
#552. AI进展为何突然变得真实:详解 GPT 5.5、强化学习与模型最后一公里
跨国串门儿计划2657 字 (约 11 分钟)
92
GPT 5.5 等模型能力提升并非突变,而是模型可靠性跨过关键阈值的结果。强化学习、后训练优化及评估体系演进推动了 AI 实用化进程。
入选理由:GPT 5.5 通过增强推理能力和工具使用实现更强实用性
精选播客#AI#GPT#强化学习#模型训练#OpenAI中文
模型
别名:GPT-5.5
OpenAI新一代基础模型,具备增强的智能体编码与工具使用能力。
已跟踪 30 条高相关材料
最近变化
2026-06-03 · GPT-Rosalind集成GPT-5.5的Agentic Coding能力,支持自动化药物研发代码生成与调试。
为什么值得关注
GPT-5.5 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
#552. AI进展为何突然变得真实:详解 GPT 5.5、强化学习与模型最后一公里
跨国串门儿计划 · 9.2 分
GPT 5.5 等模型能力提升并非突变,而是模型可靠性跨过关键阈值的结果。强化学习、后训练优化及评估体系演进推动了 AI 实用化进程。
Introducing new capabilities to GPT-Rosalind
OpenAI Blog · 8.5 分
OpenAI introduces a new model update to GPT-Rosalind, designed for life sciences research at enterprise scale. The updated model combines G...
MiniMax M3一手实测:老黄PPT上74个Logo,我以为能难住它
量子位 · 8.5 分
MiniMax M3是国内首个同时具备长上下文、多模态与Coding能力的开源模型,实测在SWE-Bench Pro上跑出59%成绩,超越GPT-5.5和Gemini 3.1 Pro,效率达上代1/20。
已收录 30 条与 GPT-5.5 相关的内容,按评分排序。
GPT 5.5 等模型能力提升并非突变,而是模型可靠性跨过关键阈值的结果。强化学习、后训练优化及评估体系演进推动了 AI 实用化进程。
入选理由:GPT 5.5 通过增强推理能力和工具使用实现更强实用性
OpenAI引入了GPT-Rosalind的新能力,旨在为生命科学研究提供企业级支持。该模型结合了GPT-5.5的生成文本和代码的能力,以及在药物发现核心领域(如药物化学和基因组学)的更强模型智能。GPT-Rosalind在生物学专家、复杂药物化学查询、定量生物学和湿实验流程中表现出色。
入选理由:GPT-Rosalind combines GPT-5.5's agentic coding and tool-use capabilities with stronger model intelligence in core drug-discovery domains.
MiniMax M3是国内首个同时具备长上下文、多模态与Coding能力的开源模型,实测在SWE-Bench Pro上跑出59%成绩,超越GPT-5.5和Gemini 3.1 Pro,效率达上代1/20。
入选理由:M3在SWE-Bench Pro上得分59%,超越GPT-5.5和Gemini 3.1 Pro
OpenAI 的 GPT-5.5、GPT-5.4 和 Codex 现已在 Amazon Bedrock 全面上线,支持生产环境部署,定价与 OpenAI 官方一致,并继承 AWS 安全与治理框架。
入选理由:GPT-5.5 在 Bedrock 上提供与 OpenAI 直接调用相同的每 token 定价,无额外费用。
Deep Suite 是一个软件工程基准测试,旨在提供比现有公共基准测试更准确的模型评估。它具有四个主要优势:无污染任务、高多样性、现实世界复杂性和可靠的验证。根据 Deep Suite 的测试,GPT 5.5 在性能上优于 Opus 4.7。
入选理由:Deep Suite 通过手写任务避免了模型在预训练期间看到解决方案的问题。
文章认为 Anthropic 和 OpenAI 已经找到了产品市场契合点,通过提高 API 价格锁定企业客户。
入选理由:Anthropic 和 OpenAI 都提高了 API 价格,锁定企业客户。
Every公司的CEO Dan Shipper分享了AI工具在实际工作中的应用,揭示了AI越强反而使人更忙的现象,并预测未来工作方式将向公司级和工作操作系统方向发展。
入选理由:AI工具在实际工作中存在缺陷,无法主动发现问题并重新定义。
GPT-5.5 被低估了其在网络安全领域的强大能力,成功发现了一个27年的远程代码执行漏洞。
入选理由:GPT-5.5 发现了一个1999年引入的27年-old RCE漏洞。
Warp 使用 GPT-5.5 推动开源软件开发,通过 Open Agentic Development 模型,人类定义目标,AI 代理执行任务,提高开发效率和代码质量。
入选理由:Warp 引入 Open Agentic Development 模型,AI 代理协助编写代码,提高开发效率。
Anthropic和OpenAI通过调整定价策略,表明它们已经找到了产品市场契合点,企业客户现在按API价格付费,而非之前的折扣价。
入选理由:Anthropic和OpenAI将企业客户的定价从折扣价改为API价格。
ITBench-AA 是一个针对企业级自动化 IT 任务的新基准测试,首次评估前沿模型在 Site Reliability Engineering 任务中的表现,结果显示所有前沿模型得分低于 50%,其中 Claude Opus 4.7 表现最佳,为 47%。
入选理由:Claude Opus 4.7 在 ITBench-AA 中表现最佳,得分为 47%
GPT-5.5 是一个独特的优秀编程模型,作者 Theo 表示已经对其产生了深厚的喜爱,并认为无法再使用其他模型进行代码编写。
入选理由:GPT-5.5 是一个独特的优秀编程模型。
GPT-5.5 在复杂代理工作方面的表现有了显著提升,优于 Opus 4.7,显示出 OpenAI 的强劲竞争力。
入选理由:GPT-5.5 在复杂代理工作方面表现出色。
Anthropic发布Claude Opus 4.8,但多位专家指出其与4.7几乎无差异,已进入类似iPhone的‘渐进式升级’时代;Deep Suite实测显示GPT 5.5在编码任务中以更低成本获得更高得分,OpenAI Codex更新未公开但显著增强。
入选理由:Opus 4.8与4.7对比,作者及多位专家均无法分辨性能差异,体现模型演进进入‘iPhone式’渐进阶段。
开源模型MiniMax M3已达到与GPT-5.5和Opus 4.7相当的性能,尤其在编码任务上优于Gemini 3.1 Pro,且成本仅为它们的1/10,其权重将于下周在Hugging Face开放。
入选理由:MiniMax M3在SWE Bench Pro上与GPT-5.5性能相当
OpenAI 的 GPT-5.5、GPT-5.4 和 Codex 模型现已通过 Amazon Bedrock 正式上线,支持自动扩展和下一代推理引擎,助力企业构建多步骤自主代理系统。
入选理由:GPT-5.5、GPT-5.4 和 Codex 已在 Amazon Bedrock 上正式可用,支持自动扩展。
Cursor 的 $10K 信用额度到期后,用户反馈其 Agent Window 模式几乎完全替代传统 IDE,GPT-5.5 和 Composer 2.5 在不同场景下表现优异,尤其 Fast 模式响应快且擅长生成流程图,但输出默认非 Markdown 且不支持直接复制为 Markdown,影响使用效率。
入选理由:用户 100% 时间使用 Cursor 的 Agent Window,未打开传统 IDE 界面。
GPT-5.5 在复杂构建任务中显著提升规划能力,用户一次性成功率达31%,遗忘率降低22%,使非技术用户可专注目标而非代码。
入选理由:GPT-5.5 规划阶段意图理解提升31%,减少重复交互需求。
使用 Coding Agent 开发新功能时,重点在于规划阶段,通过多个模型生成计划并选择最佳方案,确保后续开发顺利进行。
入选理由:开发新功能前先整理需求,使用多个 Agent 生成计划。
阿里推出Qwen-3.7-Max模型,在成本和性能上显著优于GPT-5.5和Opus 4.7,支持与Hermes Agent或OpenCode集成。
入选理由:Qwen-3.7-Max输出价格比Opus 4.7便宜3.3倍,比GPT-5.5便宜4倍。
GPT-Rosalind重大升级整合GPT-5.5智能体编码与工具调用能力,显著提升药物发现、分析及实验工作流的企业级AI应用效能。
入选理由:GPT-Rosalind集成GPT-5.5的Agentic Coding能力,支持自动化药物研发代码生成与调试。
Google 在 I/O 大会上发布了 Gemini 3.5 Flash 模型,主打速度优势并强化免费体验,成为用户从 ChatGPT 或 Claude 转移的潜在理由。
入选理由:Gemini 3.5 Flash 成为 Google Search 和 Gemini 默认模型,推理速度显著优于竞品。
尹希以学术休假身份加入OpenAI,推动AI与理论物理交叉研究,称AI可复制人类智力极限,加速科研百倍。
入选理由:尹希12岁入中科大少年班,31岁成哈佛最年轻华人正教授,现以学术休假身份加入OpenAI。
文章质疑SWEbench基准测试的可信度,指出GPT-5.5在DeepSuite中表现远超Claude Opus 4.7,但SWEbench结果却显示相反,表明该测试可能已失效。
入选理由:SWEbench测试结果被质疑,GPT-5.5在DeepSuite中得分为70%,显著高于Claude Opus 4.7的54%。
Anthropic 推出 Claude Opus 4.8,在多轮评估中表现‘小幅提升但非主导’,尤其在文档解析准确性上退步;平台新增中途系统指令支持,但 API 定价仍受诟病;Hugging Face 揭示多轮 RL 训练中因 re-tokenization 导致梯度失效的隐蔽问题。
入选理由:Claude Opus 4.8 在 CursorBench 上效率更高,但相比 4.7 仅小幅提升且在内容忠实性/图表解析上出现退步
DeepSeek-V4 Pro因高性价比被用于review与写作任务,替代高价Qwen-Max;主力排序为GPT-5.5 > Claude 4.7 > DeepSeek-V4 Pro。
入选理由:DeepSeek-V4 Pro在小任务(如review、写作)中表现良好且价格显著低于Qwen-Max
DeepSWE 评测显示 Opus 4.8 性能优于 4.7,成本更低、效率更高,但远逊于 GPT-5.5;作者仍用更便宜的 4.6,因价格优势;并质疑 Benchmark 可信度,更信真实用户反馈。
入选理由:Opus 4.8 性能强于 4.7,同时具备更低推理成本与更高效率,但未达 GPT-5.5 水平。
SWEbench 基准测试已失效,GPT 5.5 在 Deep Suite 上以 70% 准确率领先 Opus 4.7 的 54%,而 SWEbench 显示相反趋势,表明基准不可靠。
入选理由:GPT 5.5 achieves 70% accuracy on Deep Suite, significantly outperforming Opus 4.7 at 54%.
Codex Windows端上线Computer Use功能,Copilot转为token计费,GPT5.5涨价。
入选理由:Codex Windows端上线Computer Use功能
GPT-5.5(虚构版本)错误地将数字11归类为‘偶数行窗口’,暴露了模型在基础数学与术语理解上的严重缺陷。
入选理由:GPT-5.5被指称将11误判为‘even row window’,实为对‘even’与‘row/window’等术语的语义混淆。
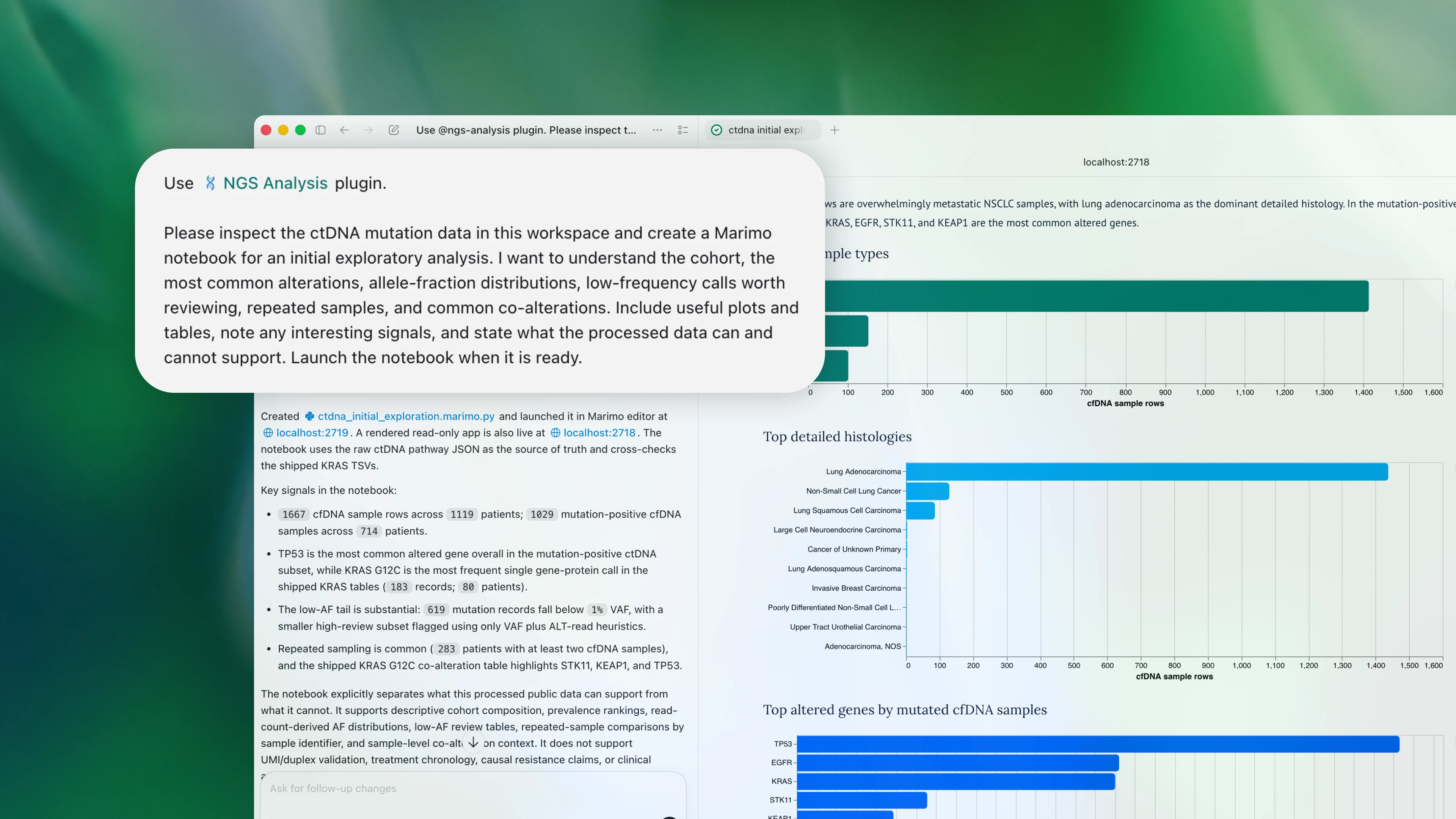


















![[AINews] Founders and Forward Deployed Engineers](https://substackcdn.com/image/fetch/$s_!SpLP!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb92541e3-151a-4f10-8226-b86cb12eaca0_2332x1344.png)


