NVIDIA Cosmos 3、Nemotron 3 Ultra 和 RTX Spark 发布

TL;DR · AI 摘要
NVIDIA发布Cosmos 3(omnimodal world models)、Nemotron 3 Ultra(550B LLM)和RTX Spark,推动开放物理AI,其中Cosmos 3在Text2Image和Image2Video上达到SOTA。
核心要点
- Cosmos 3 采用Mixture-of-Transformers架构,16B/64B模型在Text2Image和Image2Video上达到SOTA,支持J
- Nemotron 3 Ultra 是550B参数的开放权重LLM,推理速度达300+ tok/s,成为美国SOTA开放模型。
- RTX Spark 个人电脑提供1 petaflop算力,与Microsoft和OpenClaw合作,推动物理AI应用。
结构提纲
按章节快速跳转。
Cosmos 3 是统一语言、图像、视频、音频和动作的omnimodal world models,采用Mixture-of-Transformers架构。
Nemotron 3 Ultra 550B参数模型推理速度达300+ tok/s,成为美国SOTA开放权重LLM。
RTX Spark 提供1 petaflop算力,与Microsoft和OpenClaw合作,推动物理AI应用。
Cosmos 3 包含base Nano (16B)和Super (64B)模型,使用autoregressive reasoner和diffusion generator。
Nemotron 3 Ultra 在开放评估中领先,服务速度远超DeepSeek/Kimi类模型。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- NVIDIA 2026 新模型发布
- Cosmos 3
- Mixture-of-Transformers架构
- Text2Image SOTA
- Image2Video SOTA
- Nemotron 3 Ultra
- 550B参数
- 300+ tok/s速度
- 美国SOTA开放模型
- RTX Spark
- 1 petaflop算力
- Microsoft合作
- OpenClaw合作
金句 / Highlights
值得收藏与分享的关键句。
Cosmos 3 在Text2Image和Image2Video上达到SOTA,使用structured JSON prompts,可由外部提示上采样或自身reasoner驱动。
Nemotron 3 Ultra 推理速度达300+ tok/s,远快于大型DeepSeek/Kimi类模型。
NVIDIA 通过Cosmos Coalition与Runway等伙伴建立开放生态系统,提供权重、代码、数据集和微调配方。
标题: [AINews] NVIDIA Cosmos 3、Nemotron 3 Ultra 和 RTX Spark
URL 来源: https://www.latent.space/p/ainews-nvidia-cosmos-3-nemotron-3
发布日期: 2026-06-02T03:28:10+00:00
今日播客嘉宾 一年多前曾负责 NVIDIA Cosmos 项目,讨论视频生成和世界模型的训练。恰逢其时,Cosmos 3 今日发布,它通过 Mixture-of-Transformers 架构 统一了语言、图像、视频、音频和动作,该架构将自回归推理器与扩散生成器配对:
- base Nano (16B: 8B 推理塔 + 8B 生成塔)
- Super (64B: 32B 推理塔 + 32B 生成塔) 模型,以及
- 为 Text2Image 和 Image2Video 优化的 Super 微调模型,它们现在是 新的 SOTA 开放权重图像生成和视频生成模型,仅 略逊于 Nano Banana 2
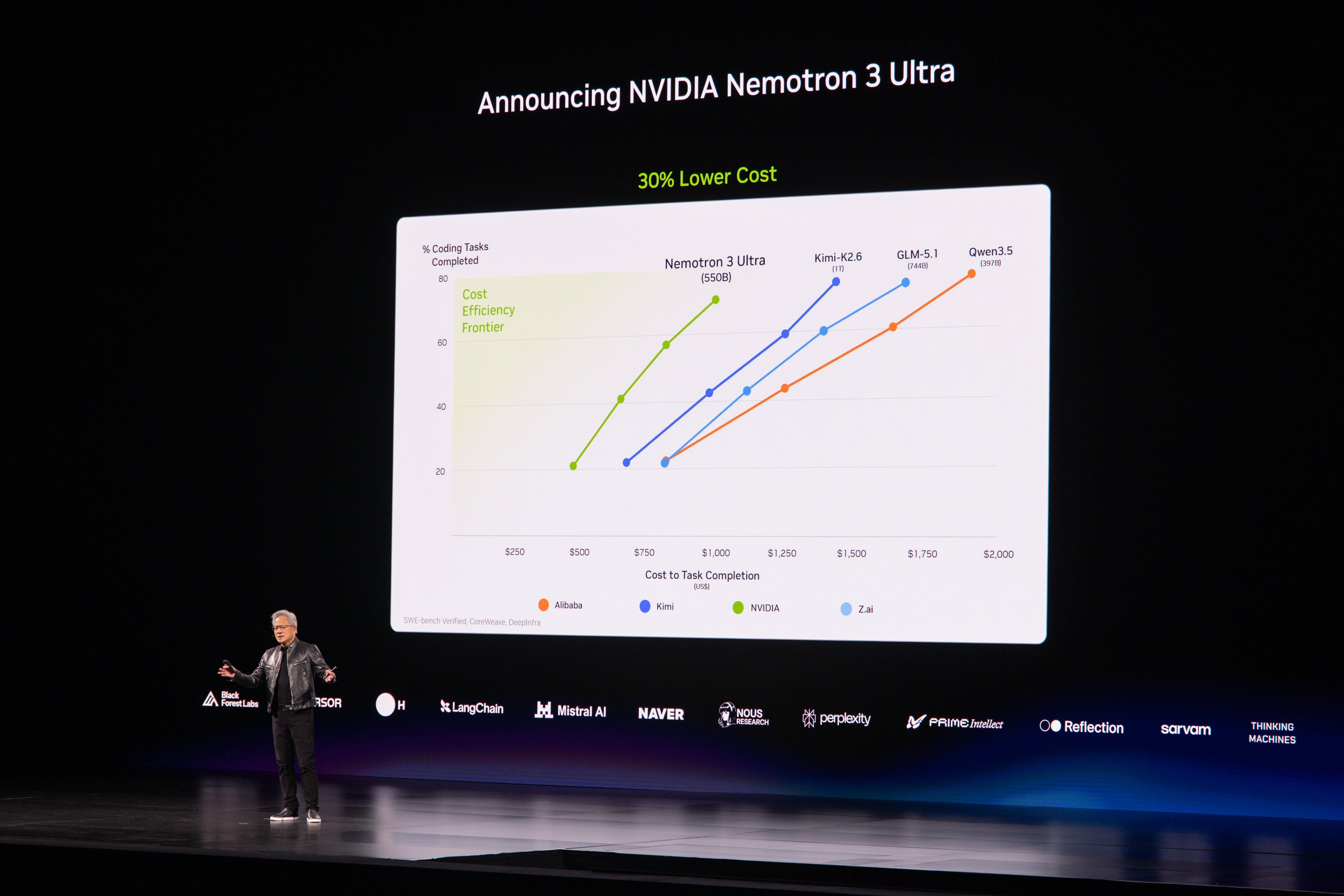
在台湾的 Computex 上,Jensen 还带来了 Nemotron 3 Ultra,这是他们的 550B-A55B 模型,是一款效率极高/ 快速 的开放权重 LLM,是新的美国 SOTA:
最后,RTX Spark 个人电脑 1 petaflop 超级芯片,与 Microsoft、OpenClaw 和 Hermes Agent 作为发布合作伙伴进行了预览(详细分析 见此)
2026 年 5 月 30 日至 6 月 1 日的 AI 新闻。我们检查了 12 个 subreddits、544 条 Twitter 以及没有进一步的 Discord。AINews 网站 允许您搜索所有过往期。提醒一下,AINews 现在是 Latent Space 的一部分。您可以 选择加入/退出 电子邮件频率!
NVIDIA 的 Cosmos 3、Nemotron 3 Ultra 以及开放物理 AI 的推进
- NVIDIA 的开源周: NVIDIA 通过 Cosmos 3(一套面向物理 AI 的开源全模态世界模型)主导了开放模型讨论,并宣布了 Nemotron 3 Ultra——一款 550B 开放权重模型,多位用户称其为迄今为止美国最强的开放模型。Cosmos 3 被定位为全栈发布——权重、代码、数据集和微调方案——NVIDIA 还与包括 Runway 在内的合作伙伴共同推出了 Cosmos 联盟,以构建世界模型的开放生态系统 @NVIDIAAI 生态背景,@runwayml 联盟公告,@kimmonismus Cosmos 主题,@ClementDelangue 关于 NVIDIA 的 HF 足迹。
- Cosmos 3 的技术意义: 除机器人相关讨论外,更具体的细节是 Cosmos 3 通过单一 Mixture-of-Transformers 设计统一了 语言、图像、视频、音频和动作,该设计将 自回归推理器 与 扩散生成器 配对。Artificial Analysis 表示 Cosmos 3 在其 Text-to-Image 和 Image-to-Video 排行榜上均位列 开放权重模型第一,并指出生成器使用 结构化 JSON 提示,可通过外部提示上采样框架或自身推理分支驱动。此外,NVIDIA 的硬件 + 软件推进还扩展到 OpenMDW 框架的采用及与 fal 等平台的合作伙伴生态系统集成 @ArtificialAnlys,@fal。
- Nemotron 3 Ultra 的反响: 社区对 Nemotron 3 Ultra 的反应异常强烈,这是一次全新的开放发布。用户强调了其能力和服务特性,包括声称它已在某些开放评估中领先,并可能在某些配置下以 300+ tok/s 速度运行——远快于 DeepSeek/Kimi 级别模型 @scaling01,@ctnzr,@caspar_br。还有一些技术讨论指出,Nemotron 似乎比 Kimi K2 / DeepSeek V4 等同行 稀疏度更低——约 ~10% 激活 对比 ~3%——这可能影响其经济性和行为 @eliebakouch。
MiniMax M3、Qwen3.7-Plus 和 JetBrains Mellum2 拓展开放代理模型领域
- MiniMax M3 的发布是当天最大的模型发布:M3 被介绍为一个开源权重的多模态智能体/编码模型,具有 1M 上下文、原生多模态 和具有竞争力的智能体基准测试。在发布合作伙伴中重复的头条数据是 59.0% SWE-Bench Pro、66.0% Terminal Bench 2.1 和 74.2% MCP Atlas@MiniMax_AI, @PBDTokenRouter, @kimmonismus。多个基础设施供应商在发布当天就提供了支持——Novita、Vercel AI Gateway、Cloudflare AI Gateway、OpenClaude、Flowith 等——表明生态系统采用了异常快速的采纳速度 @MiniMax_AI on Novita, @rauchg, @gitlawb。
- 基准测试与实际体验参差不齐:M3 因前端生成、视觉/游戏任务和性价比而受到赞誉,并排演示展示了强大的单次 UI/游戏输出,在 Next.js 智能体评估中也取得了显著的基准排名 @notjazii, @lostinlatencyX, @rauchg。但几位评估者也报告了 高 token 消耗、冗长的自检循环 以及在长任务中偶尔出现的 需求漂移,使得 M3 看起来更像是一个“质量优先,效率后置”的模型 @ZhihuFrontier review, @teortaxesTex skepticism。
- Qwen3.7-Plus:阿里巴巴推出了 Qwen3.7-Plus,这是一个 多模态交互式混合智能体,统一了 GUI 和 CLI 操作、视觉推理、编码和搜索增强问答。它通过阿里云 Model Studio API 可用,并迅速被添加到如 Cline 等工具中 @Alibaba_Qwen launch, @cline。此次发布强化了趋势:开放的亚洲实验室不再仅发布“聊天模型”,而是推出完整的 智能体能力多模态系统。
- JetBrains Mellum2:JetBrains 发布了 Mellum2,这是一个 12B MoE 模型,具有 2.5B 活跃参数,在约 11T tokens 上训练,并通过 RLVR 进行后训练,提供 base / SFT / RL 检查点 和技术报告 @nv_pavlichenko, @jetbrains。其目标细分领域尤为有趣:为 路由、RAG、子智能体和 IDE 使用 提供 超低延迟推理,并立即集成到 vLLM 中 @vllm_project。这看起来更像是一个针对开发者工作流程的“小型快速开源模型”策略,而非追求基准测试的前沿发布。
智能体、沙盒、内存和搜索正成为真正的产品表面
- 栈正从模型调用转向智能体运行时:多个发布汇聚了这样一个观点:主要的工程杠杆现在在于 框架 而非模型。Perplexity 的“Search as Code” 是最清晰的例子:与迭代的搜索工具调用不同,模型针对搜索 SDK 编写 Python,从而实现自定义排名管道、索引上的 map-reduce、批处理、聚合和更低的 token 开销。Perplexity 报告称,使用此架构,其内部 WANDR 基准测试从 0.152 跳跃到 0.386 @perplexity_ai, @AravSrinivas。
- 托管智能体 + 沙盒正成为标准:Google 详细介绍了 Gemini API 中的托管智能体,其中单个 API 调用可以启动一个智能体,该智能体能够推理、编写/运行代码、管理文件,并在托管的 Linux 沙盒 中操作 @_philschmid, @GoogleAIStudio。LangChain 也推动了类似理念,围绕 Deep Agents、Context Hub 和 LangSmith Sandboxes/Engine,强调持久上下文、智能体生命周期工具和自动化故障排查 @LangChain, @hwchase17。
- 内存仍然是缺失的原语:一个反复出现的抱怨是,巨大的上下文窗口仍然无法解决 跨会话内存。HydraDB 上的一个线程认为,“RAG + 手动上下文注入”被错误地命名为内存,而实际的持久会话知识仍然服务不足 @kimmonismus。相关研究线程指出可重用的上下文管理策略,如 AdaCoM,它通过强化学习训练一个独立的 LLM,以修剪/保留冻结智能体的上下文 @dair_ai。
- 安全仍然是企业智能体部署的瓶颈问题:微软安全智能部门发出了一项重要警告,关于影响 90+ redhat-cloud-services 包 的重大 npm 供应链妥协,包括一个自我传播的蠕虫,窃取 npm/GitHub/AWS/SSH 凭据 @MsftSecIntel。同时,企业智能体供应商强调 沙盒化、运行时隔离 和 安全栈集成 是部署的前提条件,包括对 NVIDIA OpenShell 和 LangChain 沙盒主题演讲的讨论 @shannholmberg, @LangChain。
Codex、Claude Code 与竞争激烈的编码代理竞赛
- OpenAI 将 Codex 扩展至更多场景:OpenAI 宣布 前沿模型和 Codex 现已通过 AWS / Amazon Bedrock 通用可用,专为希望在现有 AWS 安全/合规工作流中集成 OpenAI 能力的企业设计 @OpenAI, @OpenAIDevs。OpenAI 同时发布了 Codex Python SDK,支持线程、轮次、流式传输、恢复、图像和沙盒控制 @reach_vb,并新增对 Bedrock 支持的 Codex 工作流 @reach_vb on Bedrock config。
- Claude Code 发生真实运维事件:Anthropic 修复了 Opus 4.8 会话生成过多 并行子代理/工具调用 的漏洞后,重置了 Pro 和 Max 用户的 5 小时和每周速率限制,避免意外消耗使用量 @ClaudeDevs, 后续。这提醒我们,编码代理产品的质量日益取决于编排行为,而不仅是原始模型能力。
- 编码模型间的行为差异依然显著:开发者在 ProgramBench 和 WeirdML 等基准测试中指出 GPT、Claude 及其他模型存在显著差异,Opus 有时更倾向于探索而非最大化得分,或表现出特定基准的特性 @OfirPress, @htihle。另一篇长文指出,更新的 Claude Opus 4.6–4.8 变体在非编码领域可能编造看似合理但虚构的概念,暗示真实性/对齐性退化,而非普通幻觉 @distributionat。
基础设施、硬件与本地 AI 系统
- NVIDIA 正进军个人电脑领域:最受关注的硬件发布是 RTX Spark,一款由 NVIDIA/Microsoft 推出的“个人 AI 电脑”,基于 Grace + Blackwell 架构,配备高达 128GB 统一内存,宣称提供 1 PFLOP FP4 性能。关键战略解读:NVIDIA 不再仅销售加速器,而是推出与 Apple Silicon、x86 电脑和 Qualcomm 同时竞争的端到端本地 AI 系统 @kimmonismus, @swyx。
- 集群/网络更新:在数据中心方面,Lambda 宣布率先采用 NVIDIA Quantum-X InfiniBand Photonics Q3450-LD 交换机,通过共封装光学技术降低大型 AI 集群的网络功耗和故障率 @LambdaAPI。OpenAI 也宣布 Stargate Michigan 项目,计划建设一座 1GW 数据中心,采用闭环冷却技术,并配套劳动力/教育承诺 @OpenAINewsroom。
- 本地开源模型工具链快速改进:MLX-VLM v0.6.0 发布是近期较实质性的本地推理/工具链更新,新增推测解码、Anthropic 风格和响应风格 API、工具调用、多款新多模态模型支持,以及图像/音频功能,明确目标是将 Apple 设备转变为“真正的本地代理机器” @Prince_Canuma。这与 DGX Spark + vLLM 在本地 NVFP4 MoE 服务上的实验进展相辅相成 @vllm_project。
热门推文(按互动量排序,过滤技术相关)
- Anthropic 的 IPO 路径:Anthropic 表示已 向 SEC 秘密提交 S-1 草案,为 IPO 开启大门,待审查通过 @AnthropicAI。
- Claude Code 使用事件:Anthropic 重置用户速率限制,因 Opus 4.8 并行子代理/工具调用漏洞 导致使用量异常消耗 @ClaudeDevs。
- Qwen3.7-Plus:阿里巴巴推出 多模态代理模型,覆盖 GUI/CLI 操作、编码和视觉任务 @Alibaba_Qwen。
- OpenAI 通过 Bedrock 上线:OpenAI 模型和 Codex 现已通过 Amazon Bedrock 为企业工作流提供支持 @OpenAI。
- ARC-AGI-3 进展:Claude Opus 4.8 在 ARC-AGI-3 上创下 1.5% 的新 SOTA,绝对值虽小,但在此基准上实现显著提升 @arcprize。
- [MiniMax M3 - 编码与智能体前沿,1M 上下文,多模态](https://www.reddit.com/r/LocalLLaMA/comments/1ttdiq0/minimax_m3_coding_agentic_frontier_1m_context/) (活动:1090): MiniMax M3 被宣布为一款_open-weight_前沿模型,专注于编码/智能体任务,原生支持多模态/视觉,并采用 MiniMax 稀疏注意力机制,可处理高达
1M令牌的上下文,且保证512K的最小值 ([MiniMax M3](https://www.minimax.io/models/text/m3))。声称的长期智能体成果包括 12 小时 ICLR 论文复现、Hopper FP8 GEMM CUDA/Triton 优化在147次迭代后实现9.4×加速,以及在 PostTrainBench 排名中位列第三(仅次于 Opus 4.7 和 GPT-5.5);目前仅通过 API/MiniMax Code 访问,HuggingFace/GitHub 权重/本地部署计划后续推出。 评论者对廉价高效的视觉能力与长上下文智能体编码的结合表示谨慎兴趣,但因公告称其为 _“open-weight”_ 却未公开权重或参数量而持怀疑态度。一个技术讨论焦点是:这些结果是否意味着模型远大于`~250B`、极端基准优化,或是真正的开源权重突破。
- 评论者聚焦于缺失的发布细节:尽管声称是 _“首个具备三项前沿能力的开源权重模型”_,用户却无法找到 MiniMax M3 的实际权重、参数量或规模信息。一位评论者链接了公告中的预览图 (Reddit 图片),但线程中仍缺乏模型规模或可下载资源的确认。
- 一个实质性技术担忧是:所宣传的能力水平暗示三种可能性之一:远大于预期的模型、异常强大的基准优化,或重大的开源权重突破。讨论集中在 MiniMax M3 是否实际约为`~250B`参数或显著更大,以及其编码/智能体/多模态声明在权重公开和独立基准测试后能否成立。
- [NVIDIA 宣布 Nemotron 3 Ultra](https://www.reddit.com/r/LocalLLaMA/comments/1tthkh5/nvidia_announces_nemotron_3_ultra/) (活动:621): 该 [图片](https://i.redd.it/f79wu6dnml4h1.jpeg) 是 NVIDIA Nemotron 3 Ultra 的技术公告幻灯片,评论中描述为
550B-A55的 MoE 模型。幻灯片将 Nemotron 3 Ultra 与包括 GLM 5.1、Kimi K2.6 和 Qwen3.5 在内的开源/开源权重模型进行对比,覆盖“前沿智能”基准类别,如智能体生产力、编码、指令遵循、知识工作及长上下文能力。 评论者对与其他开源/开源权重模型的对比持积极态度,而一人指出其“人工分析分数”为`48`,略低于前沿级模型,处于 MiniMax 2.7 水平,预期其可能成为最强的美国开源权重模型。
- NVIDIA Nemotron 3 Ultra 被确认为`550B-A55`的 MoE 模型,意味着总参数量约为`550B`,每令牌活跃参数量约`55B`。此架构细节是线程中提及的最具体技术规格。
- 一位评论者引用`48`的“人工分析分数”,将 Nemotron 3 Ultra 定位为“略低于前沿级”,大致处于MiniMax 2.7范围,同时暗示其可能按此指标成为最强的美国开源权重模型。
- 共享的技术参考包括 NVIDIA 官方 Nemotron 3 Ultra Base 使用指南(GitHub):NVIDIA-NeMo/Nemotron,以及 LifeArchitect 模型对比表:lifearchitect.ai/models-table。一位评论者认为与Qwen3.5的对比值得注意,因为 Nemotron 可能是 NVIDIA 最佳开源权重模型,但仍落后于多个非美国/开源模型。
- [Stepfun 3.7 Flash 非常好](https://www.reddit.com/r/LocalLLaMA/comments/1tss9nq/stepfun_37_flash_is_very_good/) (活动:473): 该 [GIF](https://i.redd.it/k37ol07vfg4h1.gif) 是技术可视化演示,非表情包:展示了 Stepfun 3.7 Flash 对提示
create a beautiful, relaxing flight simulator in a single html page的输出,渲染出带 HUD 风格速度/高度指示器的低多边形 3D 飞行场景。发帖者称这是官方Q4_X_S量化版本,并表示该模型在美学上接近 GLM 5.1,3D 世界理解能力约为其80%,但仅使用 GLM 5.1 约25%的参数量且内置视觉能力。 评论者大多以比较和怀旧回应,而非深入基准测试:一人提及旧版 Excel 飞行模拟器,另一人比较了Qwen 3.7 Max / 27B的兴趣,并询问其是否优于Qwen3.6 27B。
- 一位评论者从模型对比角度提及Qwen 3.7 Max,并期待未来Qwen 3.7 27B的发布;另一人询问 Stepfun 3.7 Flash 是否优于Qwen3.6-27B。线程中包含 Qwen3.6-27B 的截图证据 (图片),但未提供定量基准分数或可复现的评估细节。