企业文档智能:从最小到语料库规模逐砖构建RAG系列
Towards Data Science5486 字 (约 22 分钟)
92
企业级RAG系统应聚焦文档理解与业务逻辑,而非堆叠模型和框架。简单的Python脚本往往比复杂生产系统更有效。
入选理由:多数企业RAG部署效果不佳,因基础解析和检索质量差。
精选文章#RAG#企业AI#文档智能#检索增强生成#LLM应用英文
概念
衡量向量间相似性的数学方法,在信息检索中广泛使用。
已跟踪 3 条高相关材料
最近变化
2026-05-22 · 多数企业RAG部署效果不佳,因基础解析和检索质量差。
为什么值得关注
Cosine Similarity 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
Enterprise Document Intelligence: A Series on Building RAG Brick by Brick, from Minimal to Corpus scale
Towards Data Science · 9.2 分
企业级RAG系统应聚焦文档理解与业务逻辑,而非堆叠模型和框架。简单的Python脚本往往比复杂生产系统更有效。
RAG Is Blind to Time — I Built a Temporal Layer to Fix It in Production
Towards Data Science · 8.5 分
文章揭示了RAG系统在时间感知上的缺陷,并提出通过添加时间层解决过时信息问题,提升知识库的时效性。
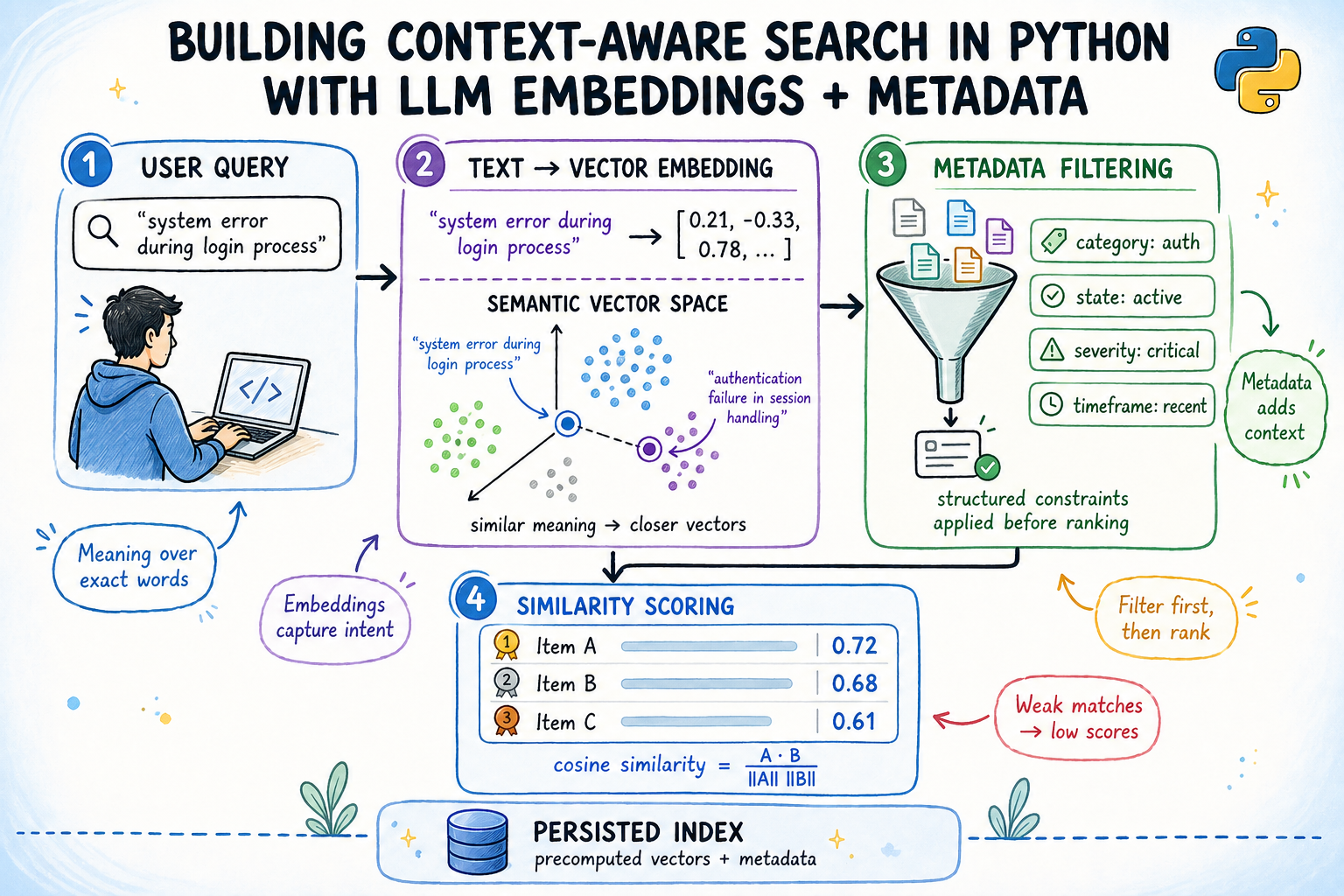
Building Context-Aware Search in Python with LLM Embeddings + Metadata
Machine Learning Mastery · 8.2 分
本文介绍如何结合LLM嵌入和元数据过滤,在Python中构建上下文感知的语义搜索引擎。
已收录 3 条与 Cosine Similarity 相关的内容,按评分排序。
企业级RAG系统应聚焦文档理解与业务逻辑,而非堆叠模型和框架。简单的Python脚本往往比复杂生产系统更有效。
入选理由:多数企业RAG部署效果不佳,因基础解析和检索质量差。
文章揭示了RAG系统在时间感知上的缺陷,并提出通过添加时间层解决过时信息问题,提升知识库的时效性。
入选理由:RAG系统无法识别文档时效性,导致过时内容优先显示
本文介绍如何结合LLM嵌入和元数据过滤,在Python中构建上下文感知的语义搜索引擎。
入选理由:使用本地预训练模型生成384维向量,无需API密钥即可实现语义搜索。