约33%的题目被标记为致命错误