为 MHHS 扩容:Octopus Energy 如何实现 margin 数据工程 50 倍成本下降
Databricks1509 字 (约 7 分钟)
92
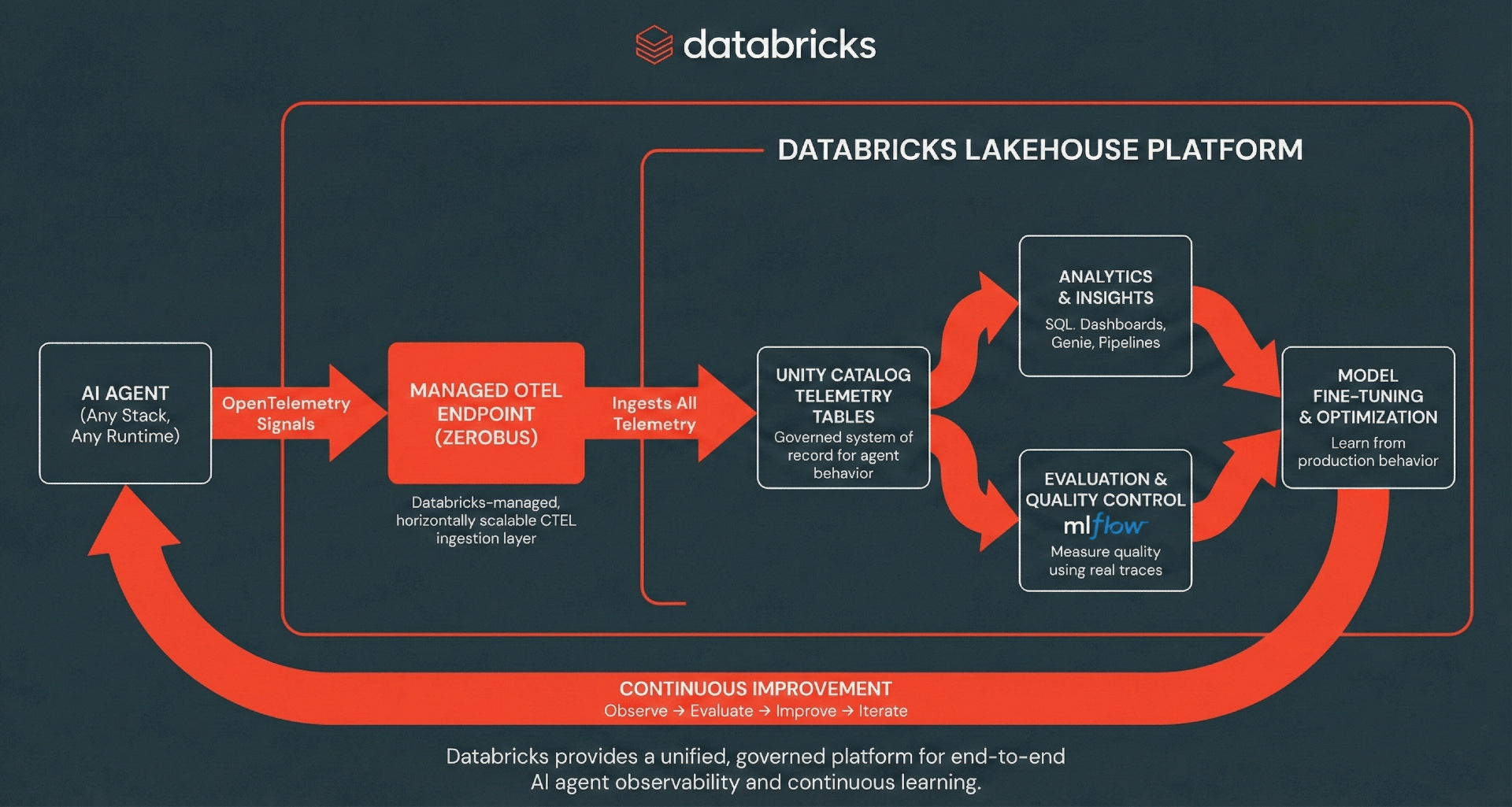
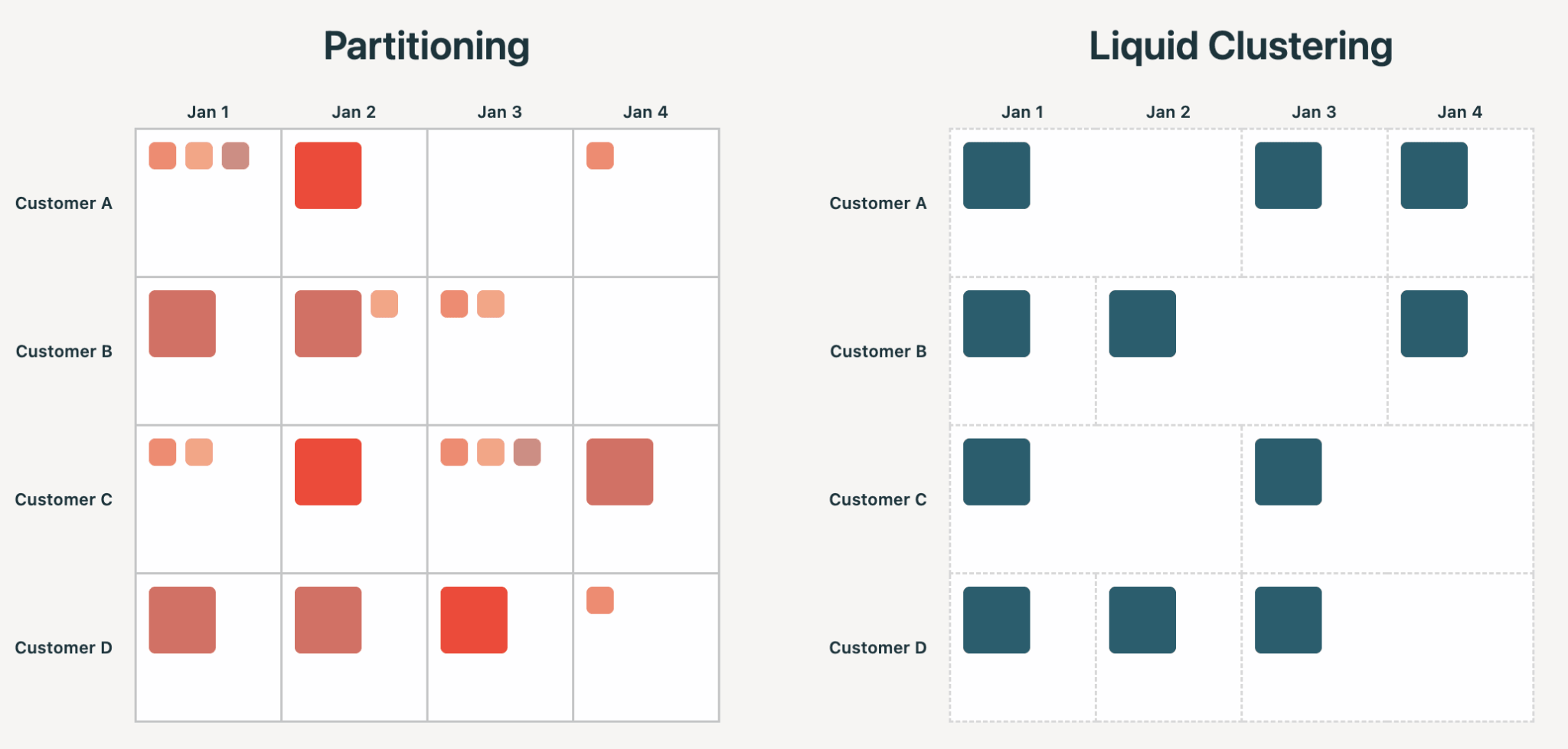
Octopus Energy 通过三流分离架构 + Delta Lake CDF 增量处理,应对 MHHS 政策带来的 48 倍数据增长,实现 50 倍成本下降,日处理行数从 250 亿降至 3 亿。
入选理由:采用三流分离架构(Settlement/Half-Hourly/Monthly)适配不同结算粒度,避免单体流水线重复处理未变更数据。
精选文章#Delta Lake#MHHS#数据架构重构#增量处理#能源数据英文