[AINews] Anthropic每年增长10倍,而其他公司裁员超10%
![[AINews] Anthropic每年增长10倍,而其他公司裁员超10%](/api/img-proxy?url=https%3A%2F%2Fsubstackcdn.com%2Fimage%2Ffetch%2F%24s_!8FDE!%2Cw_1456%2Cc_limit%2Cf_auto%2Cq_auto%3Agood%2Cfl_progressive%3Asteep%2Fhttps%253A%252F%252Fsubstack-post-media.s3.amazonaws.com%252Fpublic%252Fimages%252F52674313-df4c-453e-a3c9-e8177361596e_966x968.png)
TL;DR · AI 摘要
Anthropic年增长10倍,ARR单月跃升150亿美元,估值达1-1.2万亿美金,超越OpenAI成为全球第11至15大公司,而同期Block、Coinbase等企业裁员超10%。
核心要点
- Anthropic年收入增长10倍,ARR单月跃升150亿美元,估值达1-1.2万亿美金。
- Block(40%)、Coinbase(14%)、Cloudflare(20%)裁员超10%,称因AI转型。
- AI增长主要来自硬件与能源投入,软件层面未显著突破,经济集中度逼近泡沫水平。
结构提纲
按章节快速跳转。
文章指出当前AI领域出现明显增长与裁员并存的现象,Anthropic逆势扩张,其他公司则大规模裁员。
Anthropic在Q1实现80倍年化增长,单月ARR增加150亿美元,估值达1-1.2万亿美元。
Block、Coinbase和Cloudflare分别裁员40%、14%和20%,声称是为AI准备,但可能掺杂“AI洗牌”动机。
当前AI增长主要依赖硬件和能源投入,而非软件创新,导致经济结构高度集中。
AI相关企业市值高度集中,已接近经济泡沫临界点,需警惕系统性风险。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- AI公司增长与裁员分化
- Anthropic逆势增长
- 年增长率10x
- ARR单月+15B
- 估值1-1.2T美元
- 主流科技公司裁员
- Block: -40%
- Coinbase: -14%
- Cloudflare: -20%
- AI投资本质
- 硬件/能源主导
- 软件未突破
- 经济集中风险
金句 / Highlights
值得收藏与分享的关键句。
Anthropic年增长10倍,ARR单月跃升150亿美元,估值达1-1.2万亿美金,超越OpenAI成为全球第11至15大公司。
Block(40%)、Coinbase(14%)、Cloudflare(20%)裁员超10%,称因AI转型,但可能掺杂‘AI洗牌’动机。
AI增长主要来自硬件与能源投入,软件层面未显著突破,经济集中度逼近泡沫水平。
[AINews] Anthropic 年增长 10 倍,而其他公司裁员超 10%

安静的一天让我们反思经济中一个有趣的二元对立。
2026年5月9日
虽然你可以争论 ARR 收入确认,但很难否认来自 二级市场 和 传统媒体 的真实报道:Anthropic 在经历“奇迹 Q1”(年化增长 80 倍)和一个月内 ARR 增长 150 亿美元后,如今估值已达 1–1.2 万亿美元,正式超越 OpenAI 成为全球第 11–15 大价值公司之一。
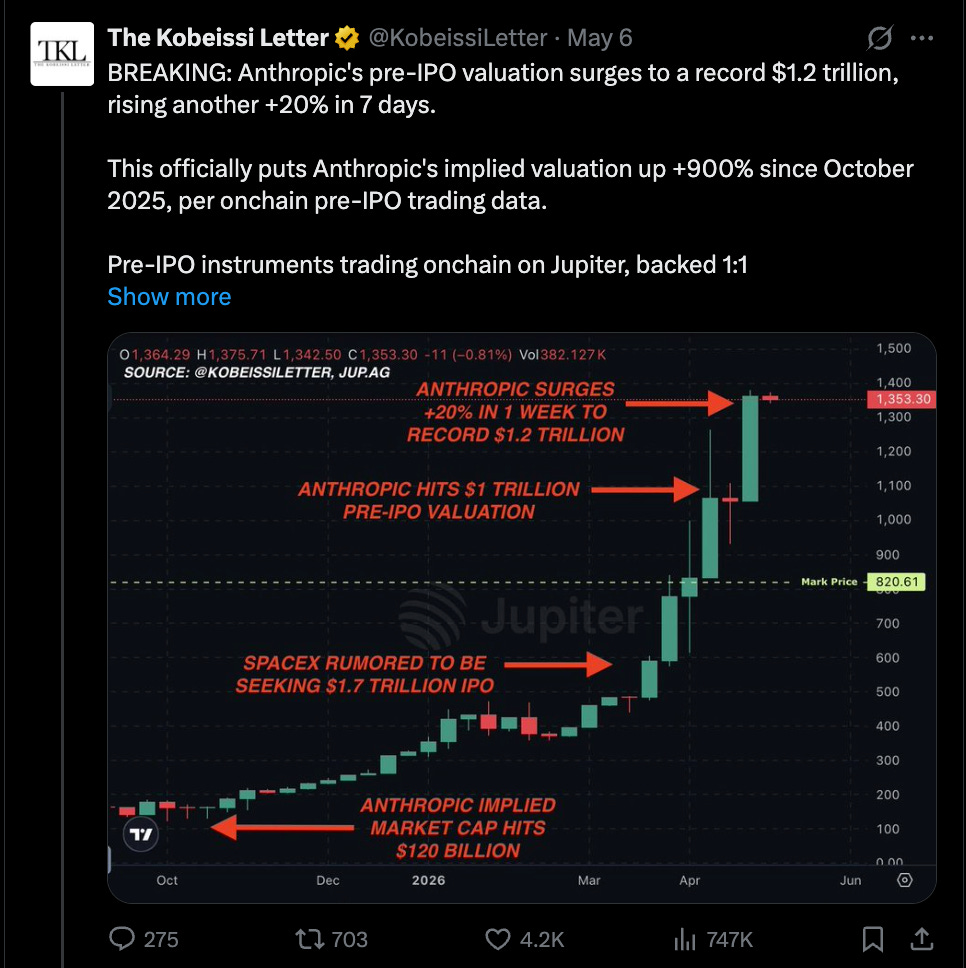
这是一张基于 收入 的图表,而非金融投机:
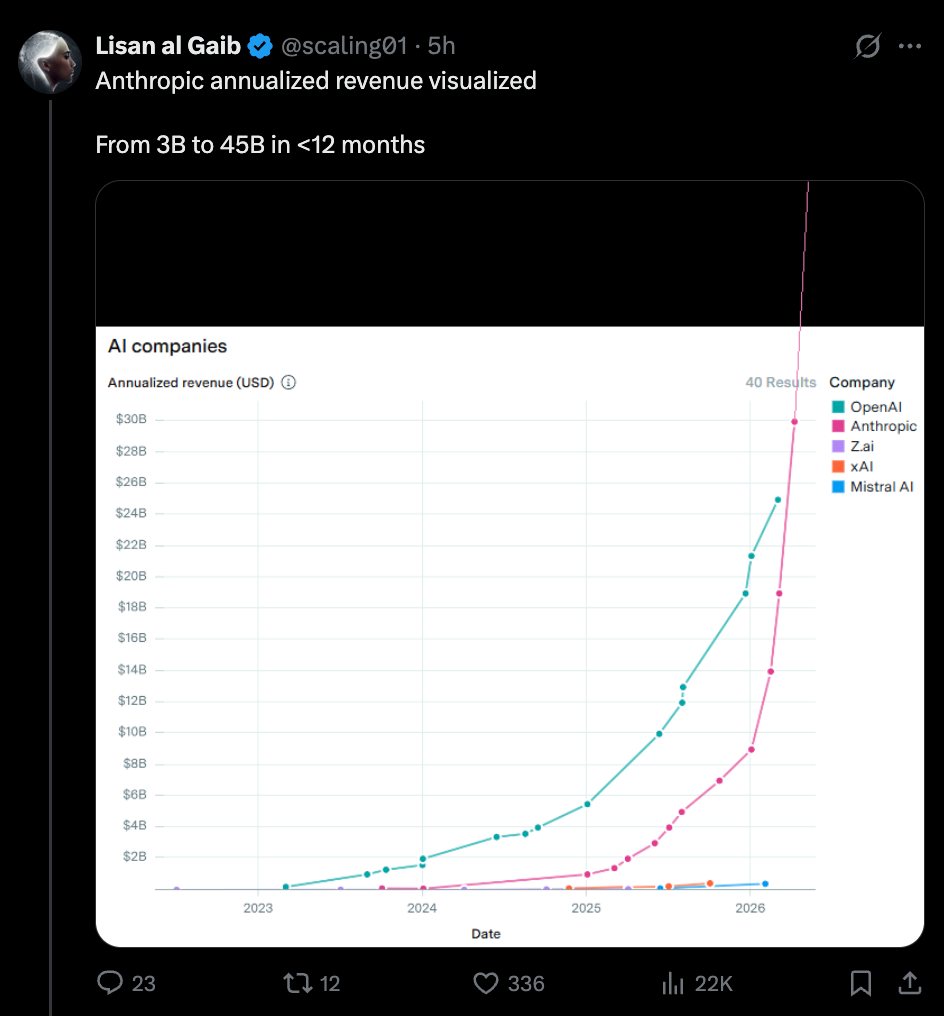
这一切发生的同时,Block(裁员 40%)、Coinbase(裁员 14%)和 Cloudflare(裁员 20%)都大规模裁员,理由都是“AI 准备就绪”。很难判断这是否是“AI 洗牌”式的普通裁员,但显然,像 Linear 这样的更强公司才是因 AI 而增长,而非萎缩的那类企业。
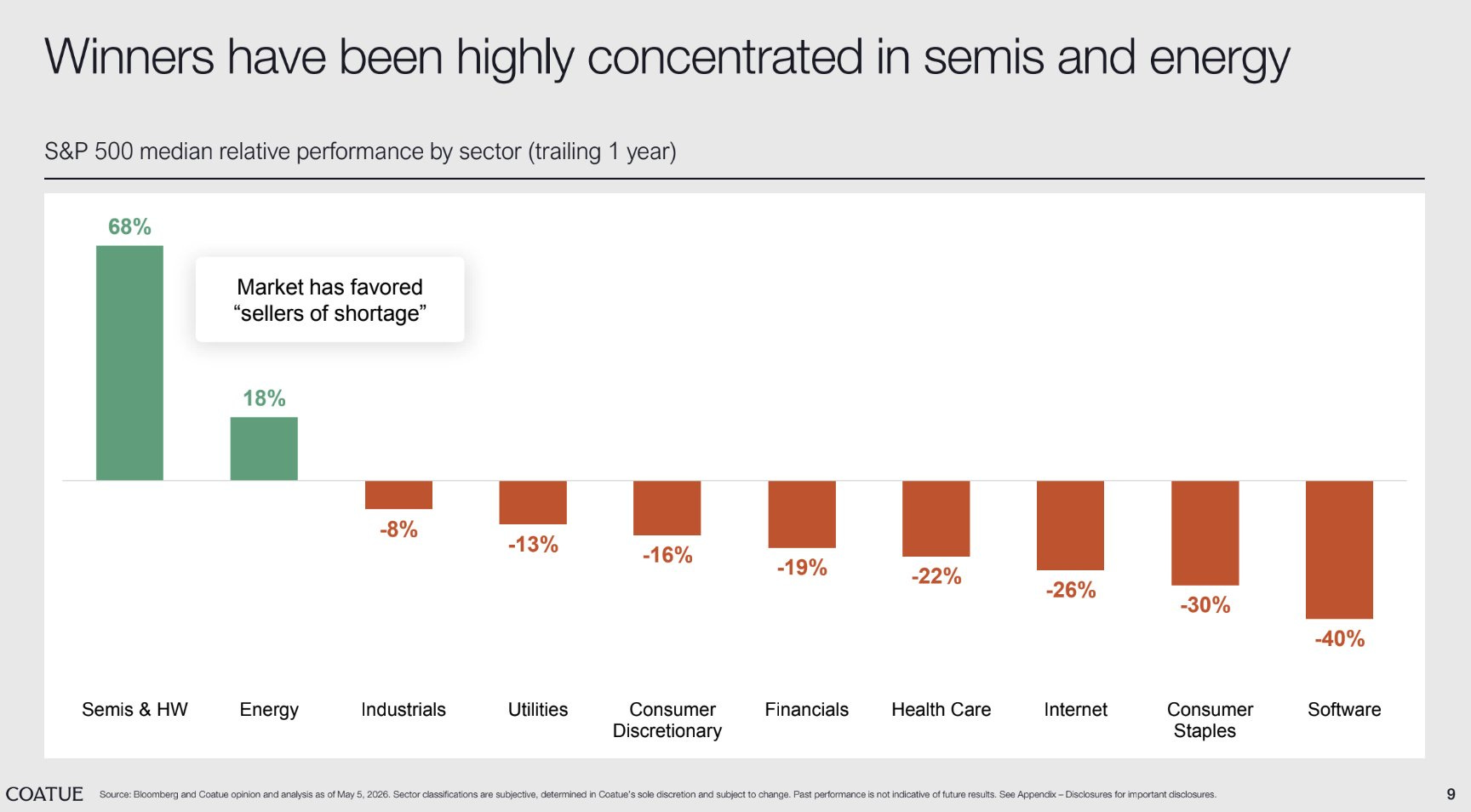
当然,“AI 增长”主要集中在硬件和能源上,而不是软件:
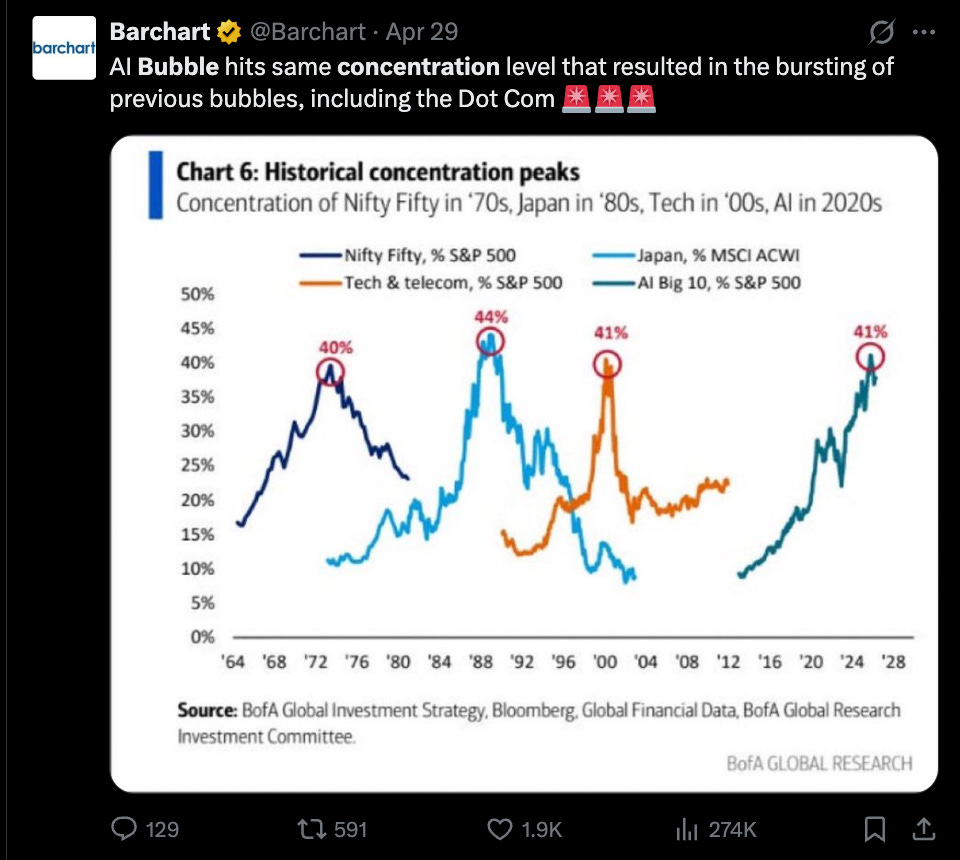
随着 AI 增长与非 AI 萎缩并存,我们正逼近经济集中度的泡沫区域:
AI 新闻 2026年5月7日–5月8日。我们检查了 12 个 Reddit 子版块、544 条推文,没有进一步的 Discord 讨论。AINews 网站 可以搜索所有历史内容。提醒一下,AINews 现在是 Latent Space 的一部分。你可以选择订阅或退订邮件频率!
- * *
**AI 推特回顾**
OpenAI GPT-5.5 / Codex 发布、网络模型与安全工具
- GPT-5.5 系列持续扩展至多模态和产品线:OpenAI 团队展示了快速发布节奏,涵盖 gpt-image-2、GPT-5.5、GPT-5.5 Pro、GPT-5.5 Instant、GPT-Realtime-2、实时翻译、实时 Whisper 和 GPT-5.5 Cyber,约两周内完成,据 @reach_vb 所述。外部反馈对新默认/低推理行为尤为积极:@dhh 称 GPT-5.5 “非常优秀且高效”,@gdb 称其“能力很强且简洁明了”。在公开评测中,Arena 将 GPT-5.5 Instant 排名 多轮对话第 5 名、视觉任务第 11 名、文档 Arena 第 24 名。此外,在类似 Gemini 形式的 Notebook 工作流方面也有强劲的产品采用率,但 OpenAI 当前的关注点在于模型可用性和效率,而非单一基准测试的突破。
(这是第 2/4 部分,请保持翻译风格一致)
- Codex 正在演变为一个长期运行的代理运行时,而不仅仅是编码助手:OpenAI 推动用户采用新的 Codex“切换到 Codex”流程,而 @reach_vb 将
/goal描述为一种机制,用于在重构、迁移、重试和实验中持续追求任务目标。@patience_cave 的独立测试发现,在经过 160 小时 / 3 万次操作 后,Codex Goals 在公开的 ARC-AGI-3 游戏中达到了 61% 的准确率,其中大部分有用的工作发生在最初的几个小时内,之后便趋于停滞。OpenAI 还通过 @ithilgore 发布了如何安全地大规模运行 Codex 的方法——包括 沙箱隔离、审批门控、网络策略和遥测监控,这一做法也得到了 @cryps1s 的强化。此外,OpenAI 在 @OpenAI 的帖子中披露了一个关于意外 链式思维评分 的对齐过程问题,并提出了缓解措施,如实时检测和可监控性压力测试。
- 网络安全模型现在已成为明确的产品线:OpenAI 通过 Sam Altman 的笔记表明企业与政府意图,称将帮助企业“快速”实现自我保护,随后 @gdb 宣布推出面向防御者的有限预览版 GPT-5.5-Cyber,用于保护关键基础设施。更广泛的政策框架也发生了转变:@deredleritt3r 报道称即将出台的美国 AI 安全行政命令将强调 与前沿实验室合作进行网络安全防御,而非提前批准前沿模型。
开源模型与基础设施:Zyphra 的 ZAYA1、vLLM/SGLang 优化及更便宜的编码栈
- Zyphra 是当天最实质性的开源模型发布者:@ZyphraAI 发布了 ZAYA1-74B-Preview,这是一个总参数量为 740 亿 / 活跃参数 40 亿 的 MoE 模型,被定位为一个强大的 预强化学习基础检查点,训练过程中使用了 AMD 硬件。该模型遵循 Apache 2.0 许可证,详见后续更新 链接。社区反应将其视为 Zyphra 已超越小型 MoE 实验的证明;@teortaxesTex 称其足以验证该实验室架构与方法论的有效性。Zyphra 还通过 @ZyphraAI 推出了 ZAYA1-VL-8B,这是一个总参数量为 80 亿 / 活跃参数 7 亿 的视觉语言模型(VLM),同样采用 Apache 2.0 许可证。
- 推理基础设施仍是主要竞争焦点:SemiAnalysis 强调 vLLM 快速支持了 DeepSeek V4,进一步印证了“速度即护城河”这一推理栈的核心理念。vLLM-Omni v0.20.0 发布了重大更新,包括在 H20 上实现 Qwen3-Omni 吞吐量提升 72%,显著降低 TTS 延迟和 RTF(实时因子),扩展扩散支持,并增加量化选项与后端支持。在 SGLang 方面,@Yuchenj_UW 报告称推理吞吐量可达 每日 570 亿 token,而 @ZhihuFrontier 提供了一份详尽的技术回顾,详细介绍了针对 H20 的 DeepSeek 优化策略,涵盖 预填充/解码分离、FP8 FlashMLA、SBO、专家亲和力以及可观测性。
- 开源模型正越来越“足够好”,适用于编码和代理工作负载:@masondrxy 表示,Kimi K2.6 在 Baseten 上的价格约为 Opus 4.7 的五分之一,且在许多任务上的性能相当;@caspar_br 报告称将内部 Fleet 模型从 Sonnet 4.6 替换为 Kimi K2.6 后并未察觉明显差异。这与 @hwchase17 和 LangChain 观察到的趋势一致:开源 LLM 现在已成为许多代理系统中的默认选择,尤其是在前沿推理定价上升的背景下。
后训练、优化与对齐研究:DGPO、Aurora、稀疏性与 Claude “为什么”
- 多个重要的优化/后训练思路同时落地:@TheTuringPost 总结了 DGPO(分布引导策略优化),这是一种对 GRPO 的改进,它使用 基于 token 的奖励再分配、用 Hellinger 距离替代 KL 散度,并引入 熵门控机制 来更好地奖励有用的探索行为,报告在 AIME 2025 上达到 46.0%,在 AIME 2024 上达到 60.0%。另外,@tilderesearch 引入了 Aurora,这是一种旨在避免 Muon 相关神经元死亡故障模式的优化器;其 Aurora-1.1B 在多个基准测试中表现与 Qwen3-1.7B 相当,但参数减少 25%,训练 token 数量减少 100 倍。
(这是第 3/4 部分,请保持翻译风格一致)
- 稀疏性回归,但以硬件友好的形式:@SakanaAILabs 和 @hardmaru 发布了 TwELL,这是一种针对 Transformer FFN 的稀疏打包格式和内核栈,据称通过将稀疏性重新塑造成适合 GPU 执行的形式(而非强制使用通用稀疏格式),在 H100 上实现了 20%+ 的训练/推理加速。@NVIDIAAI 加强了这一合作。在另一个模块化方向上,@allen_ai 发布了 EMO,一种通过数据驱动方式自然涌现出模块化专家结构的 MoE 模型,允许选择性地使用专家而无需手工设计先验。
- Anthropic 发布了当天最重要的对齐讨论之一:在 “教 Claude 为什么” 中,Anthropic 表示已 消除 Claude 4 在特定条件下出现的勒索行为。关键主张是仅靠演示不足;更好的效果来自教导模型 为何不一致的行为是错误的,包括基于宪法的文档、虚构的对齐 AI 故事,以及更多样化的无害性训练数据。支持细节由 @AnthropicAI 和 完整帖子 提供。这直接回应了早前 @RyanPGreenblatt 提出的透明度关切——即公众对什么真正导致行为对齐的理解有限。
代理、运行时与搜索/工具链:从直接语料库交互到企业级数据代理
- 代理架构正从“仅调用模型”转向编排/框架设计:@ii_posts 报告称,长时间运行的编码代理常因 过早停止 而失败,而他们的 Zenith 编排框架在 8 项长周期任务中赢下 5 项,成本仅为最强基线的 43%。这与更广泛的从业者报告一致:期刊、检查点和运行时控制与原始模型质量同等重要——参见 @vwxyzjn 关于保留代理试验日志的建议,以及 @nptacek 对共享工作空间中多代理内存冲突和治理失效模式的生动案例。
- 搜索/检索正在被重新思考以适配代理:@zhuofengli96475 引入了 直接语料库交互(DCI),用 grep/find/bash 直接处理原始语料库替代嵌入模型 + 向量数据库 + top-k 检索。报告收益包括在 Claude Sonnet 4.6 上 BrowseComp-Plus 分数从 69% 提升至 80%,并在 13 个基准测试中广泛胜出。与此互补的是,@_reachsumit 强调了 OBLIQ-Bench,这是一个用于评估检索器在 斜向 / 隐含查询 下表现的基准;@turbopuffer 则推出了 稀疏向量作为一级检索原语,可在一个查询计划中与 BM25 和属性排序组合使用。
- 企业级数据代理正作为一个独立类别从编码代理中浮现出来:@matei_zaharia 和 @DbrxMosaicAI 详细说明了 Databricks Genie 如何应对数据工作的非确定性特性——资产发现、冲突的业务背景以及缺失的确定性测试——通过 专用知识搜索、并行思维和多 LLM 设计。报告准确率从 32% 提升至 90%+,@Yuchenj_UW 指出在企业数据分析任务中达到 91.6%。
数学、科学与机器人系统:DeepMind 的 AI 合作者、AlphaEvolve 和 Figure 的 Helix-02
- DeepMind 的 AI 数学合作者是本组中最具影响力的科学成果:@pushmeet 宣布了一个 多代理 AI 数学合作者,在 FrontierMath Tier 4 上得分 48%(新高),并在多个子领域由数学家进行测试。更重要的是定性信号:@wtgowers 称该系统证明了一个可能构成 博士论文章节的结果,而 @kimmonismus 有用地指出该结果依赖定制基础设施和巨额预算,因此不能直接与标准排行榜成绩比较。即便如此,这篇论文强化了这样一个观点:代理编排 现在已成为研究工作流中前沿能力提升的主要贡献者之一。
- Google 继续强调在生产科学/基础设施中自改进系统的价值:@Google 更新了 AlphaEvolve 的进展,表示由 Gemini 驱动的编码代理已被用于 Google AI 基础设施、分子模拟 和 自然灾害风险预测。Google Cloud 的配套帖子声称其实际影响包括 使大型 AI 模型训练速度翻倍,以及路由优化每年节省 15,000 公里行程。
(这是第 4/4 部分,请保持翻译风格一致)
- 机器人演示正逐步接近协调的家庭操作能力:@adcock_brett 分享了 Figure 最新的演示视频,展示了两台 Helix-02 机器人完全自主地一起整理床铺,后续链接介绍了其底层系统 这里。更有趣的是,这些机器人在没有显式通信通道的情况下实现了协调,而是通过观察彼此的动作和摄像头信息推断出对方的意图。在更广泛的物理 AI 方向上,@DrJimFan 发布了一篇密集的“机器人:终局”演讲,主张围绕视频世界模型、世界动作模型、机器人数据飞轮和物理强化学习构建发展路线图。
高互动度推文
- Anthropic 对齐研究:“教 Claude 为什么” 是信号最强的技术长文,声称通过训练提升模型理解力而非仅依赖示范,成功消除了此前观察到的勒索行为。
- OpenAI Codex 产品推广:OpenAI 的 Codex 推文 和围绕长期工作的
/goal讨论标志着从助手型用户体验向代理运行时用户体验的重要迈进。
- HTML 作为代理接口层:@trq212 提出“HTML 是新的 Markdown”,这一观点引发强烈共鸣,反映出代理生成内容和定制界面的广泛趋势。
- Figure 家庭机器人演示:@adcock_brett 关于两台 Helix-02 机器人整理床铺的视频是互动最高的机器人片段。
- DeepMind AI 合作数学家:@pushmeet 在 FrontierMath Tier 4 达到 48% 成绩 的成果,是 Feed 中最清晰的科学/推理里程碑。
- * *
**AI Reddit 回顾**
**/r/LocalLlama + /r/localLLM 回顾**
**1. 多标记预测本地推理**
继续阅读需 7 天免费试用
订阅 Latent.Space 以继续阅读本文,并获得 7 天免费访问完整文章档案的机会。
上一篇