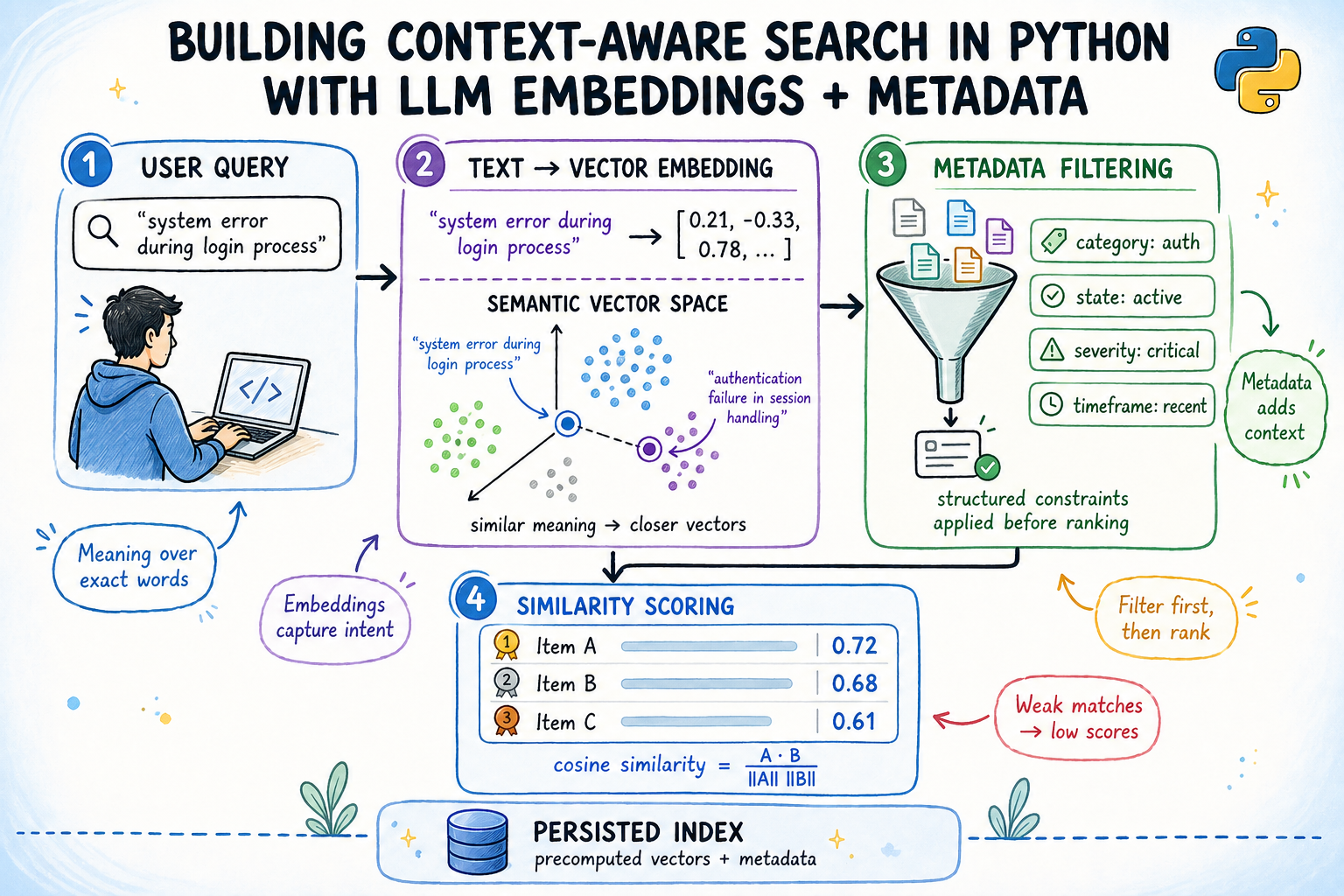
From TF-IDF to Transformers: Implementing Four Generations of Semantic Search
Towards Data Science4634 字 (约 19 分钟)
85
从TF-IDF到Transformer,文章通过四个阶段展示了语义搜索的演变过程,揭示了现代系统如何从手动设计特征转向直接从数据学习抽象意义。
入选理由:TF-IDF结合手工特征提供了透明的排名系统。
精选文章#TF-IDF#Transformer#Semantic Search#Machine Learning#Sentence Transformers中文