加速设备端AI:解析Arm和Google AI Edge优化
Google Developers Blog1644 字 (约 7 分钟)
85
文章介绍了Arm和Google合作优化边缘AI推理,通过SME2架构和Google AI Edge工具链提升设备端AI性能。
入选理由:Arm SME2使CPU成为高性能AI加速器,推理速度提升5倍
精选文章#AI Edge#Arm#机器学习#边缘计算中文
产品
别名:AI Edge
Google提供的端侧AI推理与部署技术栈,包含Gallery、Eloquent和LiteRT等工具。
已跟踪 3 条高相关材料
最近变化
2026-06-05 · Gemma 4 12B通过LiteRT-LM在消费级笔记本运行,支持本地Agent与多模态任务。
为什么值得关注
Google AI Edge 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
Accelerating on-device AI: A look at Arm and Google AI Edge optimization
Google Developers Blog · 8.5 分
文章介绍了Arm和Google合作优化边缘AI推理,通过SME2架构和Google AI Edge工具链提升设备端AI性能。
Bringing Gemma 4 12B to your Laptop: Unlocking Local, Agentic Workflows with Google AI Edge
Google Developers Blog · 8.2 分
Gemma 4 12B模型结合Google AI Edge栈已实现笔记本端本地运行,支持macOS上的代码生成、语音编辑及OpenAI兼容API服务。该组合使设备端Agent工作流成为可能,指令遵循质量提升超60%,且全程离线保障数据隐私。
Blazing fast on-device GenAI with LiteRT-LM
Google Developers Blog · 7.5 分
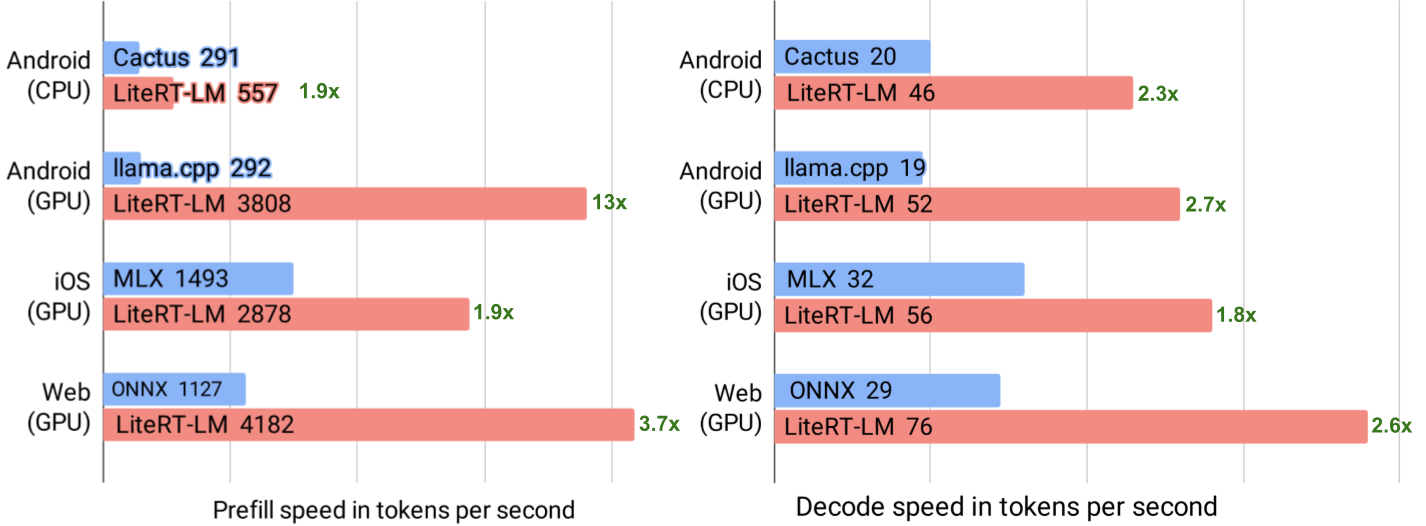
Google AI Edge 发布 LiteRT-LM 推理引擎,专为在边缘设备上高效运行 Gemma 4 模型设计,支持 Android、iOS、Web 多平台,GPU 推理可达 76 tokens/sec,结合 Multi-Token Prediction 技术实现 2.2...
已收录 3 条与 Google AI Edge 相关的内容,按评分排序。
文章介绍了Arm和Google合作优化边缘AI推理,通过SME2架构和Google AI Edge工具链提升设备端AI性能。
入选理由:Arm SME2使CPU成为高性能AI加速器,推理速度提升5倍
Gemma 4 12B模型结合Google AI Edge栈已实现笔记本端本地运行,支持macOS上的代码生成、语音编辑及OpenAI兼容API服务。该组合使设备端Agent工作流成为可能,指令遵循质量提升超60%,且全程离线保障数据隐私。
入选理由:Gemma 4 12B通过LiteRT-LM在消费级笔记本运行,支持本地Agent与多模态任务。
Google AI Edge 发布 LiteRT-LM 推理引擎,专为在边缘设备上高效运行 Gemma 4 模型设计,支持 Android、iOS、Web 多平台,GPU 推理可达 76 tokens/sec,结合 Multi-Token Prediction 技术实现 2.2 倍加速。
入选理由:LiteRT-LM 在 Android GPU (OpenCL) 上实现 52 tokens/sec 解码速度,iOS (Metal) 达 56 tokens/sec,WebGPU 在 MacBook Pro 上可达 76 tokens/sec