Top 7 Python库用于大规模数据分析处理
KDnuggets1233 字 (约 5 分钟)
90
这篇文章列出了并审查了七个顶级的Python库,包括PySpark、Dask、Polars、Ray、Vaex、Vaex-Java和Vaex-Python。
入选理由:PySpark is ideal for distributed ETL and cluster-scale pipelines.
精选文章#Python#大数据处理#库英文
产品
别名:Spark
用于大规模数据处理的开源集群计算框架。
已跟踪 8 条高相关材料
最近变化
2026-06-10 · Lightning Engine 提供高达 4.9 倍于标准 Spark 的性能提升。
为什么值得关注
Apache Spark 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
Top 7 Python Libraries for Large-Scale Data Processing
KDnuggets · 9 分
This article lists and reviews seven top Python libraries for large-scale data processing, including PySpark, Dask, Polars, Ray, Vaex, Vaex...
Apache Spark Real-Time Mode for Gaming: A Better Way to Do Real-Time Sessionization
Databricks · 8.7 分
以 Apache Spark Real-Time Mode 和 transformWithState 为核心,为游戏实时会话化提供统一、低延迟(亚秒级)架构,替代 Flink 或自研方案,支持百万级玩家的个性化、推荐与内容调度。
Accelerating data lakes: Optimizing Apache Iceberg and Spark with gcs-analytics-core
Google Cloud Blog · 8.7 分
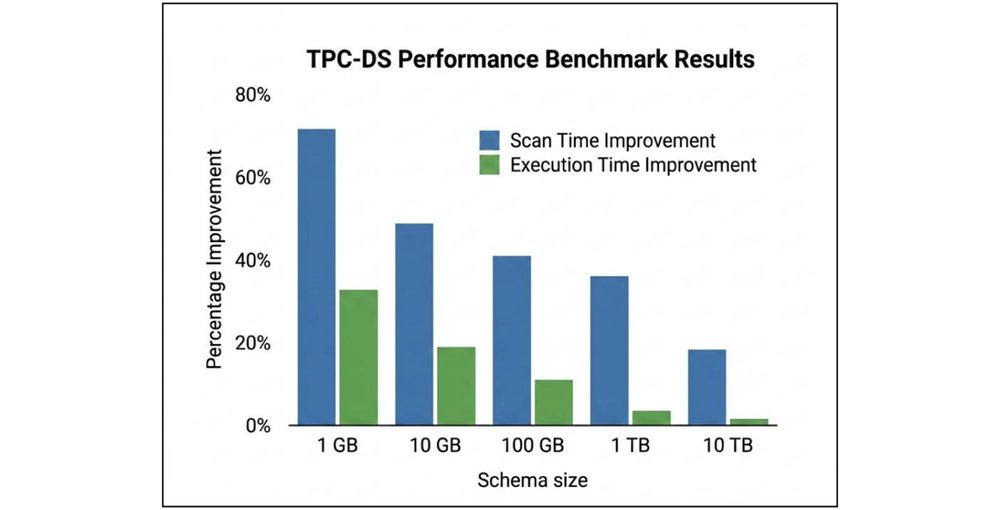
Google Cloud 发布 gcs-analytics-core,一个用于优化 Apache Iceberg 和 Spark 在 GCS 上性能的开源 Java 库,通过并行 I/O 和智能 Parquet 预取等技术提升读操作效率,TPC-DS 基准测试显示性能提升显著。
已收录 8 条与 Apache Spark 相关的内容,按评分排序。
这篇文章列出了并审查了七个顶级的Python库,包括PySpark、Dask、Polars、Ray、Vaex、Vaex-Java和Vaex-Python。
入选理由:PySpark is ideal for distributed ETL and cluster-scale pipelines.
以 Apache Spark Real-Time Mode 和 transformWithState 构建统一、低延迟(亚秒级)架构,替代 Flink 或自研方案,支撑百万级玩家的个性化、推荐与内容调度。
入选理由:使用 transformWithState + Real-Time Mode 实现单引擎统一架构,输入处理与定时触发均可达亚秒级精度。
Google Cloud 发布 gcs-analytics-core,一个用于优化 Apache Iceberg 和 Spark 在 GCS 上性能的开源 Java 库,通过并行 I/O 和智能 Parquet 预取等技术提升读操作效率,TPC-DS 基准测试显示性能提升显著。
入选理由:gcs-analytics-core 是一个开源 Java 库,用于优化 GCS 上的 Apache Iceberg 和 Spark 工作负载。
Lightning Engine 提升 Apache Spark 性能达 4.9 倍,通过原生执行和优化连接器实现。
入选理由:Lightning Engine 提供高达 4.9 倍于标准 Spark 的性能提升。
Google Cloud 推出 Managed Spark 集群的多项增强功能,包括 Lightning Engine、Flexible VMs 和 Gemini-powered extensions,显著提升性能与灵活性。
入选理由:Lightning Engine 可使 Spark 性能提升最高 4.9 倍。
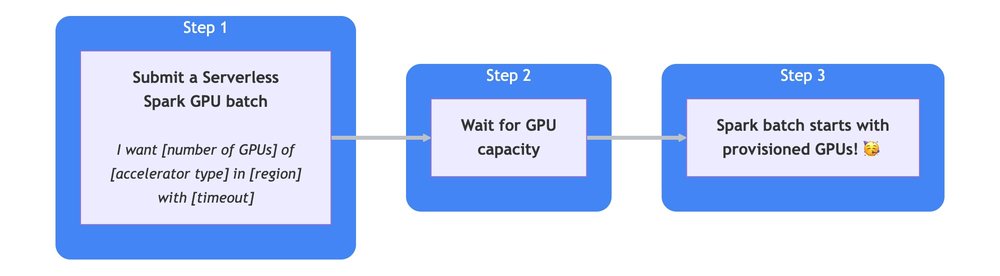
Google Cloud宣布Serverless Managed Service for Apache Spark runtime 3.0,优先考虑速度、简单性和可靠性。此更新将启动时间减少了75%,提高了GPU可获得性,并支持Apache Spark 4.x创新。
入选理由:Serverless Managed Service for Apache Spark runtime 3.0 reduces startup times by 75%.
Apache Kafka 正在向云原生架构转型,通过存储去耦合改变了经济模式,降低了运营成本,提高了灵活性。
入选理由:存储去耦合使 Kafka 经济模式发生变化,将成本从基础设施预配转移到云 API 使用,减少了不高效的消费者访问模式带来的运营费用。
本文介绍了PySpark的基本概念和核心机制,帮助初学者理解如何用Python处理大规模数据。
入选理由:PySpark是Apache Spark的Python API,用于分布式数据处理。