Gemma 4 12B:开发者指南
Google Developers Blog1171 字 (约 5 分钟)
92
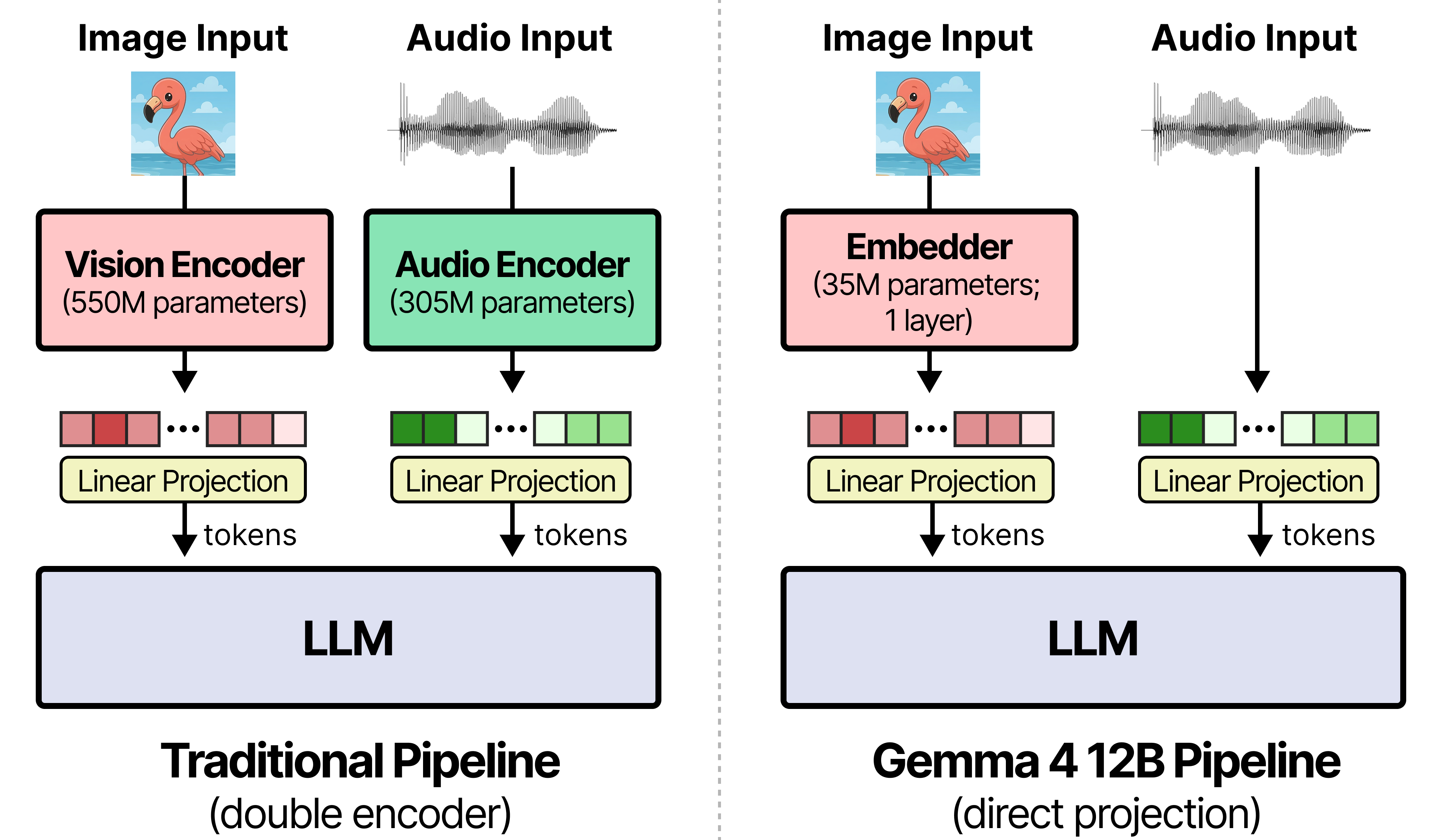
Gemma 4 12B采用无编码器多模态架构,可在16GB显存设备上本地运行并原生支持音频输入。该模型通过移除独立视觉与音频编码器显著降低延迟,配合专用MTP模型提升推理速度,是首个支持macOS桌面端全离线交互的中型多模态模型。
入选理由:Gemma 4 12B移除独立编码器,视觉仅用35M参数嵌入层,音频直接线性投影至LLM输入空间
精选文章#Gemma 4#多模态大模型#无编码器架构#本地AI#Google英文