DeepSeek 的 10 万亿美元大战略
宝玉的分享5756 字 (约 24 分钟)
92
DeepSeek通过多项技术创新大幅降低大模型推理中的KV缓存需求,推动中国AI硬件生态发展,目标打造价值10万亿美元的产业巨兽。
入选理由:DeepSeek V4 Pro仅需5.48GB HBM,相比GLM5的60GB和Qwen3-235B-A22B的89GB显著节省显存
精选文章#AI模型#硬件生态#KV缓存#DeepSeek#中国AI中文
模型
别名:通义千问
阿里云大语言模型系列,Holo3.1 基于其架构设计。
已跟踪 30 条高相关材料
最近变化
2026-06-02 · Holo3.1 在 AndroidWorld 上 35B-A3B 模型准确率从 67% 提升至 79.3%
为什么值得关注
Qwen 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
DeepSeek 的 10 万亿美元大战略
宝玉的分享 · 9.2 分
DeepSeek通过多项技术创新大幅降低大模型推理中的KV缓存需求,推动中国AI硬件生态发展,目标打造价值10万亿美元的产业巨兽。
CyberSecQwen-4B: Why Defensive Cyber Needs Small, Specialized, Locally-Runnable Models
Hugging Face Blog · 8.8 分
小型专用模型如 CyberSecQwen-4B 在防御性网络安全任务中表现优于大型通用模型,且支持安全本地部署,无需 API 成本。
#558.AI时代的个人革命:Garry Tan 谈开源 AI、创业信仰、创伤动力
跨国串门儿计划 · 8.7 分
Garry Tan 认为AI正开启下一次个人计算革命,开源Agent与个人AI将赋予普通人前所未有的创造能力;YC核心信条是‘做出人们想要的东西’;创业者需以真诚感知力与主观能动性将创伤转化为创造力。
已收录 30 条与 Qwen 相关的内容,按评分排序。
DeepSeek通过多项技术创新大幅降低大模型推理中的KV缓存需求,推动中国AI硬件生态发展,目标打造价值10万亿美元的产业巨兽。
入选理由:DeepSeek V4 Pro仅需5.48GB HBM,相比GLM5的60GB和Qwen3-235B-A22B的89GB显著节省显存
小型专用模型如 CyberSecQwen-4B 在防御性网络安全任务中表现优于大型通用模型,且支持安全本地部署,无需 API 成本。
入选理由:CyberSecQwen-4B 在 CTI-MCQ 测试中以 0.5868 准确率超越 Cisco 8B 模型 8.7 个百分点。
Garry Tan 认为AI正开启下一次个人计算革命,开源Agent与个人AI将赋予普通人前所未有的创造能力;YC核心信条是‘做出人们想要的东西’;创业者需以真诚感知力与主观能动性将创伤转化为创造力。
入选理由:Garry Tan 提出‘个人AI必须由自己拥有和控制’,并正在开发 G Brain——整合邮件、日历、联系人与笔记的个人知识记忆系统。
Holo3.1 是 Hugging Face 推出的全新计算机使用代理模型,支持跨桌面、移动端与多框架部署,并首次提供 FP8/Q4 GGUF/NVFP4 量化权重以实现本地高效推理。
入选理由:Holo3.1 在 AndroidWorld 上 35B-A3B 模型准确率从 67% 提升至 79.3%
Databricks 提供了一个可靠的 LLM 推理平台,支持大规模多租户系统,通过先进的硬件和软件优化实现高可用性和低延迟。
入选理由:Databricks 平台支持多种前沿模型,包括开源和专有模型。
本文介绍了如何通过显式缓存优化Qwen模型的使用,包括缓存的工作原理、实现方法和最佳实践,帮助用户提高效率并降低成本。
入选理由:显式缓存可以显著减少重复请求的处理时间,提高响应速度。
Qwen在自主执行过程中,通过连续运行约35小时,进行了1158次工具调用,完成了432次内核评估,自主编写、编译、分析和迭代改进了Extend Attention Kernel,实现了10.0倍的几何提升。
入选理由:Qwen在35小时内自主执行,进行了1158次工具调用和432次内核评估。
Qwen on X highlights the latest developments in AI, particularly the Qwen3.7 Plus Preview and its impact on the Vision Arena.
入选理由:Qwen's Qwen3.7 Plus Preview enhances performance with new features, making it competitive in the lab rankings.
GB 200s 提高了大型 MoE 模型如 Qwen 的预填充和解码分离效率,相比 Hopper 平台,吞吐量显著提升。
入选理由:GB 200s 在高吞吐量推理方面比 Hopper 更适合大型 MoE 模型。
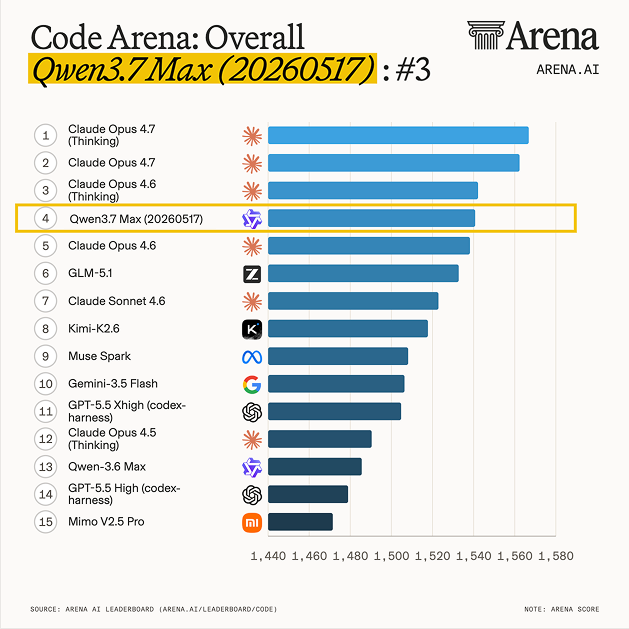
Qwen 3.7 Max 在 Arena Coding Agent 上排名第四,超越 GLM-5.1,与 Claude Opus 4.6 并驾齐驱。
入选理由:Qwen 3.7 Max 排名第四
Qwen3.7-Max 在 Code Arena 上排名第 4,与 Claude Opus 4.6 并驾齐驱,成为顶级中国实验室。
入选理由:Qwen3.7-Max 在 Code Arena 上排名第 4,超越 GLM-5.1。
使用FireworksAI Agent自动化LLM微调展示了自我改进AI系统的可行性,通过自然语言交互实现模型迭代,未来可构建递归自我提升系统以优化知识发现与研究自动化。
入选理由:FireworksAI Agent已实现LLM微调自动化,成功优化Qwen模型输出风格以适配PaperWiki知识库
林俊旸离职阿里后创立的新公司种子轮融资目标估值高达20亿美元,其核心理念是推动AI从推理式思考转向智能体式思考,即让模型为了行动而思考,强调环境设计、轨迹采样和编排工程的重要性。
入选理由:林俊旸离职阿里后创立的新公司种子轮融资目标估值高达20亿美元。
Claude模型在Code Arena的前端排行榜中占据主导,OpenAI和Gemini排名下滑。
入选理由:Claude模型占据了前五名,Opus 4.7 Thinking以30分优势领先。
Qwen3.5 达到 580 tps 的记录性突破,得益于 TokenSpeed 引擎和合作伙伴的优化。
入选理由:Qwen3.5 在 TokenSpeed 引擎上实现 580 tps 的性能。
AMD CEO苏姿丰在上海AI开发者大会上表示,AI竞争正从模型能力转向系统工程与全栈优化,开发者需要可落地、可优化、可持续演进的工程体系。AMD以ROCm开源平台为核心,提供云端到端侧的全栈算力,并持续加码中国开发者生态建设。
入选理由:AI行业竞争焦点正从模型能力转向系统工程与全栈优化能力,开发者需要可落地、可优化、可持续演进的工程体系
MiniCPM-V 4.6 是一个仅 13 亿参数的小型多模态视觉语言模型,采用 SIGLIP 视觉编码器和 Qwen 语言模型架构,支持图像、文档和视频输入,专为边缘设备部署设计。
入选理由:模型仅 13 亿参数,支持 262K 上下文窗口处理多图像和视频
Hermes Agent 是一个本地运行的 AI 助手框架,结合 OpenRouter 和 Qwen 模型实现高效推理,支持记忆层、Obsidian 集成及本地自动化脚本,可在 Android 设备上运行。
入选理由:Hermes Agent 使用 Qwen 3.6+ 模型实现推理成本降低至原价的十分之一
Hermes Agent 是一个本地运行的智能代理系统,结合 OpenRouter 和 Qwen 模型实现高效推理,支持记忆层和自动化脚本,可在 Android 设备上运行。
入选理由:Hermes Agent 使用 Qwen 3.6+ 实现低成本高效率推理,将 token 成本从 $100 降至 $10。
阿里云Qwen系列多尺寸模型在SiliconFlow平台上线。
入选理由:Qwen3.5-397B-A17B是最大参数模型
Qwen3.7预览版在Arena上线,阿里视觉排名升至第五,模型系列即将发布。
入选理由:Qwen3.7-Plus-Preview在Arena视觉竞技场排名第五,整体排名第十六
Geekbb 宣布,阿里巴巴的 Qwen3.6-Plus 已经上线 Nous Portal,并且限时免费。这标志着 Qwen 与 Nous Research 的合作进入了一个新的阶段。
入选理由:阿里巴巴的 Qwen3.6-Plus 已经上线 Nous Portal 并且限时免费。
Qwen发布了Browser Agent的演示视频,但未提供技术细节,仅展示自动化浏览器操作的示例。
入选理由:Qwen于2026年6月1日在X平台发布Browser Agent演示视频。
Qwen 3.7 Max 已经在 Hermes Agent 中支持。
入选理由:Qwen 3.7 Max 在 Hermes Agent 中支持
Qwen3.7-Plus是通义千问的多模态代理模型,统一视觉和语言能力,支持GUI/CLI操作和编码任务,现已通过阿里云API提供。
入选理由:Qwen3.7-Plus支持多模态交互,统一GUI和CLI操作处理视觉和文本任务。
Qwen3.6-Plus 现已在 Nous Portal 上免费限时提供,用户可以通过单一订阅访问 300 多个模型,享受专属折扣和简单账单管理。
入选理由:Qwen3.6-Plus 在 Nous Portal 上限时免费。
文章是阿里巴巴Qwen团队发布的招募大使的公告,提供早期访问模型、API积分等福利。
入选理由:招募开发者和社区领袖担任大使
Qwen发布了Demo2: 多模态交互混合代理,但未提供技术细节或实现原理。
入选理由:Qwen于2026年6月1日在X上宣布了Demo2: Multimodal Interactive Hybrid Agent。
橙色 AI 在推特上分享了一条关于 Anthropic 蒸馏中国模型的消息,提到有证据表明 Claude 蒸馏了 Kimi 和 Qwen,但责任归属存在争议。
入选理由:Anthropic 蒸馏了中国的 Kimi 和 Qwen 模型。
该推文为明显错误传言:Claude由Anthropic开发,Kimi由月之暗面研发,二者无任何技术关联,属典型AI谣言。
入选理由:Claude由Anthropic公司研发,与月之暗面的Kimi模型无任何训练或架构关系