Google AI Studio 3.0 (Fully Free): This is ACTUALLY AWESOME!
AICodeKing979 字 (约 4 分钟)
87
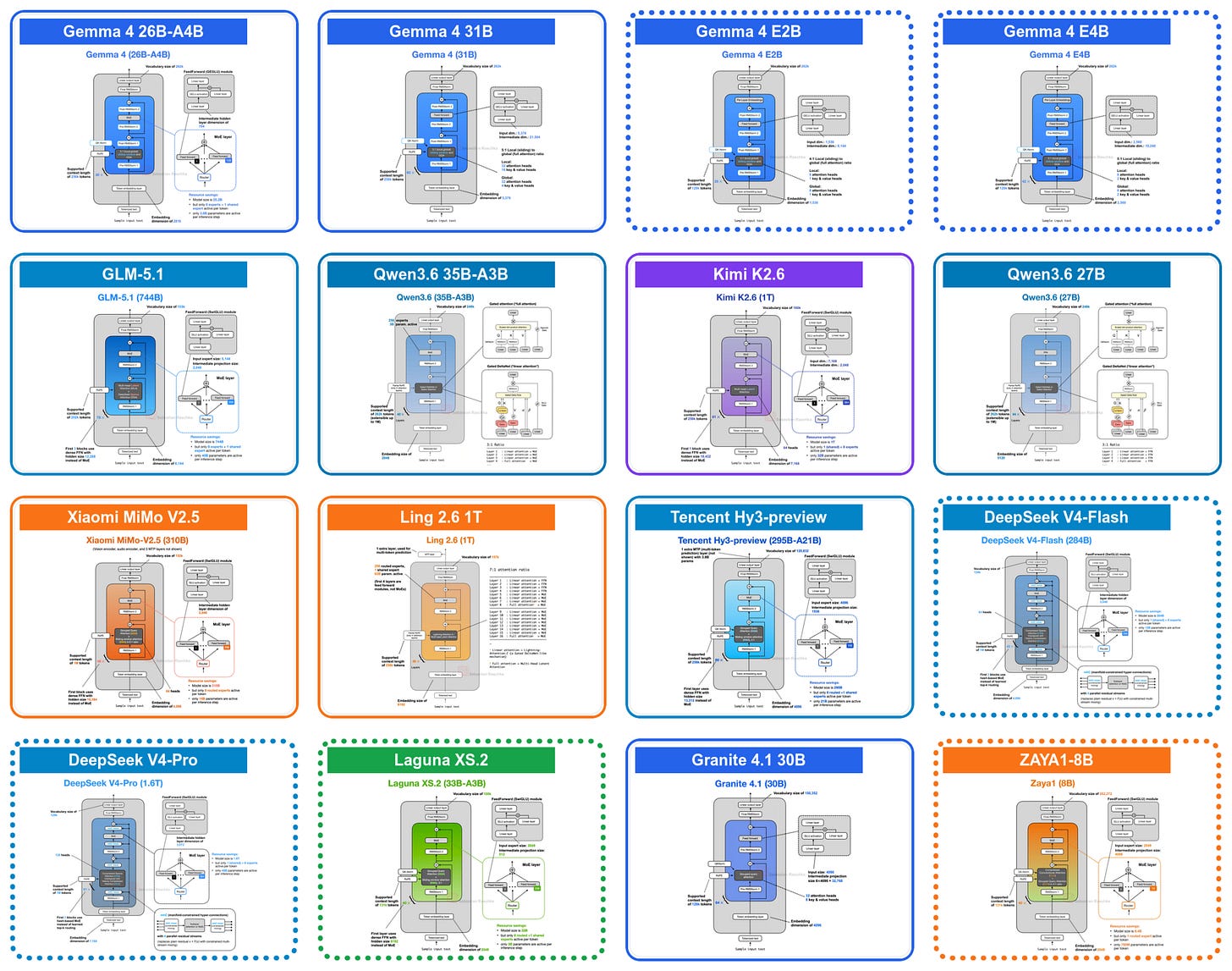
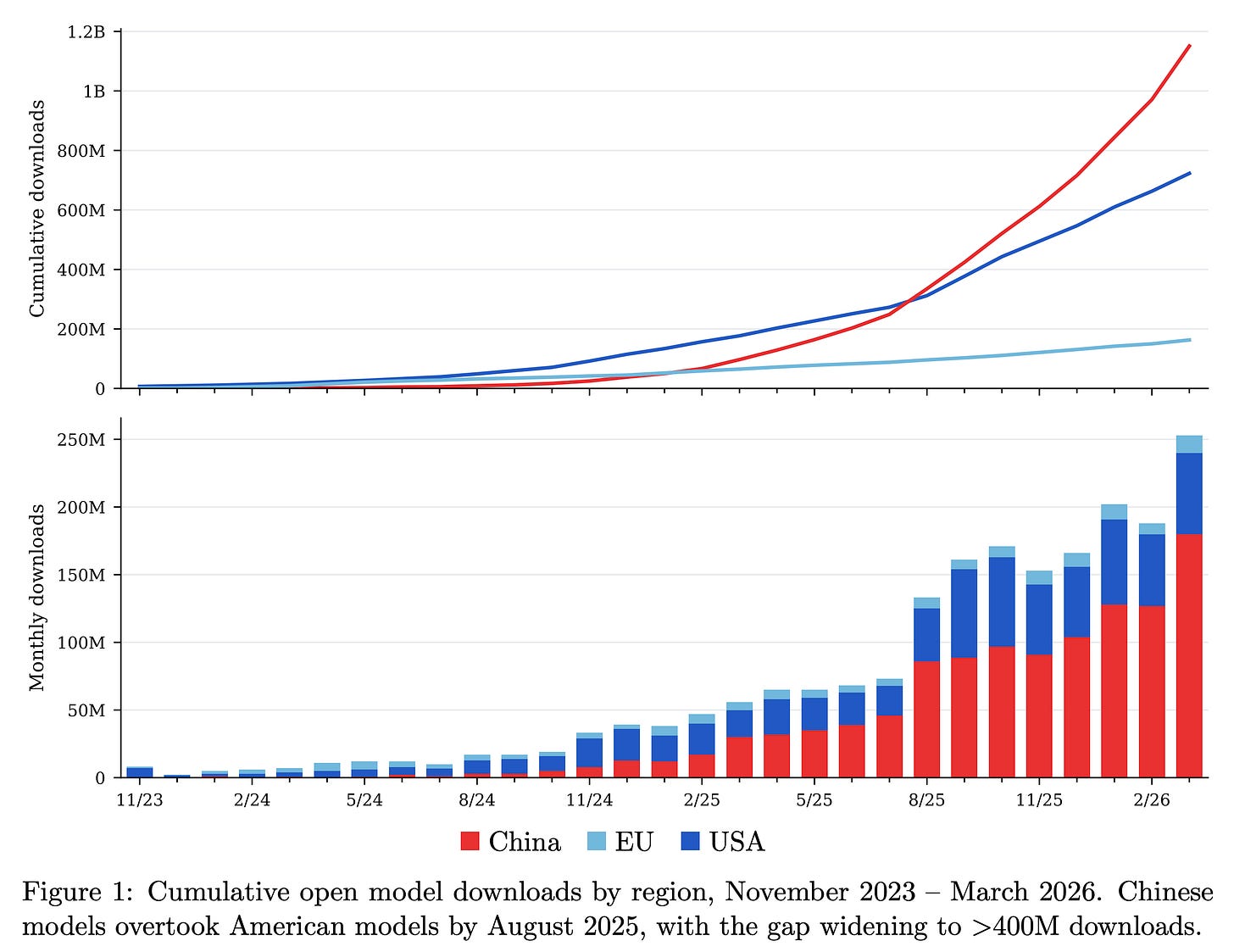
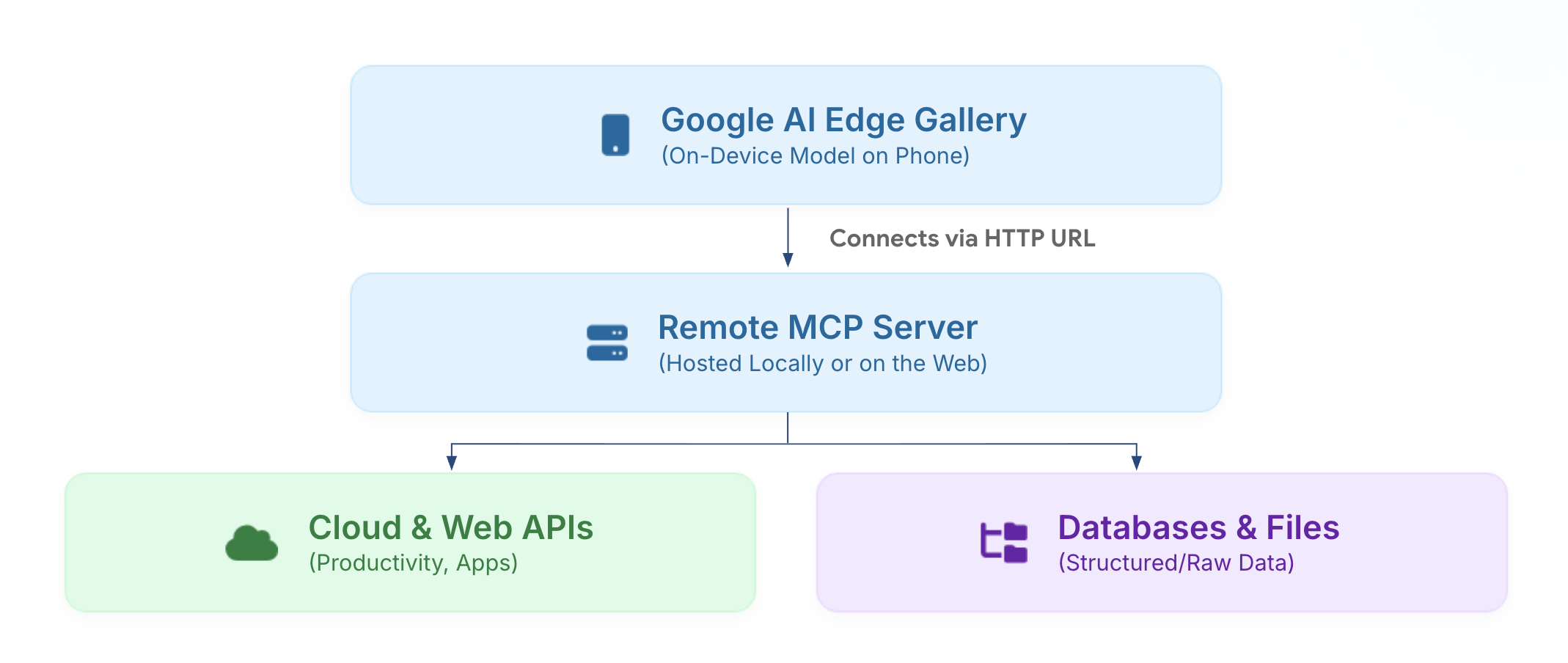
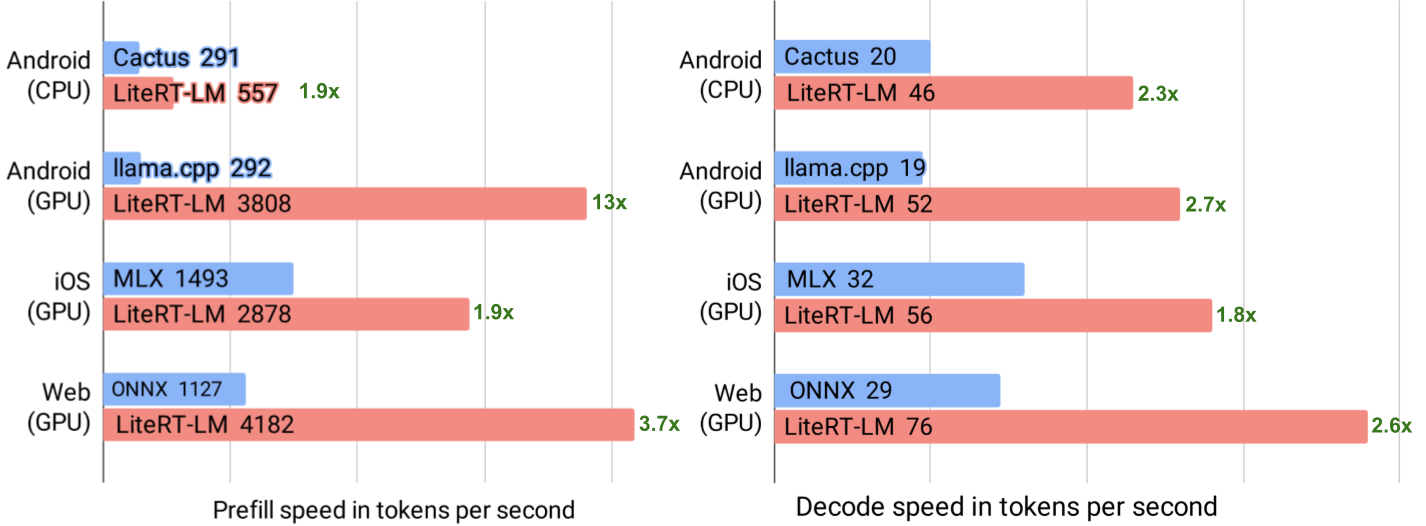
Google AI Studio 3.0 全免费上线,集成 Gemma 4 模型与多模态能力,支持实时推理、自定义模型部署和 API 接入,显著降低开发者使用门槛。
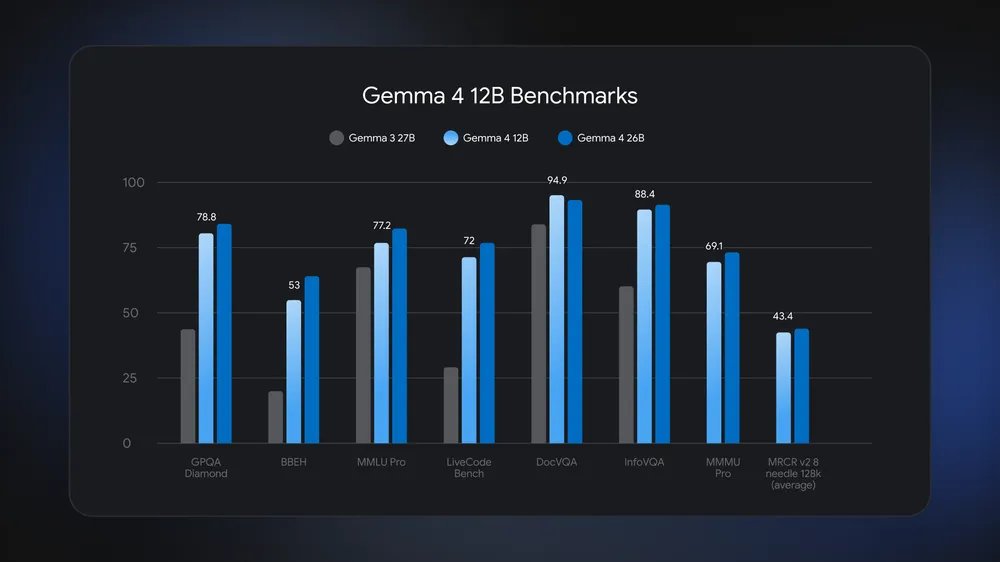
入选理由:Gemma 4 模型在 Google AI Studio 3.0 中完全免费,支持 128K 上下文长度。
精选视频#Google AI Studio#Gemma 4#AI 开发工具#免费 AI 平台中文