Firecrawl v2.10 正式上线
Firecrawl(@firecrawl_dev)523 字 (约 3 分钟)
85
Firecrawl v2.10 引入了本地文件解析、沙盒抓取模式、三种新抓取格式和四个新 SDK,同时修复了多个可靠性问题。
入选理由:v2.10 支持上传至 50MB 的本地文件并返回 LLM 友好的 Markdown、JSON 或摘要
精选推文#Firecrawl#SDK#爬虫英文
公司
别名:firecrawl_dev
提供代理用户注册功能的公司,支持与多个 AI 模型集成。
已跟踪 27 条高相关材料
最近变化
2026-06-09 · 推文内容缺乏技术细节和深度分析。
为什么值得关注
Firecrawl 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
https://t.co/wWSHbw4AVj
Firecrawl(@firecrawl_dev) · 8.5 分
Firecrawl v2.10 引入了本地文件解析、沙盒抓取模式、三种新抓取格式和四个新 SDK,同时修复了多个可靠性问题。
Today we're releasing Monitoring by Firecrawl 📡 Just enter a URL, describe what you want to track...
Firecrawl(@firecrawl_dev) · 7.5 分
Firecrawl 推出新工具,通过监控页面变化减少 90% 的 LLM 令牌消耗,提升 AI 数据处理效率。
Firecrawl joins the Vercel Marketplace
Vercel News · 7.5 分
Firecrawl 已经加入 Vercel 市场,允许 Vercel 团队使用结构化网页数据来 powering AI 代理和应用程序,无需管理爬虫基础设施。
已收录 27 条与 Firecrawl 相关的内容,按评分排序。
Firecrawl v2.10 引入了本地文件解析、沙盒抓取模式、三种新抓取格式和四个新 SDK,同时修复了多个可靠性问题。
入选理由:v2.10 支持上传至 50MB 的本地文件并返回 LLM 友好的 Markdown、JSON 或摘要
Firecrawl 推出新工具,通过监控页面变化减少 90% 的 LLM 令牌消耗,提升 AI 数据处理效率。
入选理由:Firecrawl 的监控工具可减少 90% 的 LLM 令牌使用。
Firecrawl 已经加入 Vercel 市场,允许 Vercel 团队使用结构化网页数据来 powering AI 代理和应用程序,无需管理爬虫基础设施。
入选理由:Firecrawl 现已上线 Vercel 市场
WorkOS 联合 Cloudflare 和 Firecrawl 推出 auth.md,一种面向智能体的开放网络服务注册协议。
入选理由:auth.md 是首个专为智能体设计的 Web 服务注册开放协议
Firecrawl推出/scrape问题格式,能以100倍更少的token提供高质量、无幻觉的答案。
入选理由:Firecrawl的新功能可减少99%的token使用量,同时保持答案质量。
Firecrawl 在 Devtool Arena 的智能体搜索评测中排名第一,表明其在 AI 驱动网页处理方面具备领先能力。
入选理由:Firecrawl 获得 Devtool Arena 智能体搜索第一名。
Firecrawl的/scrape功能可从网页中提取精确文本、代码或表格,使用量减少100倍,适合AI代理。
入选理由:Firecrawl的/scrape功能能用少至1%的tokens获取所需内容。
Firecrawl 推出新 /parse API 端点,支持 PDF/DOCX/XLSX 文档解析为 Markdown 或 JSON,保留阅读顺序与表格结构,并提供零数据留存选项,底层由 Rust 实现、性能提升 5 倍。
入选理由:/parse 是面向 AI Agent 的文档结构化 API,专注输出干净、可编程的数据格式。
Firecrawl 推出 Lockdown Mode:一种仅使用本地缓存索引的 /scrape 模式,禁用所有外发请求,支持 API/SDK/CLI/MCP,且默认零数据留存。
入选理由:Lockdown Mode 完全避免外发网络请求,结果仅来自 Firecrawl 自有索引
Firecrawl 发布开源工作流仓库,提供一键初始化命令,支持浏览器爬取与自动化工作流,可直接集成到项目。
入选理由:使用 npx -y firecrawl-cli init --all --browser 一键初始化并启用浏览器爬取。
Firecrawl推出AI代理专用网络访问工具套件,包含搜索(/search)、爬取(/scrape)和交互(/interact)三个核心功能,已吸引超100万开发者使用。该工具旨在解决传统网页对AI代理不友好的问题。
入选理由:Firecrawl提供/search功能从网络发现新鲜相关资源
Firecrawl 宣布推出代理用户注册功能,声称未来将有超过 10 亿用户使用代理,但内容缺乏技术深度和实用信息。
入选理由:Firecrawl 正在推出代理用户注册功能,目标是吸引超过 10 亿用户。
该推文内容信息密度低,缺乏技术深度和实用性,仅提供了一个链接和部分社交媒体互动信息。
入选理由:推文内容缺乏技术细节和深度分析。
Firecrawl 推出了 Workflows 功能,通过 CLI 提供 10 多个可安装的技能,用于自动化执行深度研究、SEO 审计和网站设计克隆等重复性 Web 任务。
入选理由:Firecrawl Workflows 提供了 10 多个预设技能,涵盖深度研究、SEO 审计和设计克隆等场景。
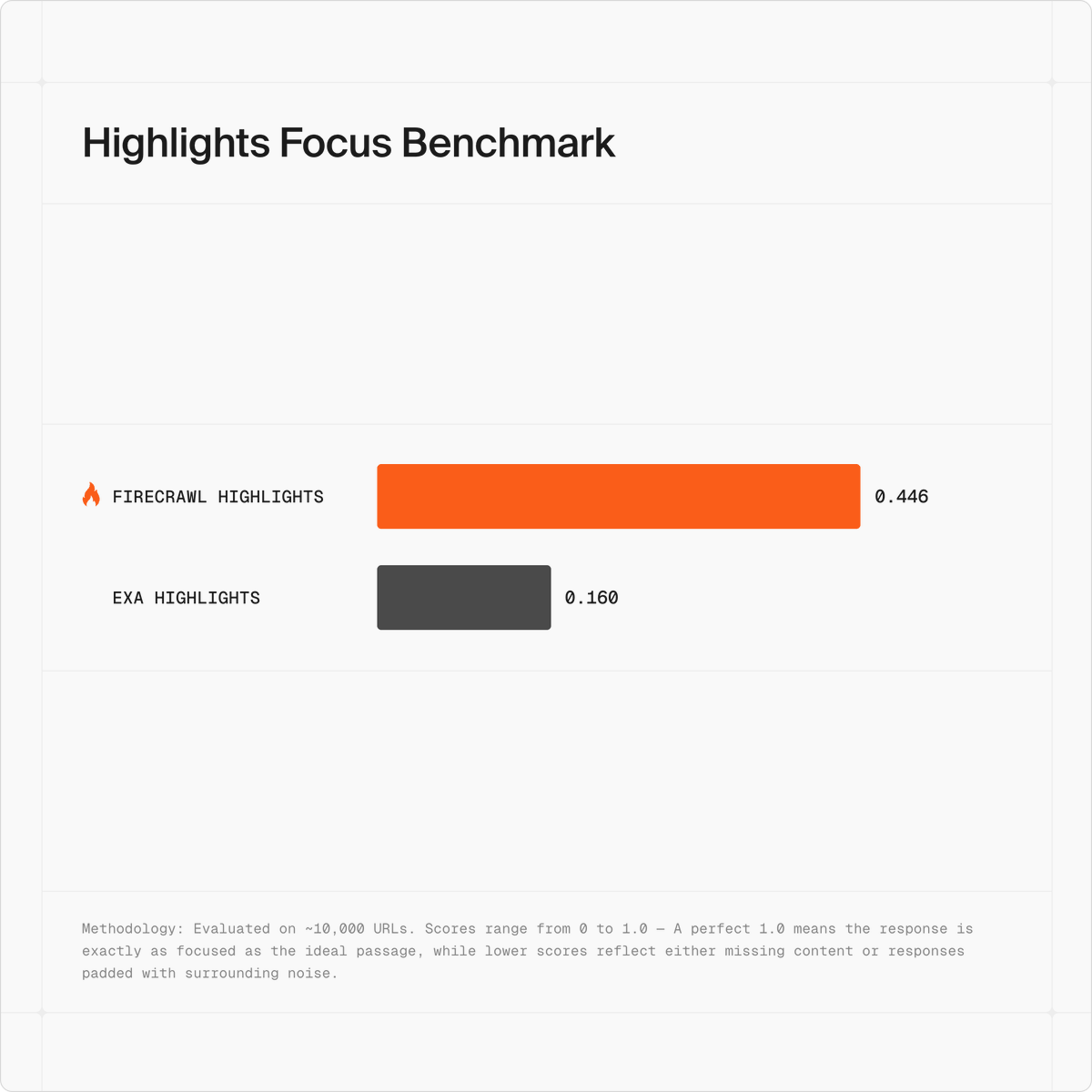
Firecrawl的高亮功能在10k URL测试集中表现优于Exa Highlights,但文章缺乏深度技术分析。
入选理由:Firecrawl高亮功能得分更高,表明匹配更精准。
Firecrawl的Highlights功能主要优化了/scrape,但也能处理在线PDF和通过/parse上传的文件。
入选理由:Highlights目前主要针对/scrape进行优化。
该推文仅含一条简短宣传语和跳转链接,无技术细节、机制说明或实质性内容,信息密度极低。
入选理由:未提供任何可验证的技术实现细节
Firecrawl 在其 /search 功能中新增域名包含(include)与排除(exclude)过滤器,支持按指定站点范围筛选爬取结果。
入选理由:新增 domain include/exclude 过滤能力,提升搜索结果精准度
这是一条关于Firecrawl产品的推广推文,声称能为AI代理提供干净的网络数据,但缺乏具体的技术细节和深度信息。
入选理由:Firecrawl是一个面向AI代理的网络数据清理工具
Firecrawl 在 X 平台发布简短宣传帖,称其可将任意文档解析为结构化数据,但未提供技术细节、原理、用例或性能指标。
入选理由:仅含产品口号与文档链接,无实质技术说明
Firecrawl公司发布agent orchestrators招聘启事,承诺投入100万美元招聘资金,应聘者需完成60道CTF挑战题。
入选理由:Firecrawl投入100万美元招聘agent orchestrators岗位
Firecrawl 宣布已抓取超过 80 亿网页,并列举了 1.25M+ 开发者、150K+ 企业、125K+ GitHub 关注和 2.5M+ npm/PyPI 下载等指标,强调仍在成长阶段。
入选理由:已抓取 80 亿+ 网页,显示抓取规模已达十亿级。
Firecrawl 官方祝贺 Chatbase 达成 1000 万美元 ARR 里程碑,并宣布 Firecrawl 为 Chatbase 提供网页数据抓取服务,用于 AI 智能体的入职培训和知识更新。
入选理由:Chatbase 达到 1000 万美元 ARR 里程碑
这是一条推特状态,主要宣传一个URL高亮功能,信息量和深度有限。
入选理由:Firecrawl发布了一个新的URL高亮工具。
Firecrawl 官方账号发布的一条简短社交媒体帖子,仅包含表情符号和链接,无具体技术内容可分析。
入选理由:Firecrawl 官方账号发布的一条简短社交媒体帖子,仅包含表情符号和链接,无具体技术内容可分析
Firecrawl将在纽约市开设一家咖啡馆。
入选理由:Firecrawl将在纽约市开设一家咖啡馆。
该文章为 Firecrawl 的社交媒体推广内容,未提供任何技术深度或实用信息,仅包含公司名称和链接。
入选理由:文章仅为 Firecrawl 公司的社交媒体发布,无具体内容