Figma数据管道从多日延迟升级至实时

TL;DR · AI 摘要
Figma通过将数据管道从每日全量同步升级为增量同步,将分析数据延迟从数天降至实时,年节省数百万美元成本。
核心要点
- 2023年Figma全量同步任务需6小时,最大表延迟数天,专用数据库副本年成本超百万美元。
- 增量同步方案仅处理变更数据,避免全表拷贝,延迟从数天降至实时。
- FigJam、Dev Mode等产品扩展使数据量激增,原架构无法支撑实时分析。
结构提纲
按章节快速跳转。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- Figma数据管道升级
- 问题背景
- 产品扩展
- 原始架构
- 全量同步
- 解决方案
- 增量同步
- 成果
- 延迟实时化
- 成本节约
金句 / Highlights
值得收藏与分享的关键句。
Figma原架构每日全量同步1000万行表,仅50行变更却拷贝全部,导致6小时任务和数百万美元年成本。
2021-2025年FigJam、Dev Mode和多语言扩展使数据量激增,原管道无法处理实时分析需求。
增量同步方案避免全表拷贝,仅处理变更数据,将延迟从数天降至实时。
标题:如何将 Figma 数据管道从多日延迟升级至实时处理
URL 来源:https://blog.bytebytego.com/p/how-figma-upgraded-data-pipeline
发布日期:2026-05-12T15:31:03+00:00
每个评论背后都运行着一个专为场景设计的独立上下文引擎。它是决定代理在生成任何内容前实际看到什么的关键层。
专为场景设计的原因在于:代码审查所需的上下文与聊天或自动补全截然不同——需要为每次审查精准整合相关上下文片段。
该引擎从四个维度整合输入:
- 沙盒环境。克隆的仓库、依赖分析、多仓库上下文及针对变更运行的 linters/SAST(ESLint、Semgrep)。
- 审查指令。您的编码规范、AGENTS.md 文件、路径规则、AST 作用域规则、语气及过往审查的总结经验。
- 集成服务。MCP 工具、问题追踪系统(Jira、Linear)、CI/CD 失败记录及网络搜索。
- 大型语言模型。在 OpenAI 和 Anthropic 间进行路由调度。
2020 年,Figma 的数据同步架构仅需五行代码逻辑:一个每日运行的定时任务查询数据库表的所有行,将其存入 S3,再加载至 Snowflake。
结构简单、逻辑清晰,且运行良好。
三年后,这种简单性却让 Figma 每年损失数百万美元,其分析团队查询的数据已是数日之前的旧数据。
需要说明的是,Figma 是一款协作式设计平台,团队可实时共同创建、原型设计并迭代用户界面。如果您使用过现代应用或网站,有很大概率其界面是在 Figma 中设计的,或 Figma 参与了设计流程。
自早期以来,产品已远超核心设计工具范畴:2021 年推出 FigJam 实现协作白板功能;2023 年推出 Dev Mode 促进设计师与开发者的协作;Figma Make 引入 AI 驱动的应用原型设计。公司还针对巴西、日本、西班牙和韩国市场进行了本地化。
所有这些增长导致 Figma 系统每日处理的数据量与复杂度呈爆炸式增长。
本文将探讨 Figma 在增长过程中面临的数据管道挑战,以及工程团队如何应对这些挑战。
*免责声明:本文基于 Figma 工程团队公开分享的信息撰写。如发现不准确之处,请在评论中指出。*
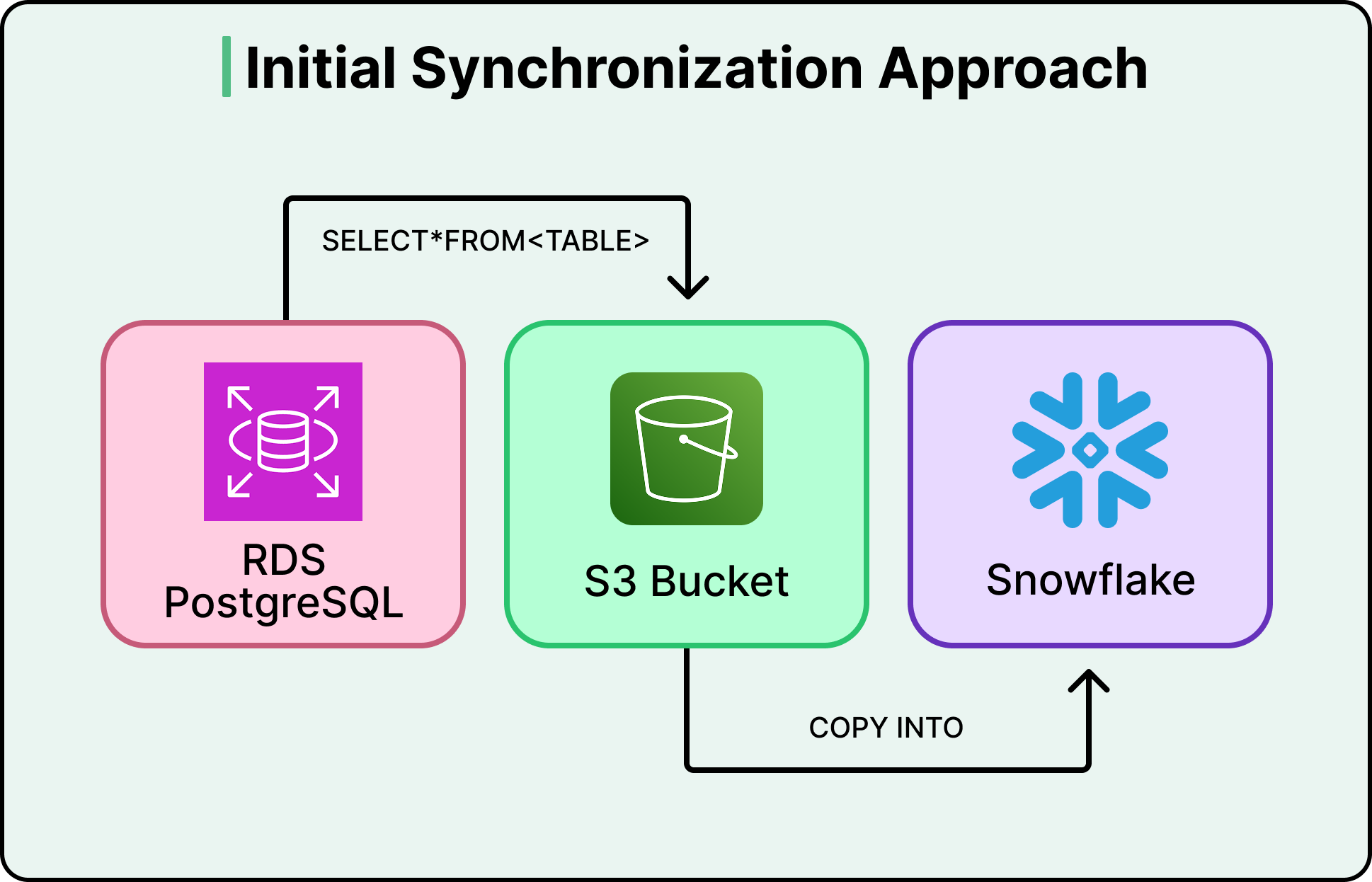
Figma 的原始数据管道采用全量同步(full sync)模式。每次运行会复制数据库表的全部内容,无论实际变更量多少。即使表中有 1000 万行数据,当日仅 50 行变更,管道仍会复制全部 1000 万行。当表规模较小时,这种方式快速且成本低廉。
Figma 的生产数据库部署在 Amazon RDS PostgreSQL 上,需实时处理用户请求。每次用户打开文件、保存变更或加载项目时,数据库均需响应。在相同数据库上运行大型分析查询(如计算公司级 KPI 或分析百万级用户的使用趋势)会与实时流量竞争资源,导致产品性能下降。因此,Figma 与大多数同规模公司一样,维护了一个独立的 Snowflake 分析数据仓库——专为处理这类大规模复杂查询设计。但问题在于:数据需从生产库传输至分析仓库,而这一传输过程即为同步管道。
但 Figma 的表规模并未保持小型。
如前所述,2021 至 2025 年间,Figma 推出了 FigJam、Dev Mode、Figma Make,并扩展了巴西、日本、西班牙和韩国的本地化支持。用户基数迅速增长,数据量也随之激增。
至 2023 年,每日同步任务耗时约六小时,最大表的同步甚至需数日完成。更糟的是,管道需专用数据库副本以处理导出负载,避免影响生产流量。这些副本每年成本高达数百万美元。
Figma 评估了三种解决方案:
- 维持现有系统:但同步延迟和副本成本已不可持续。
- 通过增加并行度加速全量复制:但这只是权宜之计,无法随表规模扩大而扩展。
- 重构整个管道。
团队选择了重构,采用增量同步方案。不再每次复制整表,而是仅捕获变更内容并应用至目标端。概念简单,但实现复杂。
增量同步颠覆了原有模式:不再询问“当前表的完整状态是什么?”,而是聚焦“自上次同步后发生了哪些变更?”。仅需传输并应用自上次同步以来的新增、更新和删除操作。例如,若表含 1000 万行数据,当日仅 50 行变更,则仅需传输 50 行而非 1000 万行。
变更数据捕获(Change Data Capture,简称 CDC)是实现这一功能的核心机制。每个数据库都会维护一个内部日志,记录所有写入操作,称为预写日志(write-ahead log),用于自身崩溃恢复。CDC 读取该日志并将其转换为变更事件流。这一过程不会给数据库增加额外开销,而是复用数据库已有的记账机制。
下图展示了 CDC 的工作原理:
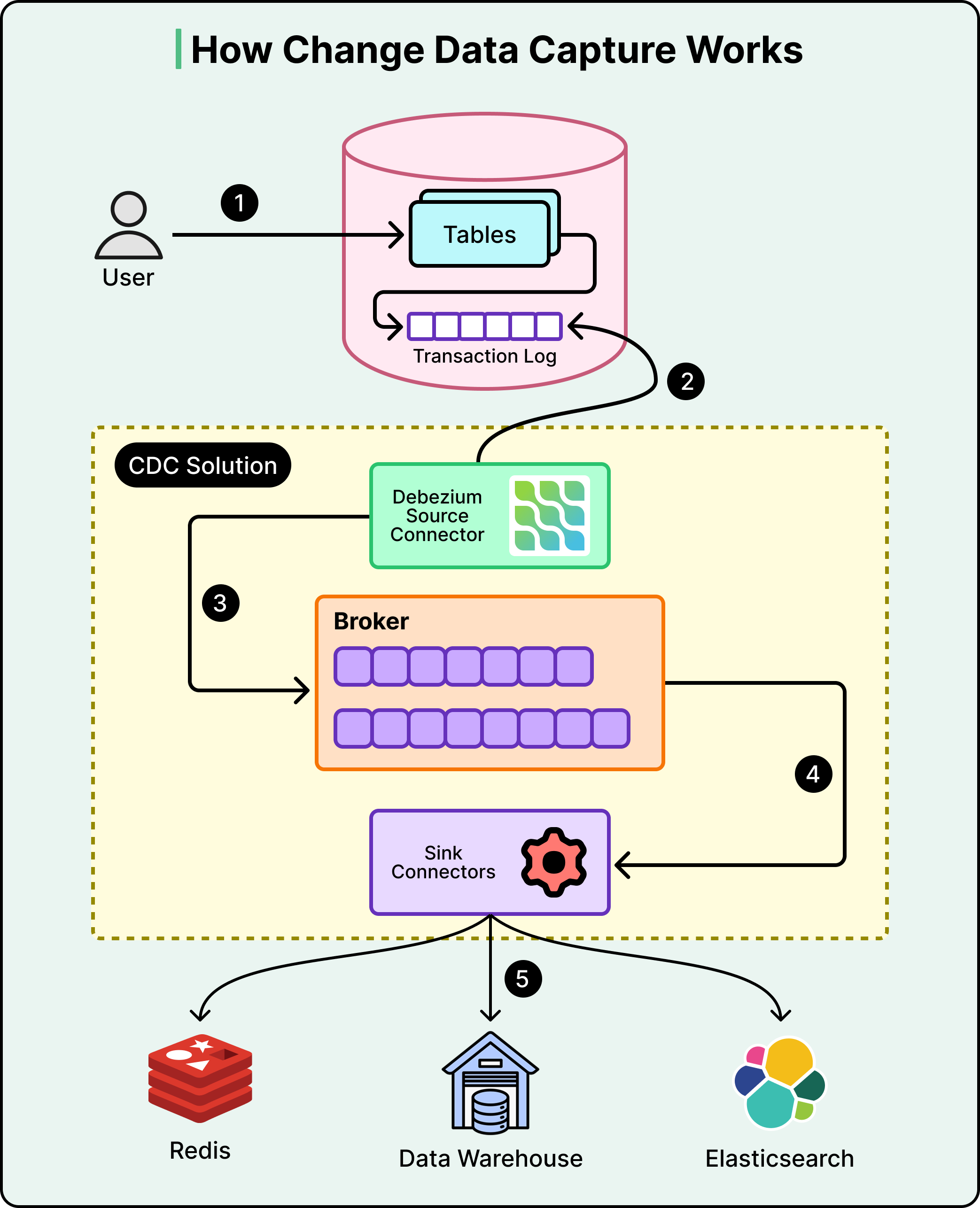
这些变更事件需要传输目的地。Figma 使用 Kafka 作为分布式流处理平台,充当生产数据库与 Snowflake 之间的缓冲层。
当 CDC 捕获变更时,会将事件发布到 Kafka 主题(每个表对应一个主题)。Snowflake 则按自身节奏消费这些主题。这种解耦确保生产数据库无需关心 Snowflake 是否在线、繁忙或滞后——它只需将事件写入 Kafka,Kafka 会暂存事件直至消费者就绪。若 Snowflake 因维护停机,数据不会丢失。事件会在 Kafka 中排队,待 Snowflake 恢复后继续处理。
需要注意的是,该流仅捕获启动监听后的变更,不包含表的完整历史记录。因此在第一天,目标数据库为空,变更流仅记录当前发生的变更。这就需要一个起始点。
这个起始点即为快照。在此方案中,我们会在特定时间点对表进行全量复制,随后从该时间点前的变更开始应用。时间点的选择至关重要。例如,假设 Figma 在凌晨 2:00 启动快照导出,导出耗时两小时。在此期间用户仍活跃操作,记录持续创建、更新和删除。快照于 4:00 完成,但仅反映 2:00 的表状态。若变更流在 4:00 开始捕获事件,2:00 至 4:00 的所有变更将丢失。目标表会缺失两小时数据,且无错误提示。为避免此问题,Figma 确保 Kafka CDC 流的起始偏移量早于快照时间戳。这种重叠意味着部分事件会与快照内容重复,但重复数据可在合并步骤中处理。缺失数据则无法挽回。
Figma 还需决定采用现成解决方案还是自建架构。他们认真评估了供应商选项,发现三大问题:
- 通用 CDC 工具无法利用 Amazon RDS 特定 API(例如直接将快照导出至 S3,无需维护独立数据库副本)。
- 供应商在 Figma 规模下的定价高达自建方案的 5 至 10 倍。
- 评估的工具无法可靠处理 Figma 持续增长的数据量。
因此,他们基于底层组件构建了数据管道:
- Amazon RDS 负责将快照导出至 S3。
- Kafka 流式传输 CDC 事件。
- Snowflake 存储过程执行增量合并(即应用变更流使目标表保持最新)。
- 合并作业按可配置周期运行,默认每三小时一次。
下图展示了该架构:
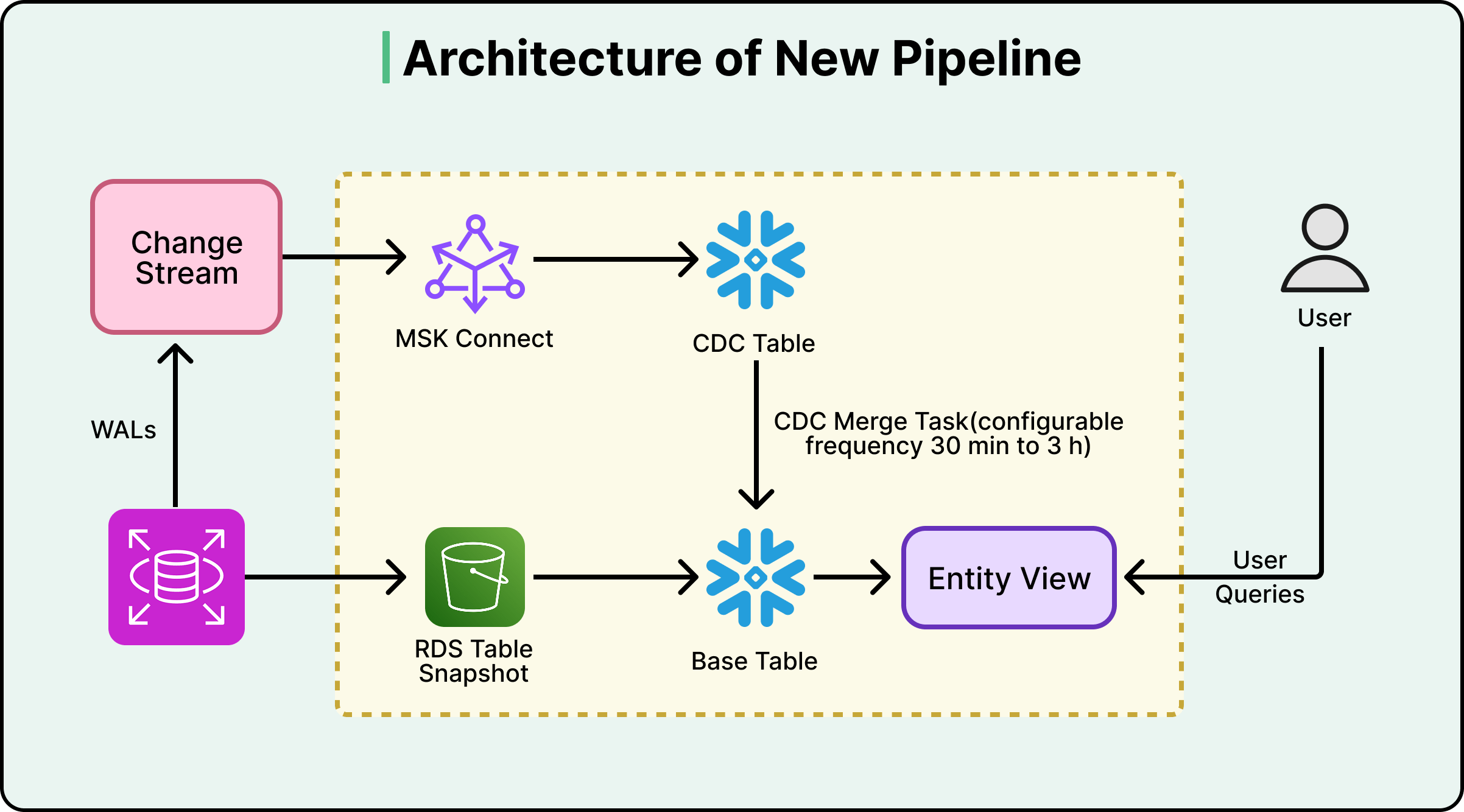
默认三小时周期是经过权衡的设计选择,而非限制。更频繁的合并意味着数据更新更及时,但 Snowflake 计算成本更高。Figma 允许团队在关键场景覆盖默认值。例如,其计费流水线采用 30 分钟合并周期,每个团队仅为其实际所需的数据新鲜度付费。
构建管道仅完成一半工作,另一半在于确认其是否正常运行。
数据管道可能以多种不触发错误的方式失效,例如:
- 快照导出过程部分失败
- CDC 连接器配置错误
- 源端意外输出非预期数据格式
这些问题不会导致管道崩溃,但会产出错误数据。分析仓库中的错误数据将导致错误的 KPI、错误的商业决策,以及整个数据平台信任度的缓慢流失。
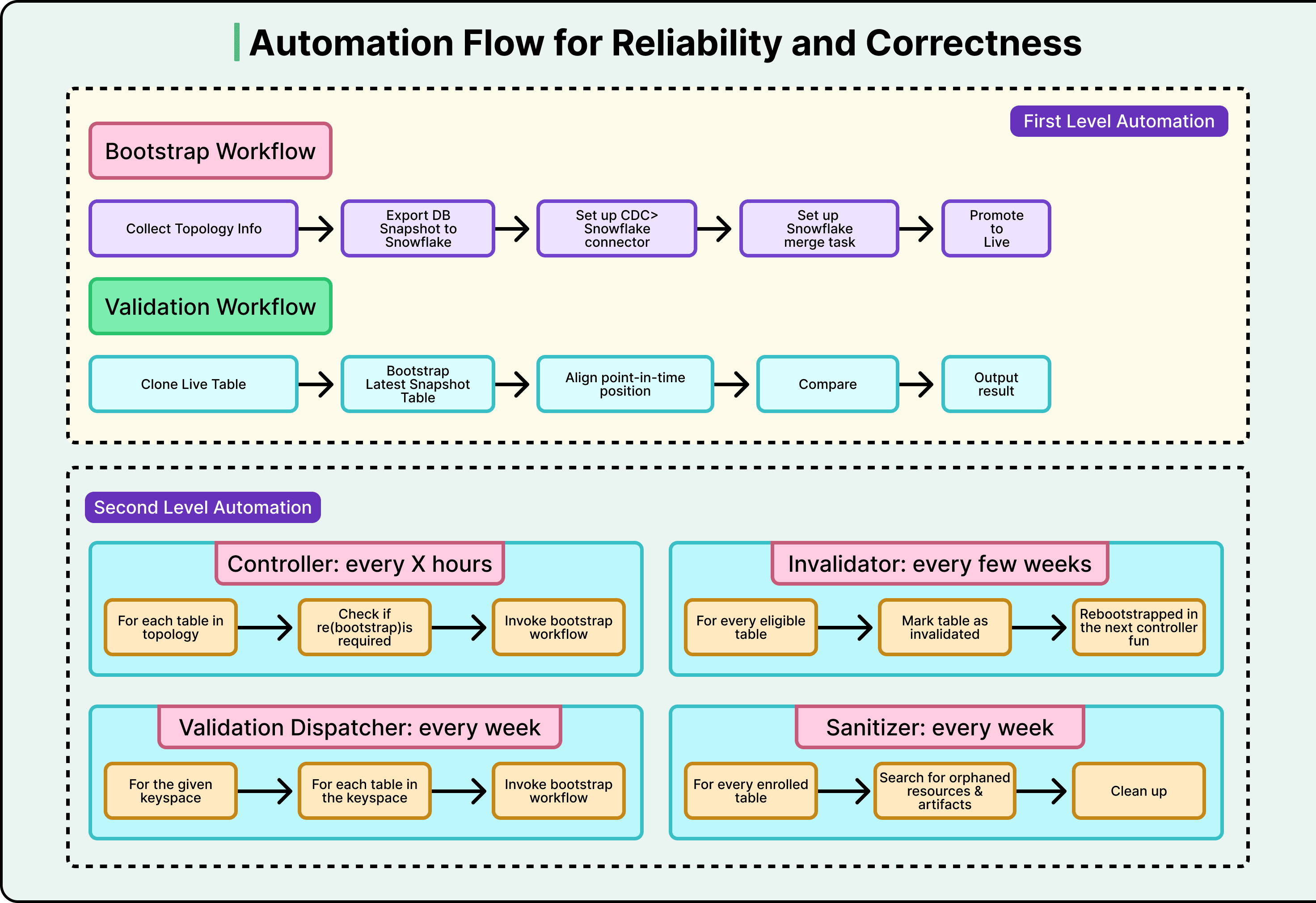
Figma 的应对方案极为严格:他们构建了专用验证流程,该流程会克隆实时基础表,独立执行完整初始化流程至临时模式,通过 CDC 数据将两份副本同步至同一时间点,随后进行逐单元对比。该流程每周对管道中的每张表运行一次。多数团队仅满足于行数检查或抽样,而 Figma 对其分析仓库的正确性要求,等同于对生产数据库的严格保障。
这种方案之所以有效,核心在于独立性。如果主数据管道中存在某个缺陷(例如CDC连接器静默丢弃特定类型的更新事件),任何复用相同管道路径的校验都会继承该缺陷。损坏的数据会与损坏的校验结果匹配,系统看似一切正常。而Figma通过独立流程启动完全隔离的副本并进行比对,确保单条路径的错误无法绕过另一条路径的校验。
Figma还通过版本化除最终用户视图外的所有初始化产物,构建了零停机重启动能力。当数据模式演进或需全量重启动时,新版本会并行构建,并通过原子视图更新机制无缝切换。实时查询始终不受干扰。
支撑整个体系的另一关键要素是自动化。Figma将自动化分为两级:
- 一级自动化:执行核心操作。只需指定表名,即可触发初始化或校验流程,并在异常时自动告警。
- 二级自动化:位于上层,决定触发时机。控制器工作流每数小时扫描需接入的新表;调度器工作流每周自动触发各表的校验。
系统高度自运行,开发者仅在告警触发时介入。
早期成效显著:在预演环境测试首周,自动化重启动流程便捕获了严重故障模式。若未被拦截,该问题将导致全站故障持续至少20分钟。旧系统依赖每日cron任务且无自动化校验,根本无法发现此类问题。
数据印证了改进效果:
- 数据新鲜度从30多小时缩短至3小时以内,支持配置至分钟级
- 管道处理表规模达旧系统的十倍以上,性能稳定可预测
- 消除专用导出副本带来年节省数百万美元
- 上线前后运维实现零重大事故
超越性能提升,重构还解锁了新能力:
例如,开发者可通过按需同步CLI工具在常规调度外即时触发同步;CDC数据现向终端用户开放,支持查询任意实体的完整变更历史(而不仅是当前状态)。故障响应时,"展示该用户记录过去48小时的所有变更"这类问题可分钟级解决。
然而,该项目投入了大量时间、人力与资源。
新系统远比每日cron任务复杂。Figma通过激进的自动化与校验弥补复杂度,但这本身又增加了额外复杂性。在Figma的规模下,这种权衡是值得的。
参考文献: