Gemini 3.5 Flash:更贵了,但谷歌计划用它做所有事
Simon Willison's Weblog615 字 (约 3 分钟)
87
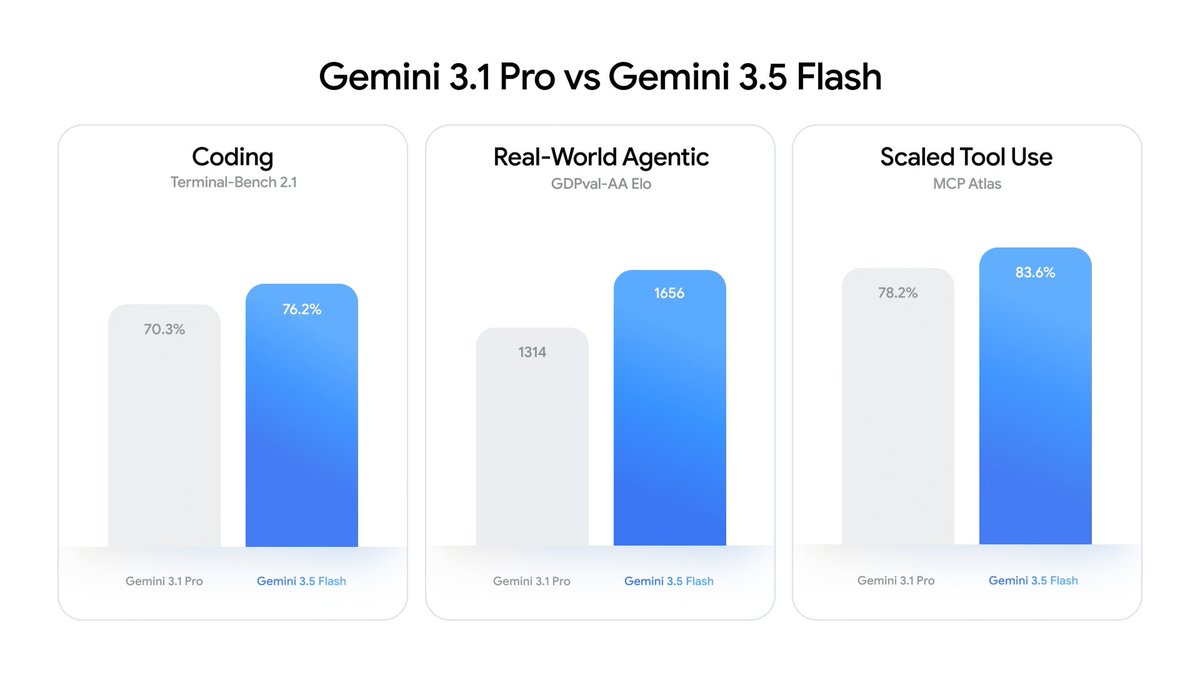
Google发布Gemini 3.5 Flash,定价是前代Flash-Lite的6倍,却广泛部署于搜索、AI助手和企业平台,反映大模型厂商正通过高价模型试探API客户支付意愿。
入选理由:Gemini 3.5 Flash输入价格为$1.50/百万token,输出为$9/百万token,是3.1 Flash-Lite的6倍。
精选文章#Gemini#Google#AI模型#API定价#大模型部署英文