Claude Fable 5省钱秘诀来了:调成Low档比Opus更便宜
量子位2414 字 (约 10 分钟)
85
Claude Fable 5在低档位下表现优于Opus 4.8,且在复杂任务中更省成本。
入选理由:Fable 5低档位下表现优于Opus 4.8
精选文章#Claude#AI模型#成本优化中文
概念
别名:SWE-bench
用于评估模型编程能力的基准测试。
已跟踪 9 条高相关材料
最近变化
2026-06-11 · Fable 5低档位下表现优于Opus 4.8
为什么值得关注
SWE-bench Pro 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
Claude Fable 5省钱秘诀来了:调成Low档比Opus更便宜
量子位 · 8.5 分
Claude Fable 5在低档位下表现优于Opus 4.8,且在复杂任务中更省成本。
Claude Fable 5 thinks document parsing is beneath it It is absolutely crushing on all reasoning-int...
Jerry Liu(@jerryjliu0) · 8.5 分
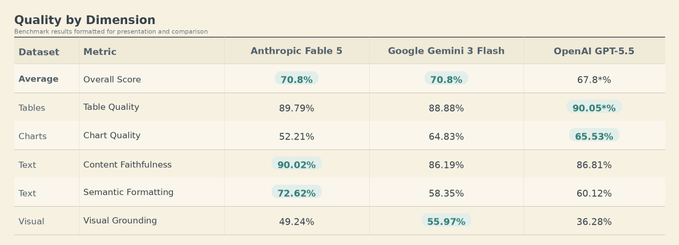
Claude Fable 5 在推理任务上表现卓越,但在文档解析任务上与 Gemini 3 Flash 相当,且成本高 10-15 倍。
There are no shortcuts to the frontier. Disciplined, patient, meticulous attention to detail is crit...
Mustafa Suleyman(@mustafasuleyman) · 8.5 分
微软发布MAI-Thinking-1等7款模型,其中推理模型SWE-Bench Pro达53%媲美Opus 4.6,转录模型MAI-Transcribe-1.5支持43种语言且速度提升5倍。
已收录 9 条与 SWE-bench Pro 相关的内容,按评分排序。
Claude Fable 5在低档位下表现优于Opus 4.8,且在复杂任务中更省成本。
入选理由:Fable 5低档位下表现优于Opus 4.8
Claude Fable 5 在推理任务上表现卓越,但在文档解析任务上与 Gemini 3 Flash 相当,且成本高 10-15 倍。
入选理由:Claude Fable 5 在 SWE-Bench Pro 等推理任务中表现优异。
微软发布MAI-Thinking-1等7款模型,其中推理模型SWE-Bench Pro达53%媲美Opus 4.6,转录模型MAI-Transcribe-1.5支持43种语言且速度提升5倍。
入选理由:MAI-Thinking-1在SWE-Bench Pro得分53%,与Opus 4.6并列顶尖编码推理水平。
MiniMax 推出 M3 开源模型,首次融合编码、代理与长上下文能力,在 SWE-Bench Pro 等基准上达 59%+,支持 1M 上下文窗口,推动开源大模型向多能型前沿迈进。
入选理由:MiniMax M3 在 SWE-Bench Pro 基准测试中取得 59.0% 正确率,领先多数开源模型。
Mustafa Suleyman 宣布推出七款全新 MAI 模型,包括 MAI-Thinking-1、MAI-Image-2.5 和 MAI-Code-1-Flash,这些模型在推理、图像编辑和代码生成等领域表现出色。
入选理由:MAI-Thinking-1 是一款拥有 35B 参数的 MoE 模型,在 AIME 2025 上达到 97% 的准确率,优于 Sonnet 4.6。
MiniMax M3 是首个开源权重模型,同时支持文本、视觉、文档和代码任务,在 SWE-Bench Pro 等基准测试中表现优异,上下文长度达 1M tokens。
入选理由:MiniMax M3 在 SWE-Bench Pro 达到 59.0%,Terminal Bench 2.1 达 66.0%,是当前开源模型中编程能力最强之一。
MiniMax M3 模型已通过 Ollama Cloud 发布,支持 US 部署与零数据保留,专为编码和代理任务设计,在 SWE-Bench Pro 基准中达 59%+ 正确率,结合稀疏注意力实现 1M 上下文长度。
入选理由:M3 在 SWE-Bench Pro 基准中取得 59.0% 正确率,优于多数开源模型。
Augment Code 发布的基准测试显示,其 AI 编程助手 Auggie 在使用 Opus 4.7 模型时,以 67.4% 的通过率略高于 Claude Code 的 66.3%,同时成本降低约 33%,这主要归功于其 Context Engine 语义索引技术实现的精准检索和 token 效率优化。
入选理由:Auggie 在 Terminal Bench 2.0 上以 67.4% vs 66.3% 的通过率略胜 Claude Code,同时 token 使用量减少 32%,成本降低 33%
Ollama 推出新一代旗舰模型 GLM-5.1,代码生成能力显著提升。
入选理由:GLM-5.1 是 Ollama 的新一代旗舰模型。