当AI构建自身:我们迈向递归自我改进的进展
Hacker News Best5602 字 (约 23 分钟)
92
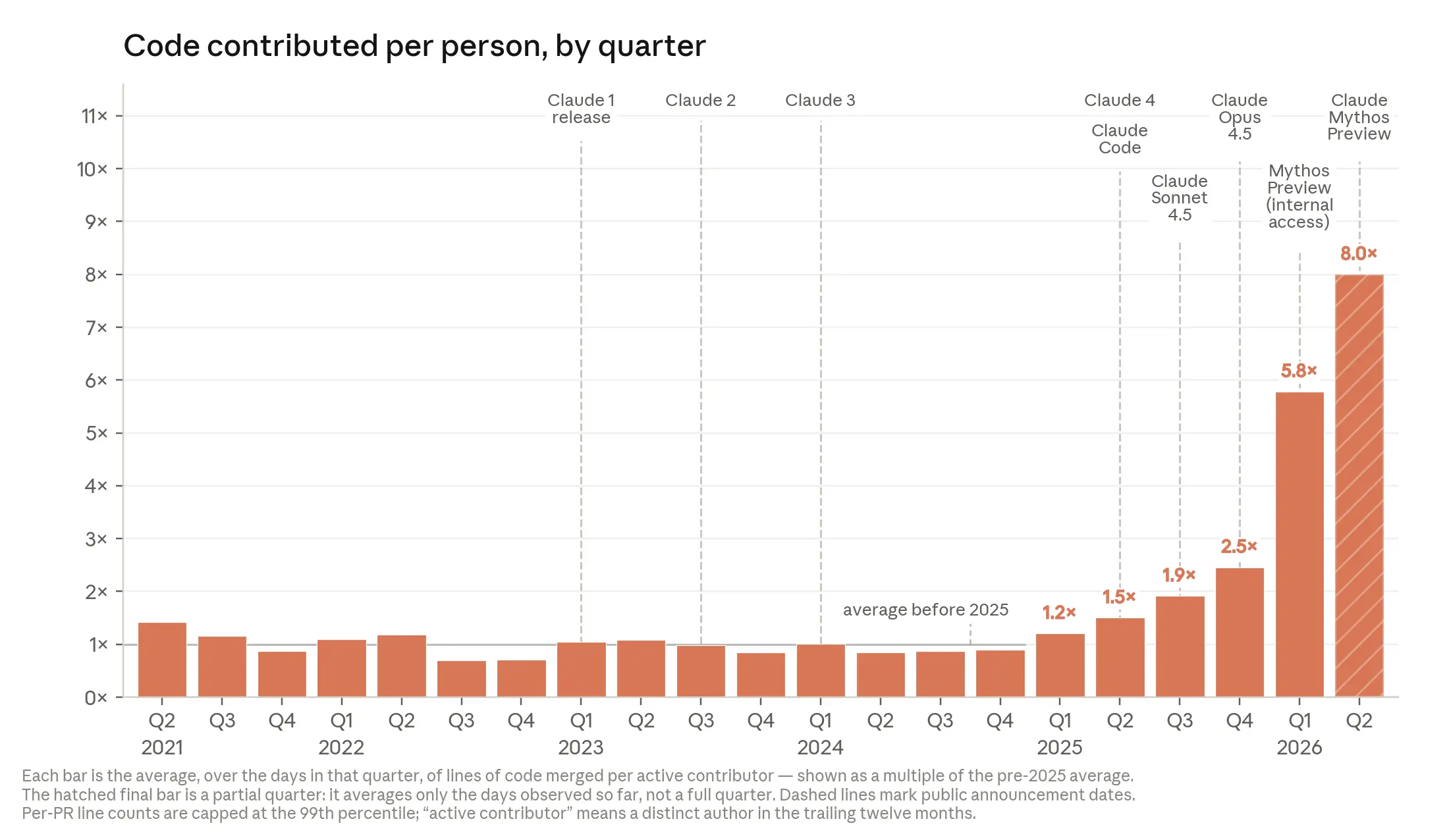
AI递归自我改进正加速到来,Anthropic内部数据显示工程师代码产出提升8倍,模型可靠任务时长每4个月翻倍,预计2027年可处理周级任务。
入选理由:Anthropic工程师季度代码产出较2021-2025年均值提升8倍,AI已实质性加速研发。
精选文章#递归自我改进#Anthropic#AI智能体#SWE-bench#METR英文
概念
用于评估编程模型性能的基准测试集。
已跟踪 5 条高相关材料
最近变化
2026-06-10 · North Mini Code 使用 MoE 架构,参数规模为 30B 和 3B,每 token 激活 8 个专家。
为什么值得关注
SWE-Bench 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
When AI Builds Itself: Our progress toward recursive self-improvement
Hacker News Best · 9.2 分
AI递归自我改进正加速到来,Anthropic内部数据显示工程师代码产出提升8倍,模型可靠任务时长每4个月翻倍,预计2027年可处理周级任务。
Cohere 发布首个开源编程模型「North Mini Code」 小参数、高效率、专做 Agent 编程 参数:MoE 架构(30B, 3B),128专家,每 token 激活 8 个 上下文:...
meng shao(@shao__meng) · 8.5 分
Cohere 发布开源编程模型 North Mini Code,采用 MoE 架构,专为 Agent 编程优化,性能接近大模型。
SWE-Bench style grading has been the standard for years now - you ask the agent to solve an issue an...
Scott Wu(@ScottWu46) · 8.5 分
FrontierCode 是一种新的代码评估基准,通过多维度评价模型生成代码的质量,显著减少误判并提升评估标准。
已收录 5 条与 SWE-Bench 相关的内容,按评分排序。
AI递归自我改进正加速到来,Anthropic内部数据显示工程师代码产出提升8倍,模型可靠任务时长每4个月翻倍,预计2027年可处理周级任务。
入选理由:Anthropic工程师季度代码产出较2021-2025年均值提升8倍,AI已实质性加速研发。
Cohere 发布开源编程模型 North Mini Code,采用 MoE 架构,专为 Agent 编程优化,性能接近大模型。
入选理由:North Mini Code 使用 MoE 架构,参数规模为 30B 和 3B,每 token 激活 8 个专家。
FrontierCode 是一种新的代码评估基准,通过多维度评价模型生成代码的质量,显著减少误判并提升评估标准。
入选理由:FrontierCode 评估标准比传统单元测试更全面,涵盖代码风格、可维护性等维度。
LLMs生成的代码虽功能通过率高(如Gemini 3.1 Pro达84.17%),但存在严重可维护性与安全缺陷,Sonar用4,444个Java任务评估发现其每百万行代码含614个bug,且代码冗长、复杂度高。
入选理由:Gemini 3.1 Pro在SWE Bench测试中功能通过率达84.17%,但生成代码冗长(307,000行)且复杂度高(圈复杂度234)。
AI系统即将实现自我构建,预计到2028年可能实现无人参与的AI研发。
入选理由:无人参与的AI研发可能在2028年前实现,概率超60%

