Benchmark and optimize LLMs on-device with AI Edge Portal
Google Cloud Blog924 字 (约 4 分钟)
85
Google AI Edge Portal新增LLM基准测试和调试功能,支持在120+ Android设备上优化模型性能,提供初始化时间、解码速度等关键指标分析及可视化调试工具。
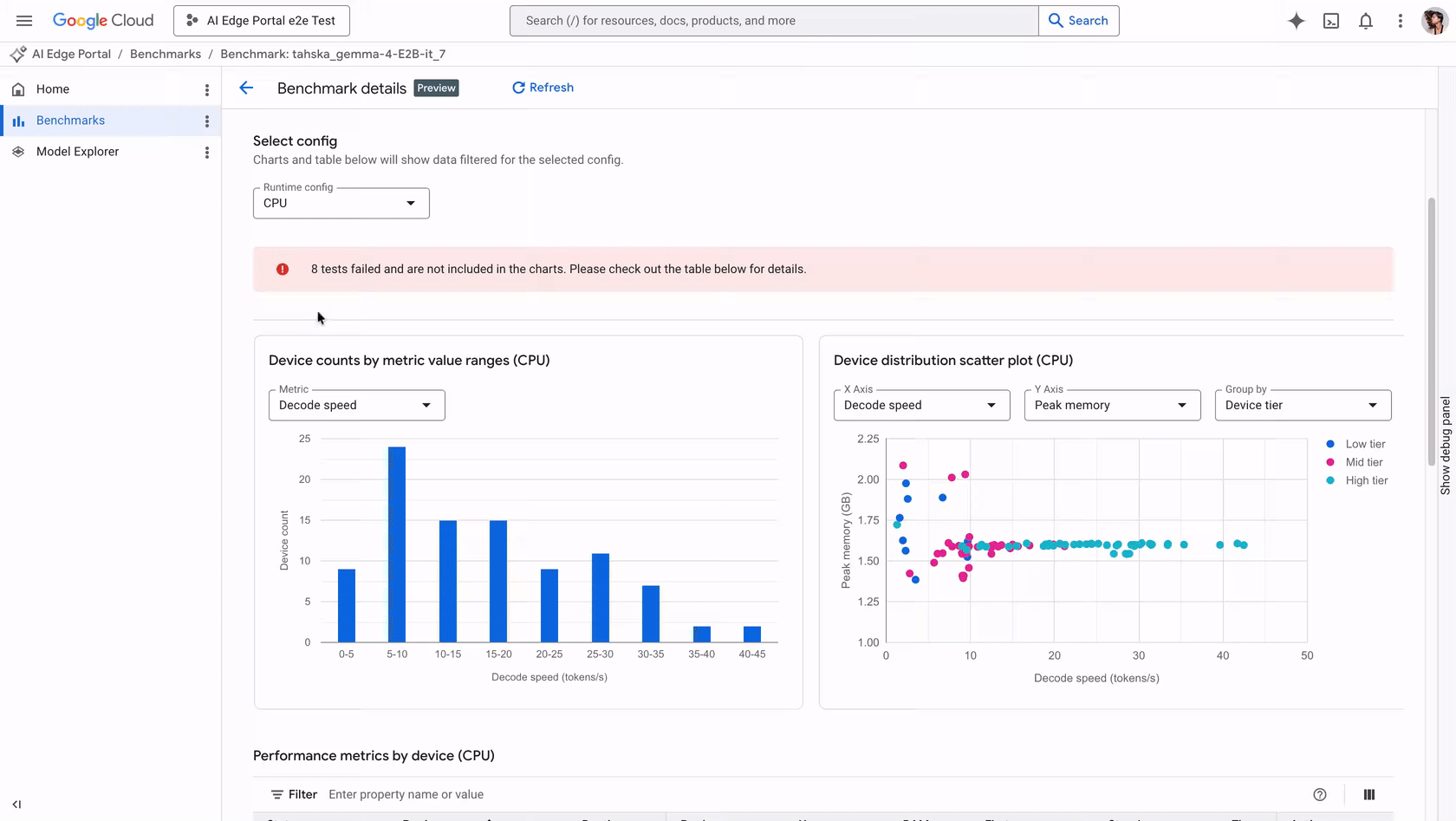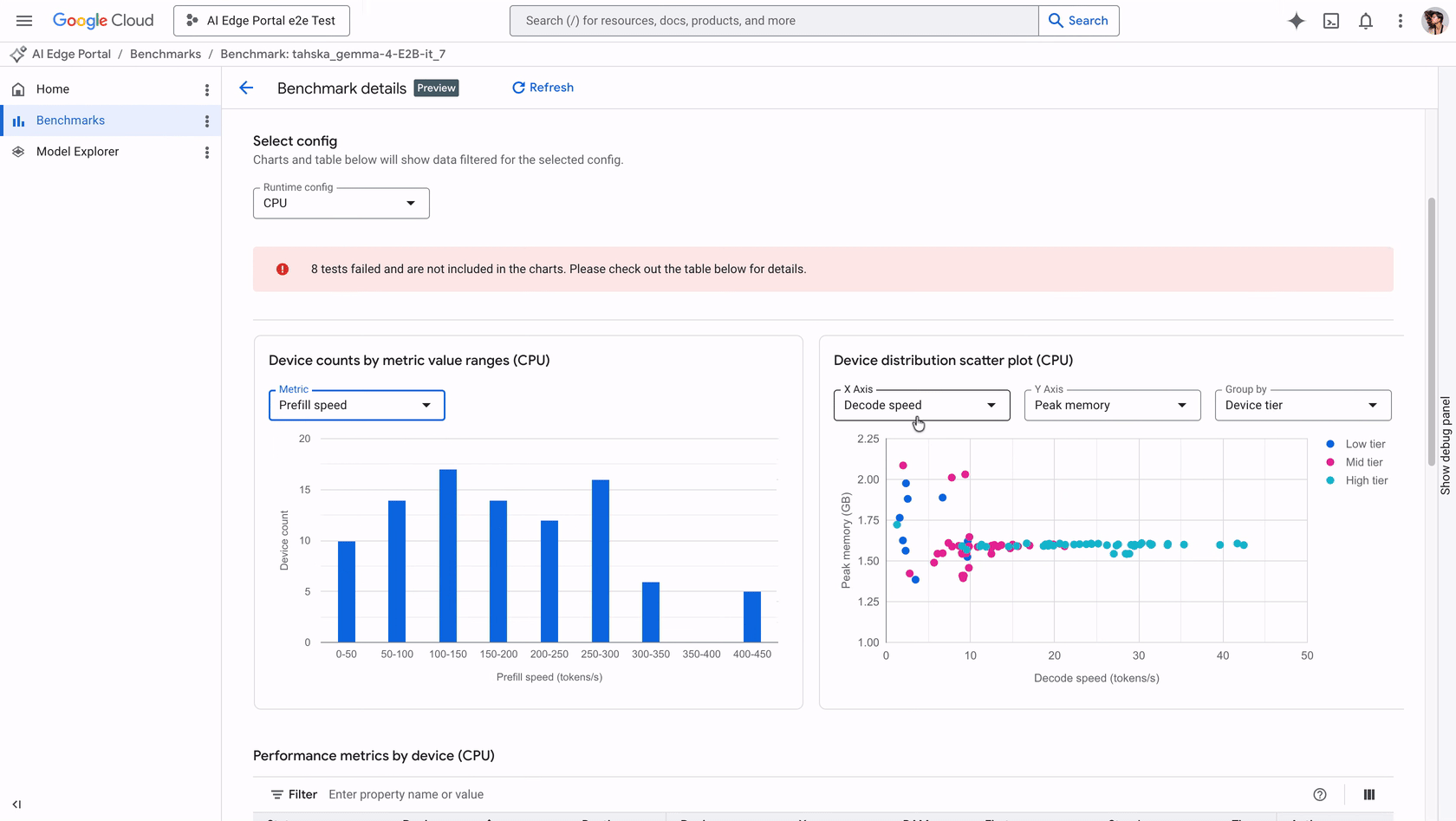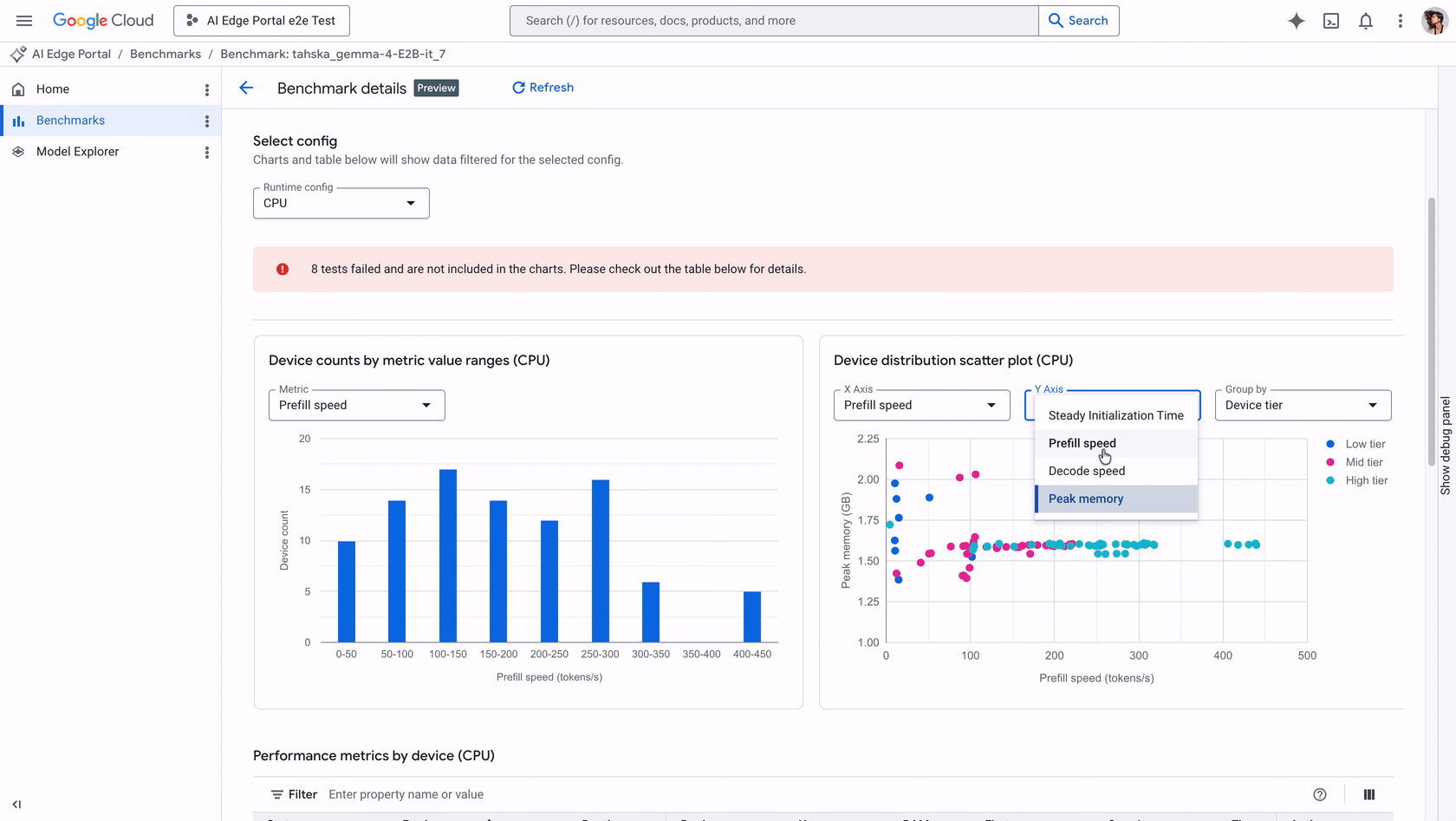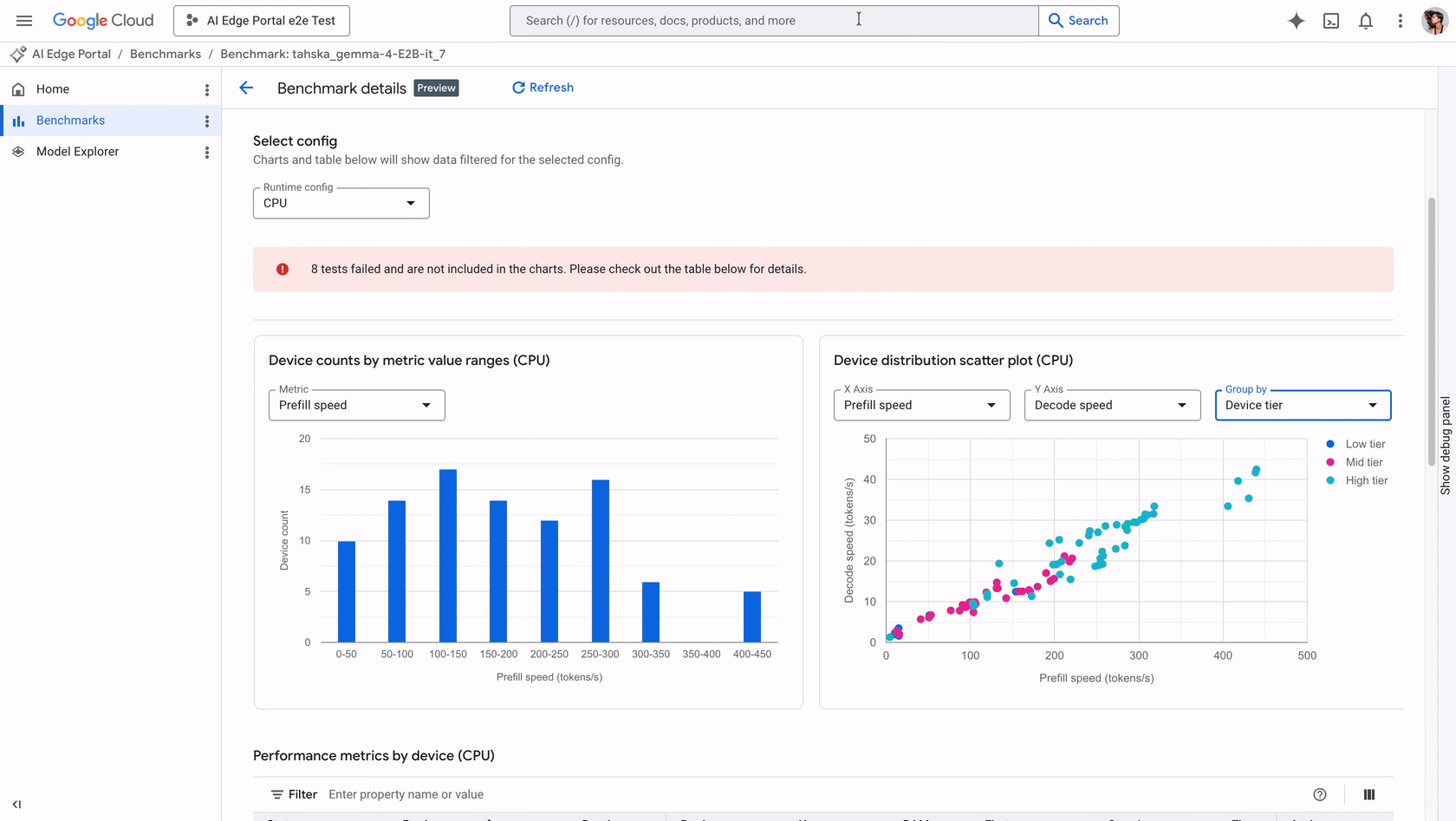
入选理由:AI Edge Portal支持在120+ Android设备上测试LLM,提供初始化时间、预填速度等4项核心性能指标
精选文章#LLM优化#边缘计算#Android设备#Google AI Edge Portal#Model Explorer英文