前沿模型是强大的顾问
Fireworks AI(@FireworksAI_HQ)188 字 (约 1 分钟)
87
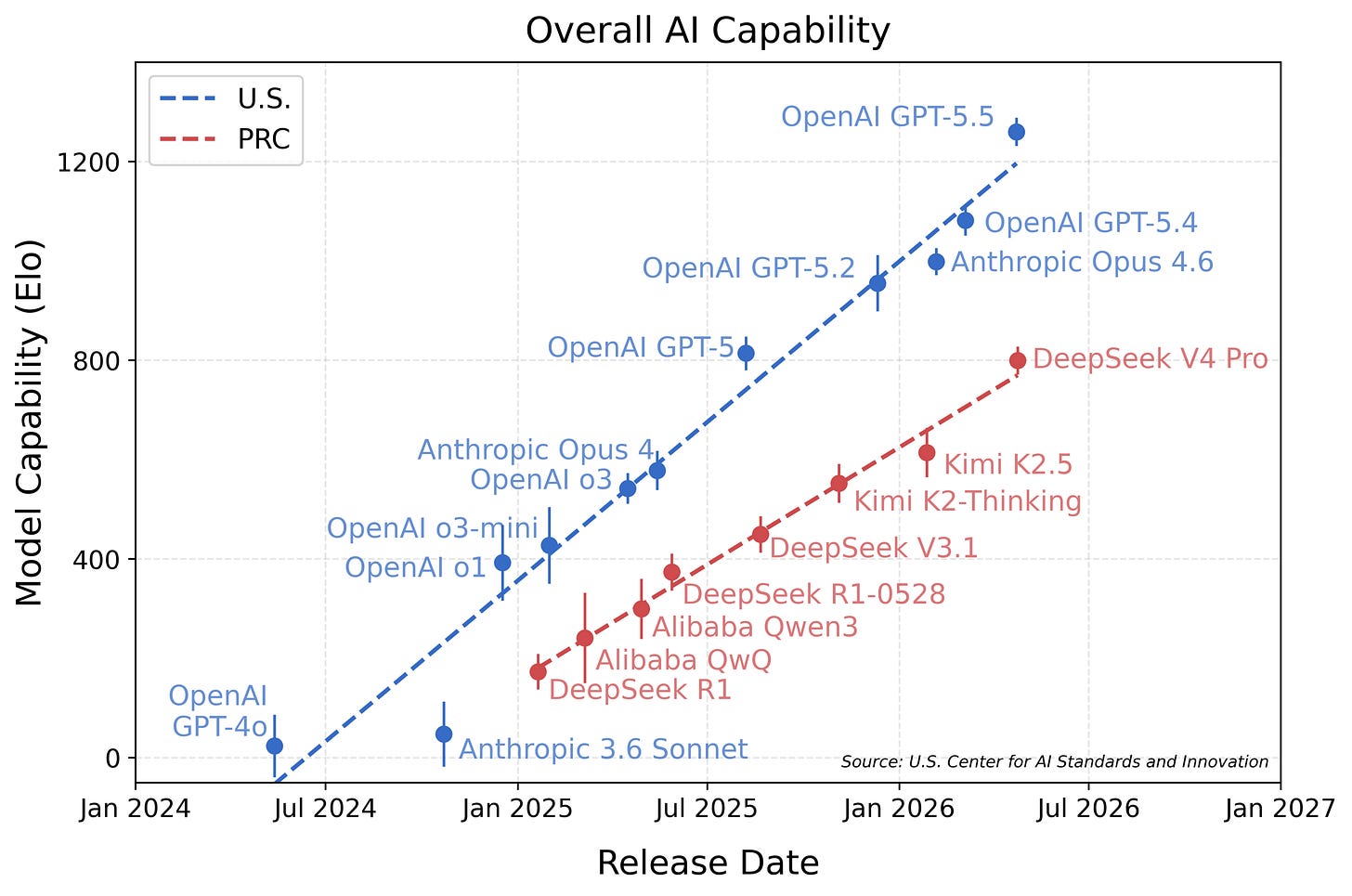
Fireworks AI 通过“harness + advisor”架构,在 Harvey 法务代理基准上以 Claude Opus 4.7 为稀疏顾问,将 GLM 5.1 工作者性能提升至 18/100 全对,成本仅为 Opus 的 39%。
入选理由:在 Harvey 法务代理基准上,GLM 5.1 + Claude Opus 4.7 稀疏顾问方案全对数达 18/100。
精选推文#前沿模型#法务代理基准#harness 设计#顾问模式#Claude Opus 4.7英文