EP215: AI代理的解剖结构

TL;DR · AI 摘要
AI代理的核心组件包括大脑、规划、工具、记忆和循环,其设计需考虑安全限制。
核心要点
- AI代理通过LLM选择动作并执行,形成闭环处理任务。
- 记忆机制分为短期(上下文窗口)和长期(向量存储等),确保信息延续性。
- 安全防护如沙箱和输出验证是防止自主性失控的关键。
结构提纲
按章节快速跳转。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- AI Agent Anatomy
- Core Components
- Brain (LLM)
- Planning
- Tools
- Memory
- Loop
- Safety Measures
- Sandboxing
- Human Checks
- Token Limits
- Output Validation
金句 / Highlights
值得收藏与分享的关键句。
AI代理可以被看作是一个简单的While循环。
从聊天机器人到代理的重大转变:模型不再只是生成文本,而是做出选择。
当窗口填满时,代理会总结旧的回合并将其摘要带入后续处理。
标题:EP215:AI 智能体的架构剖析
文章来源:https://blog.bytebytego.com/p/ep215-the-anatomy-of-an-ai-agent
发布时间:2026-05-16T15:31:01+00:00
Markdown 内容:
6月10日,GitLab Transcend 大会将在伦敦进行直播,议程专为您这样的实践者打造。您将体验到充满键盘操作时刻的议程,包括 Duo Agent 平台的现场演示、同行分享的智能 AI 应用案例,以及由高级开发者布道师 Colleen Lake 主持的《开发者秀》直播。
GitLab Transcend 将于 6 月 10 日在伦敦进行直播,亚太区和美洲地区可在 6 月 11 日观看区域回放。
立即注册。免费参与,完全虚拟化。来体验智能编排,现在更添情境感知。
本周系统设计复习:
- 提示注入,清晰解析(YouTube 视频)
- AI 智能体的架构剖析
- REST vs GraphQL vs gRPC
- 如果 Claude Code 是一个汉堡...
- git fetch vs git pull vs git pull —rebase
AI 智能体可以看作一个简单的 While 循环。
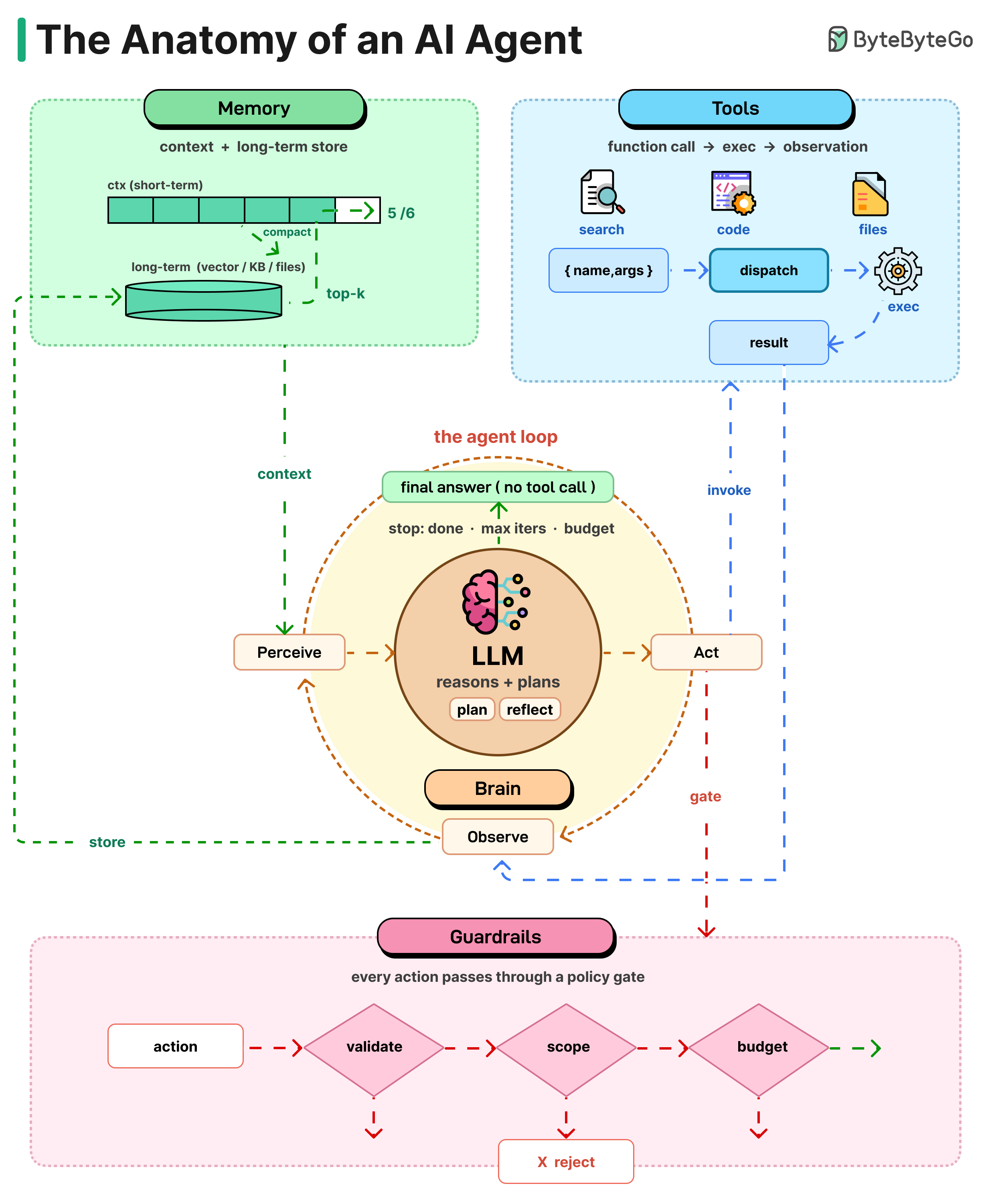
它使用大语言模型(LLM)选择动作,执行该动作,评估结果,并重复这个过程,直到任务完成。让我们仔细看看每个组成部分:
- 大脑:LLM 是核心。它读取当前状况,思考并决定下一步做什么。从聊天机器人到智能体的重大转变在于:模型不再仅仅是生成文本,而是在做出选择。
- 规划:复杂任务需要多步骤处理。智能体使用思维链(逐步推理)、思维树(尝试选项并选择最佳)或反思(从错误中学习并重试)等方法分解任务。规划将模糊的目标转化为清晰的行动。
- 工具:没有工具的 LLM 就像罐子里的大脑。工具是模型可以调用的函数,如网络搜索、代码执行、API、文件或浏览器(通常使用 MCP 标准)。模型请求工具,系统运行它,然后返回结果。
- 记忆:没有记忆,每一轮都从零开始。短期记忆是上下文窗口。长期记忆存储在向量数据库、文件和知识库中。当窗口填满时,智能体会总结旧轮次的内容并携带摘要前进。
- 循环:所有四个部分在一个周期中协同工作。智能体查看当前状态,决定做什么,使用工具,查看结果,然后重复。这个过程持续进行,直到给出最终答案。
- 防护措施:虽然严格来说不属于架构部分,但非常重要。沙盒、人工检查、令牌限制、输出验证和范围限制可以防止自主性变成代价高昂的混乱。你给予的自主性越多,这些措施就越重要。
轮到你了:当你构建智能体时,这五个部分中哪一个最需要投入精力来完善?
REST、GraphQL 和 gRPC 是三种不同的 API 设计方法。每种方法在简单性、性能和灵活性之间提供了不同的权衡。
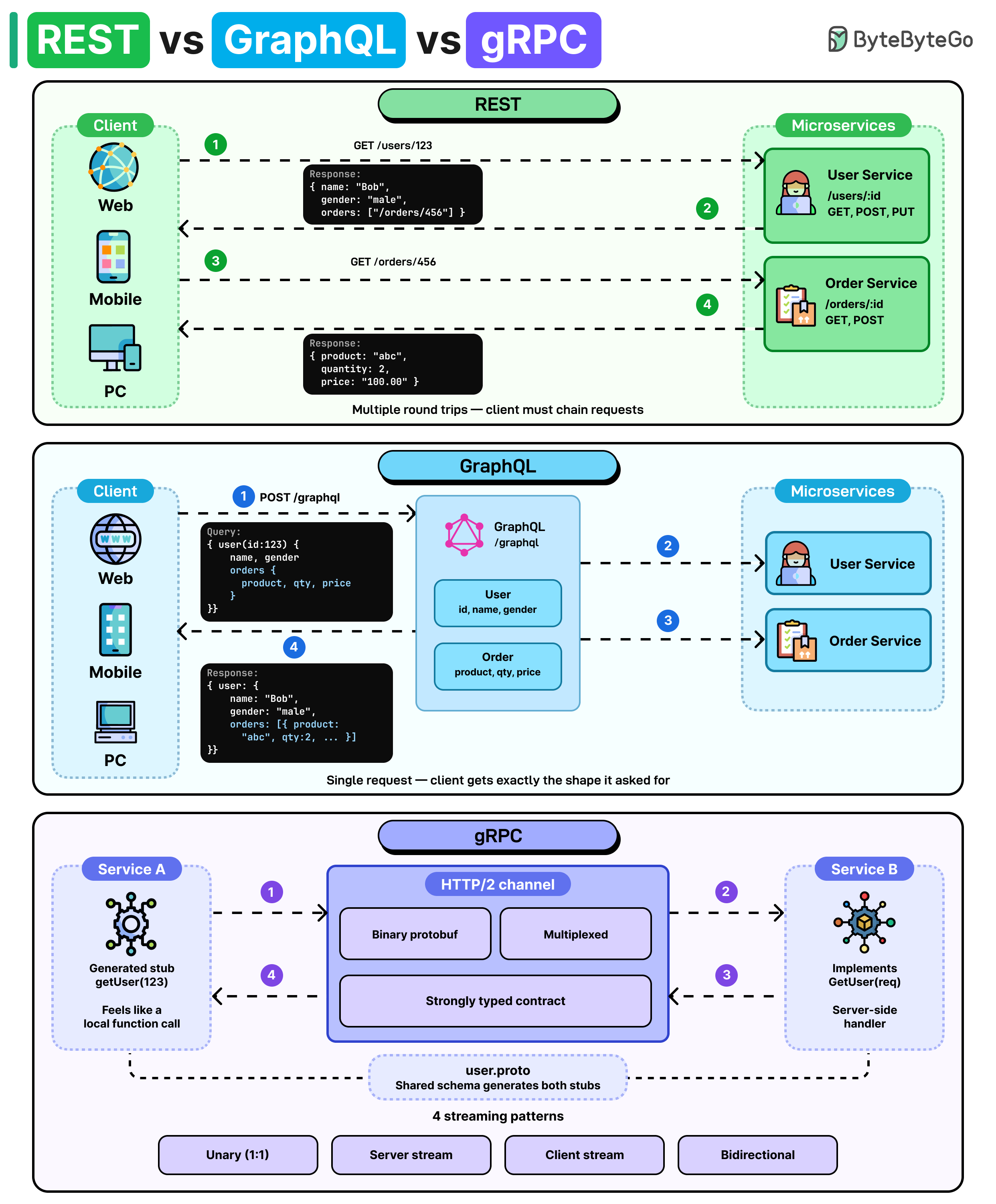
- REST:每个 URL 代表一个资源,你使用标准的 HTTP 动词(GET、POST、PUT、DELETE)对其进行操作。简单且通用,但通常需要多次请求来组装相关数据。
权衡:易于学习、缓存友好,并且适用于任何 HTTP 客户端,但往往会导致数据过度获取或获取不足,随着端点的增多,客户端请求频繁且容易出现版本漂移。
- GraphQL:客户端发送一个查询,精确描述所需的数据结构,服务器通过单一端点返回恰好符合要求的数据。
权衡:消除了过度获取,让前端可以独立演进,但将复杂性转移到了服务器(解析器、N+1 查询),使缓存复杂化,并且使速率限制和查询成本分析更加困难。
- gRPC:服务通过强类型的方法调用,在 HTTP/2 上使用紧凑的二进制(protobuf)编码进行通信,使其成为具有内置流支持、快速、低延迟的服务间通信的理想选择。
权衡:通过 protobuf 模式实现了卓越的性能和严格的契约,但二进制格式不是人类可读的,浏览器支持需要代理(gRPC-Web),并且调试比使用纯 JSON over HTTP 更困难。
经验法则:REST 适用于公共 API 和广泛的兼容性,GraphQL 适用于客户端需要灵活、聚合视图的场景,gRPC 适用于内部微服务,其中延迟和吞吐量最为重要。
在每次模型调用之前,Claude Code 会从 9 个不同的来源组装上下文窗口。
可以把它想象成一个汉堡,每一层都添加了不同的东西。

- 系统提示:定义 Claude 的角色、行为和语气。这是基础设置。
- 环境信息:Git 状态、分支信息和当前日期。通过 getSystemContext() 获取。
- CLAUDE.md:四级指令层次结构:托管 → 用户 → 项目 → 本地。纯文本 Markdown 格式,用户可以阅读、编辑和版本控制模型看到的所有内容。
- 自动记忆:异步预取上下文相关的记忆条目。LLM 扫描记忆文件头并按需提供最多 5 个相关文件。
- 路径范围规则:当代理读取文件时延迟加载的条件规则。
- 工具元数据:技能描述、MCP 工具名称和延迟工具定义。
- 对话历史:跨迭代持续传递。
- 工具结果:文件读取、命令输出和子代理摘要。
- 紧凑摘要:当历史记录过长时,旧片段会被模型生成的摘要替换。
整个设计将上下文视为稀缺资源。
轮到你了:在使用 Claude Code 时,这 9 层中你最常调整哪一层?
大多数 Git 错误并非源于糟糕的提交。当你的分支落后、有本地提交,现在需要引入上游变更时,git fetch、git pull 和 git pull --rebase 之间的区别就变得至关重要。
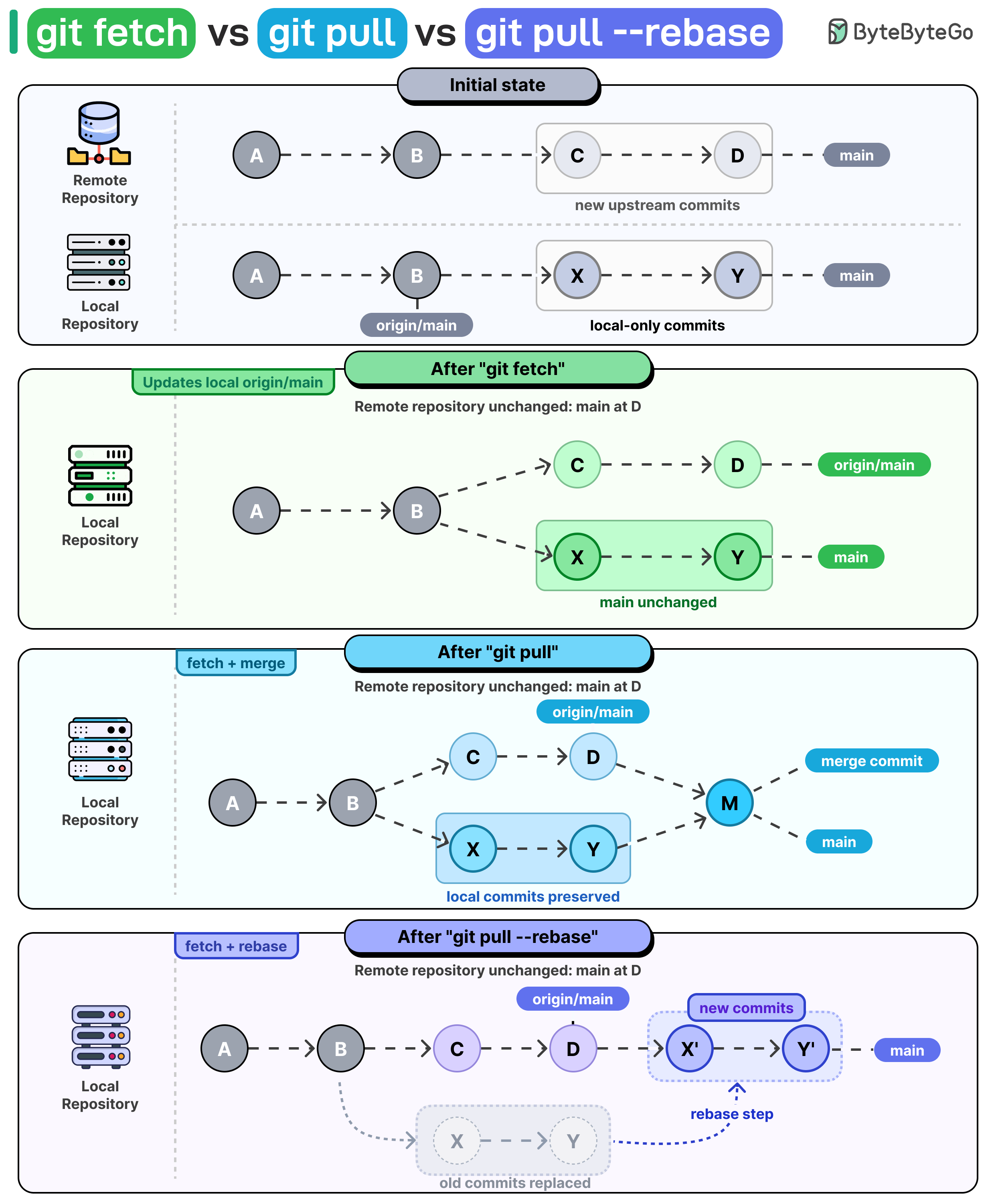
git fetch 会下载远程变更并更新 origin/main。你的本地 main 分支不会移动。工作目录中的任何内容都不会改变。这使得 fetch 成为最安全的选择,当你想在集成任何内容之前检查上游发生了什么变化时使用。
git pull 更进一步。它先执行 fetch,然后将上游分支合并到当前分支。你的本地提交保持不变,Git 会添加一个合并提交来连接两个历史记录。
git pull --rebase 是最整洁的方式。它从 fetch 开始,但不是合并,而是在更新后的上游分支顶部重新应用你的本地提交。结果是线性的历史记录,没有合并提交。
当你想在决定任何操作之前查看远程内容时使用 fetch。当你在自己的分支上工作且不介意日志中出现合并提交时使用 pull。当你在打开 PR 之前清理功能分支,并希望历史记录清晰可读时使用 rebase。
轮到你了:当主分支已经领先 10 个提交时,你会如何处理一个已经存在几天的功能分支?