How Snapchat Serves a Billion Predictions Per Second

TL;DR · AI 摘要
Snapchat 通过名为 Bento 的统一机器学习平台,在 100 毫秒内完成从百万级内容库中检索、评分和排序的任务,支撑每日 4.77 亿用户的实时推荐。
核心要点
- Bento 平台采用非对称架构,将单一用户请求扩展为数百个(用户,候选)对进行模型评分。
- 系统分为检索和排序两阶段:轻量级模型筛选候选集,重型模型预测转化率与参与度。
- Snapchat 每日需处理 4.77 亿活跃用户的四种核心决策:内容流、广告竞价、好友推荐和 AR 镜头。
结构提纲
按章节快速跳转。
Snapchat 拥有 9.46 亿月活用户,需在 100 毫秒内完成内容检索、特征提取和模型排序。
系统需实时处理内容推荐、广告竞价、好友建议和 AR 镜头四种高并发决策。
Bento 是统一 ML 平台,其架构设计旨在解决单一请求扩展为数千次模型评估的非对称性问题。
与典型 Web 请求不同,排名请求会在内部“扇出”成数百个(用户,候选)对进行并行评分。
流程分为检索阶段(廉价模型筛选)和排序阶段(昂贵模型精排),以平衡性能与准确性。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- Snapchat Bento Architecture
- Scale & Performance
- 100ms Latency Budget
- 477M Daily Active Users
- Core Decisions
- Content Ranking
- Ad Auctions
- Friend Suggestions
- AR Lenses
- System Design
- Asymmetric Request Fanout
- Retrieval (Light Models)
- Ranking (Heavy Models)
金句 / Highlights
值得收藏与分享的关键句。
Snapchat decides what to show you in roughly 100 milliseconds.
A ranking request is asymmetric... this single request expands into hundreds or thousands of pairs of (user, candidate).
The first stage is retrieval, where cheap models filter the full corpus down to a few hundred or thousands of candidates.
Snapchat 如何每秒处理十亿次预测
大多数团队通过运行几个测试查询并祈祷好运来选择搜索提供商——这是一种导致幻觉和不可预测失败的配方。You.com 提供的这份技术指南为您提供了一个评估 AI 搜索和检索的精确框架。
您将获得:
- 一个用于评估 AI 搜索的四阶段框架
- 如何构建一组能预测真实世界性能的黄金查询集
- 用于衡量准确性的指标和代码
从“看起来不错”转变为经过验证的质量。
Snapchat 决定向你展示什么内容大约需要 100 毫秒。在这个时间窗口内,系统必须从数百万个视频中检索出几百个候选视频,获取关于用户的几十个特征和关于每个候选视频的几十个特征,对每一对(用户与候选)运行深度学习模型,并对结果进行排序。现在考虑一下,当 4.77 亿人每天打开应用程序时,这种规模是如何扩展的。
有趣的问题是系统在这种规模下如何保持快速。更深层次的问题是,系统必须具备什么样的结构才能做到快速。
Snapchat 于 2011 年作为一个阅后即焚的消息应用程序起步,照片会在几秒钟后消失。此后,它已发展为一个完整的社交平台,包含 Discover、Spotlight、增强现实镜头、好友建议以及为公司提供大部分资金支持的广告业务。Snap 报告称,2025 年末其月活跃用户(MAU)达到 9.46 亿,其中约 4.74 亿每天打开应用程序。印度是最大的市场,拥有超过 2.14 亿用户,其次是美国,约有 1.04 亿用户,而法国、海湾国家和其他地区构成了覆盖全球主要社交媒体市场的其余部分。
对于 Snap 来说,机器学习更接近产品本身,而不仅仅是其上的一项功能。每一次会话都迫使系统做出四种类型的决策。
- 第一,哪些内容应该出现在你的 Discover 和 Spotlight 信息流中。
- 第二,哪些广告应该赢得竞价以获得你的关注。
- 第三,哪些人应该出现在你的好友建议中。
- 第四,哪些 AR 镜头和特效应该为你呈现。
每个决策都由 ML 模型塑造,每个决策都在毫秒级内发生,而且每个决策都可能以高昂的代价出错。糟糕的广告排名会直接导致收入损失,而糟糕的推荐会导致参与度下降,进而导致未来的收入损失。
所有这些都运行在一个名为 Bento 的单一平台上。在本文中,我们将探讨 Snap 工程团队是如何构建 Bento 的,以及他们在此过程中面临的挑战。
_免责声明:本文基于 Snap 工程团队公开分享的细节。如果您发现任何不准确之处,请评论指正。_
典型的 Web 请求大致是对称的。一个请求到达,服务器查询数据库,构建响应,并将其发回。其形状是一对一的。
排名请求是不对称的。一个用户打开应用程序,平台必须决定从数百万个选项中向他们展示什么。在内部,这个单一请求会扩展成数百或数千对(用户,候选),每一对都需要模型的评分。评分后,系统对候选进行排序,并将前几个返回给用户。一个请求进来,发生数百或数千次模型评估,一个简短的排序列表发出去。
这种扩展塑造了 Bento。平台中几乎每一个架构决策都是关于如何吸收这种扇出的答案。
在实践中,工作分为两个阶段。
- 第一阶段是检索,廉价的模型将整个语料库过滤到几百或几千个值得评分的候选。
- 第二阶段是排序,昂贵的模型仔细对这些候选进行评分并产生最终顺序。
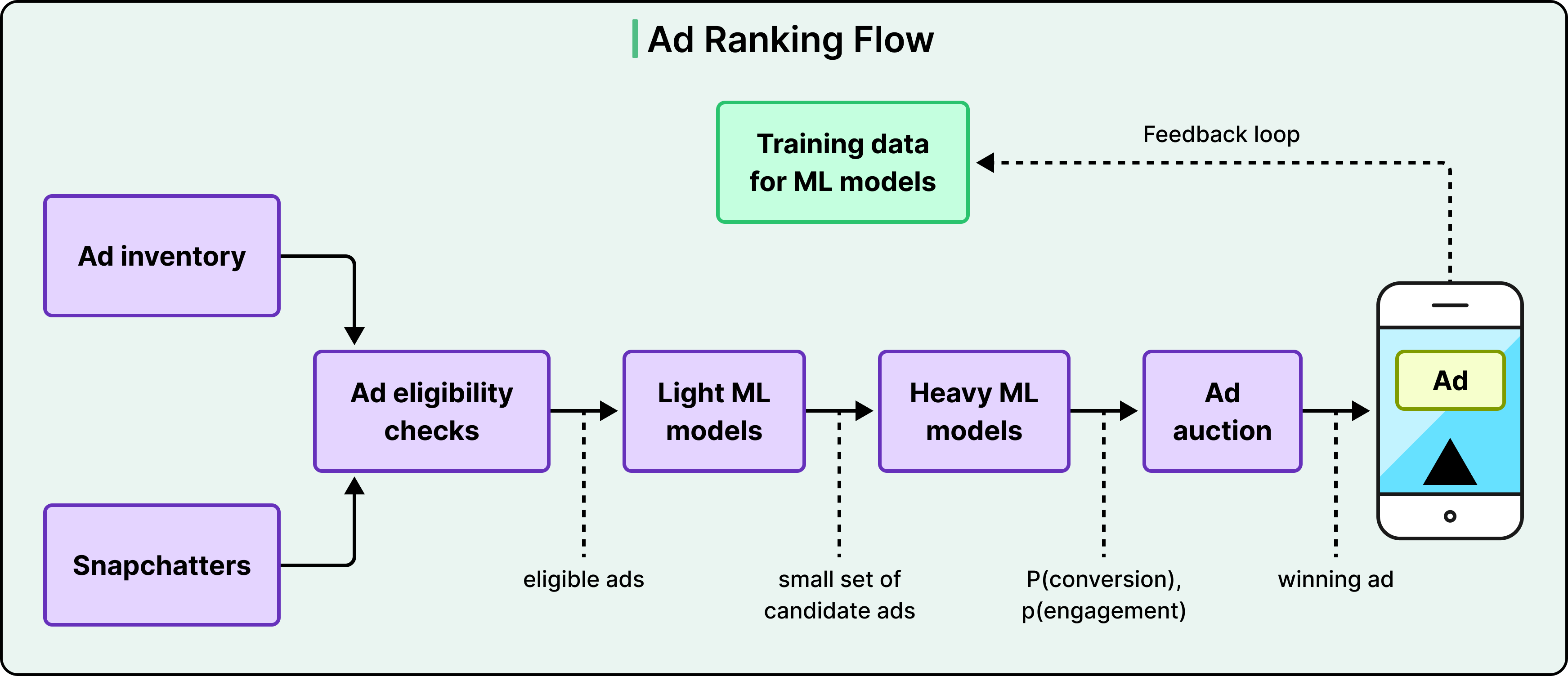
Snap 的广告排名系统明确遵循这种模式。轻量级模型过滤符合条件的广告库存,重量级模型预测转化和参与的概率,竞价选出获胜者,然后展示获胜的广告。用户对该广告的反应(无论是点击、忽略还是观看)随后回流到训练数据中。
数据量增长得非常快。如果数亿用户每次会话触发几个排名请求,并且每个请求对数百个候选进行评分,总预测量将超过每秒十亿次。Snap 报告了这个确切的数字,以及每秒 1 TB 的特征读取量和每天流经特征管道的 10 万亿个事件。
这种设计给平台带来了四种截然不同的压力:
- 延迟压力源于一个简单的事实:如果信息流加载时间过长,用户就会放弃应用程序。
- 规模压力来自巨大的预测量本身。
- 新鲜度压力来自这样的要求:刚刚点赞了一个视频的用户应该立即看到系统对该信号的响应。
- 迭代压力源于 ML 工程师每月需要发布数百个实验,以保持模型竞争力的需求。
这些压力相互掣肘,因为低延迟需要更小的模型,大规模需要更便宜的计算资源,时效性需要实时流水线,而快速迭代需要灵活的工具。Bento 的目标就是让这四个方面同时变得可控。
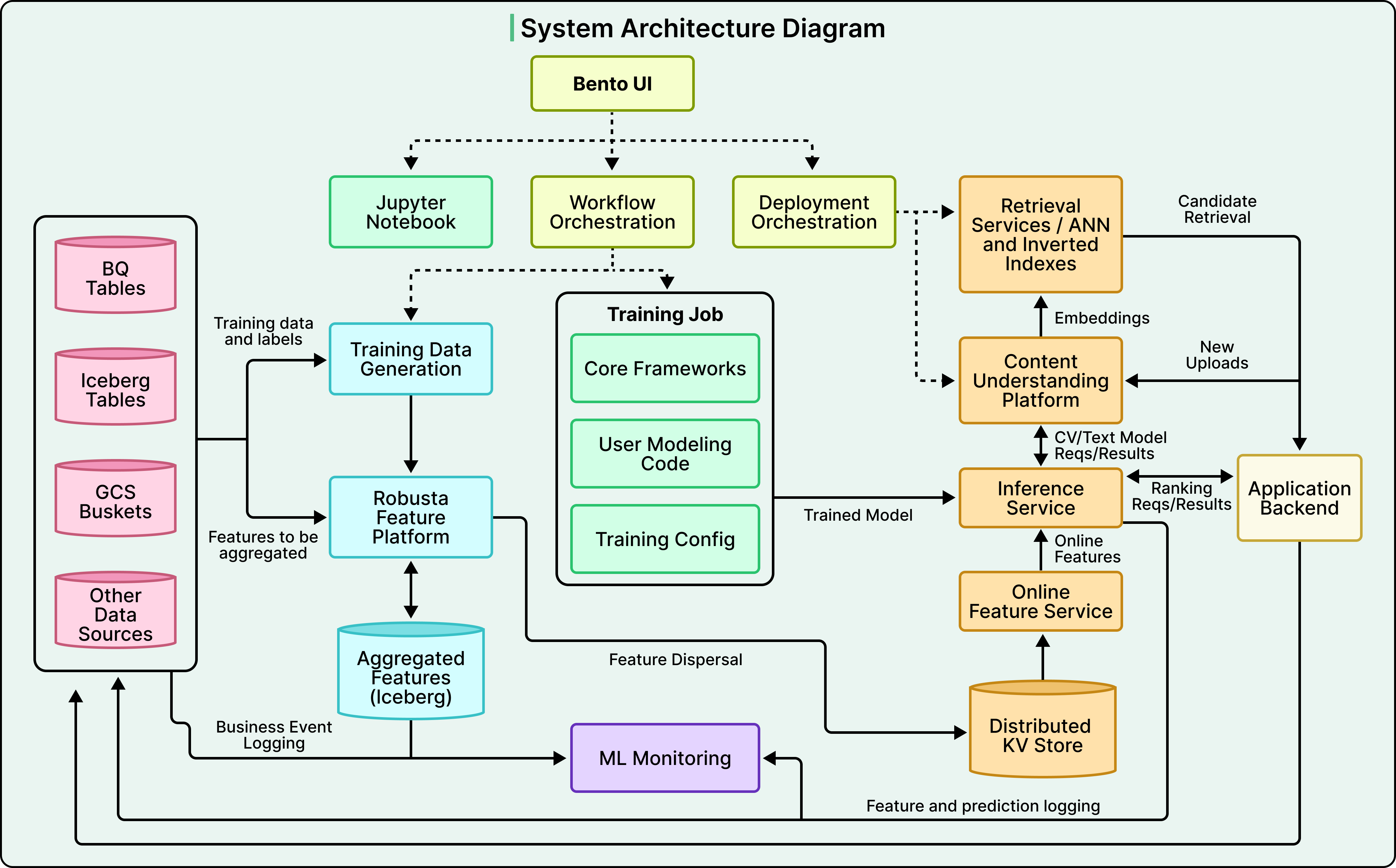
该平台清晰地划分为两部分:一部分负责生产模型,另一部分负责提供服务。几乎所有独特的工程设计都集中在第二部分。
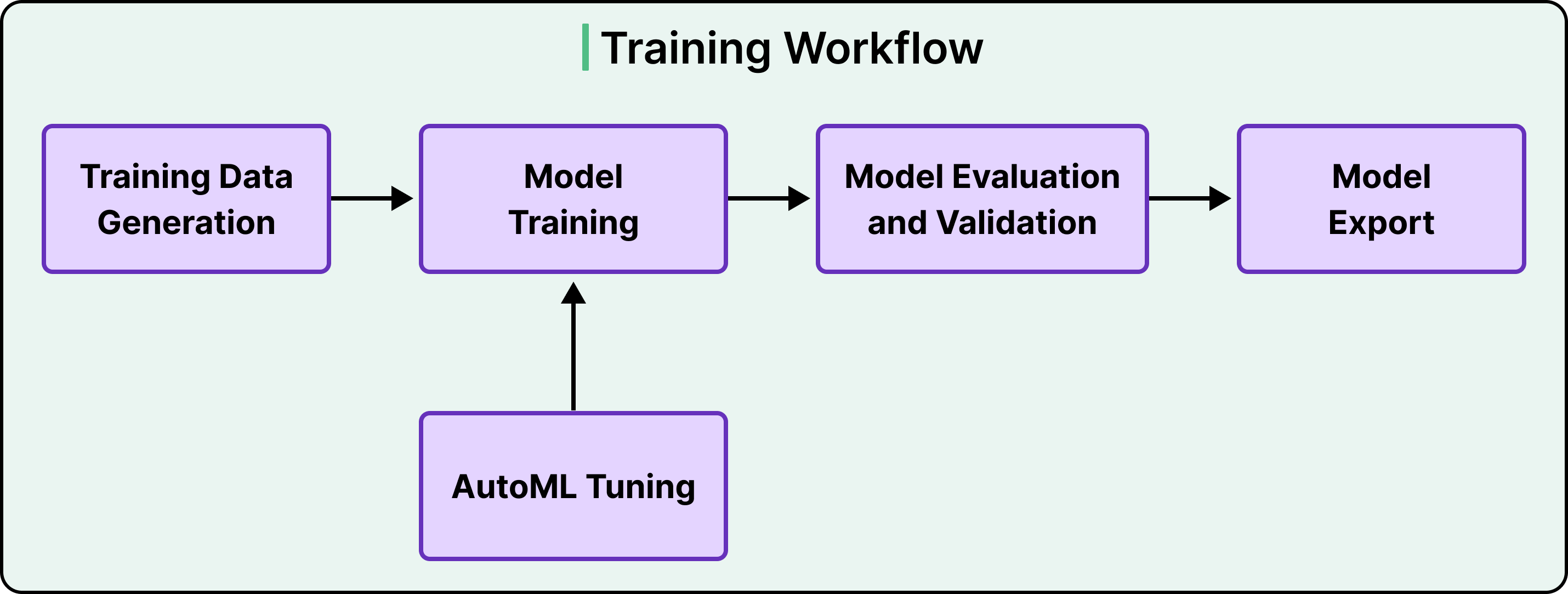
Bento 的训练部分遵循一个大家熟知的四阶段工作流。
训练数据由原始事件和聚合特征生成。模型在 GPU 或 TPU 主机上进行训练,训练好的模型会根据留出数据进行评估,最后,模型会被导出为可用于服务的格式。Bento 使用 Kubeflow 来编排这些阶段,这是一个专为 ML 流水线构建的开源工作流引擎。
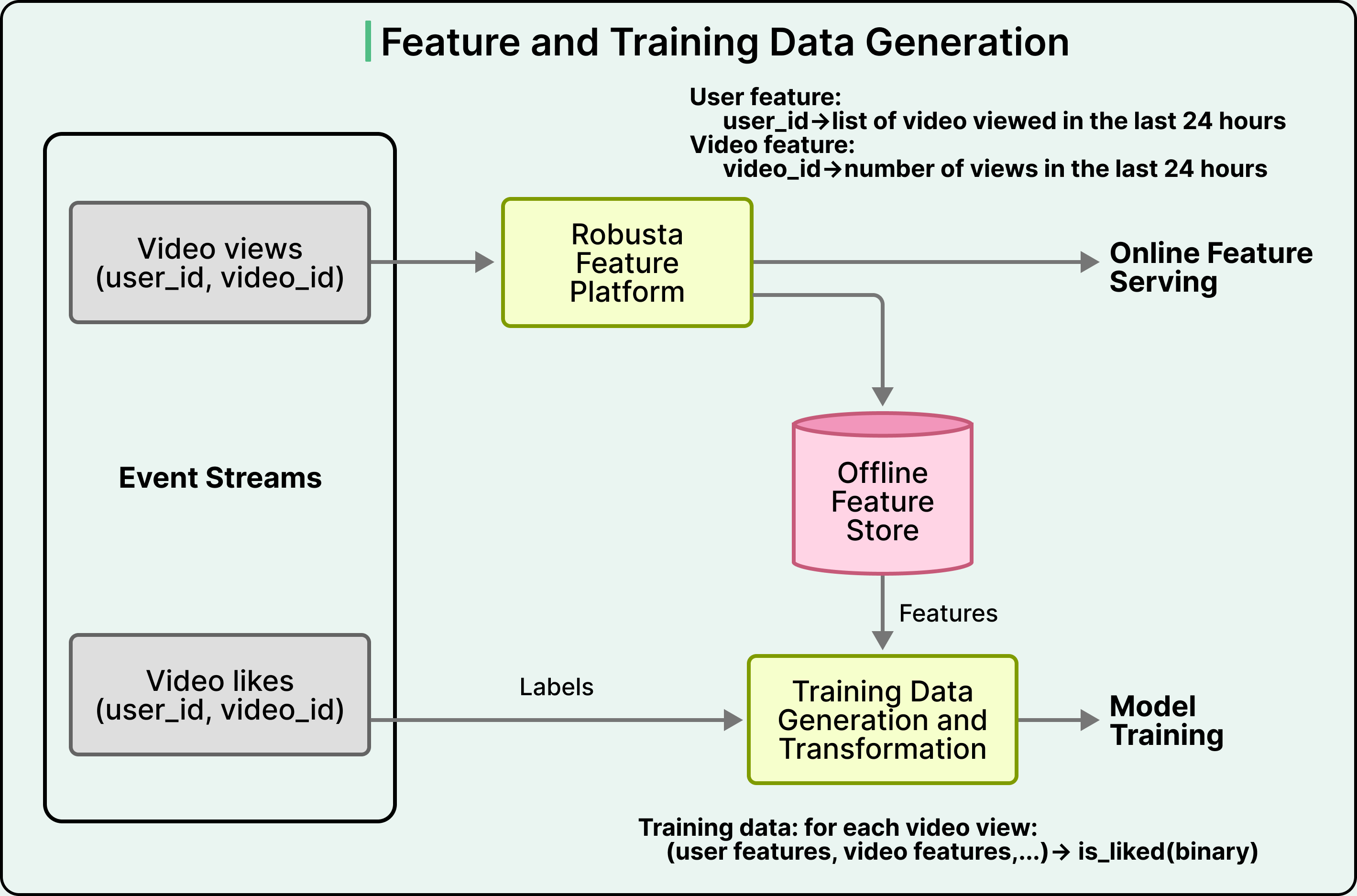
在这一部分,一个有趣的设计选择是 Snap 如何构建训练代码本身。Bento 并没有让每个团队都从头开始编写自己的模型代码,而是将训练应用程序划分为三层。
- Core 框架是一个基于 TensorFlow 和 Keras 构建的共享内部库,它标准化了排序和推荐模型的常见模式。
- 用户模型代码是指单个 ML 工程师编写的用于表达其特定模型的代码。
- 训练配置是一个 YAML 文件,用于指定硬件、输入数据和运行时选项。
这种分层架构使得每天进行数百次实验成为可能。工程师只需更改配置文件中的一行即可切换输入数据集,或者修改几行模型代码来测试新功能,然后触发一次完整的训练运行。共享的 Core 框架意味着实验具有可比性,因为它们基于相同的基础架构,而配置层则意味着启动实验的成本很低。
在模型导出步骤,Bento 采取了一些不同的做法。现代推荐模型具有一种独特的计算形态。它们包含巨大的嵌入表,每个用户 ID 或视频 ID 都映射到一个学习到的向量,这些表的大小受限于内存容量。此外,它们还包含位于这些嵌入之上的密集神经网络层,其计算受限于算力。如果在同一硬件上同时运行这两者,势必会造成某一种资源的浪费。
Bento 的导出步骤会将计算图拆分,将密集矩阵乘法放在 GPU 上,而将嵌入查找和特征解析放在 CPU 上。换句话说,同一个训练好的模型会针对不同的推理硬件生成不同的导出版本。
模型会反复经历这一过程,而非仅此一次。Bento 完全自动化了增量训练:新事件会不断追加到训练数据中,模型会在更新后的数据上重新训练,新版本在通过验证后会自动部署。因此,生产环境中的模型与一周前的同一模型相比,已经发生了实质性的变化。
整个过程生成了一个准备好用于服务的训练模型,而更棘手的问题才刚刚开始。
在 Bento 的服务部分,前文提到的非对称工作负载转化为一组具体的工程问题。
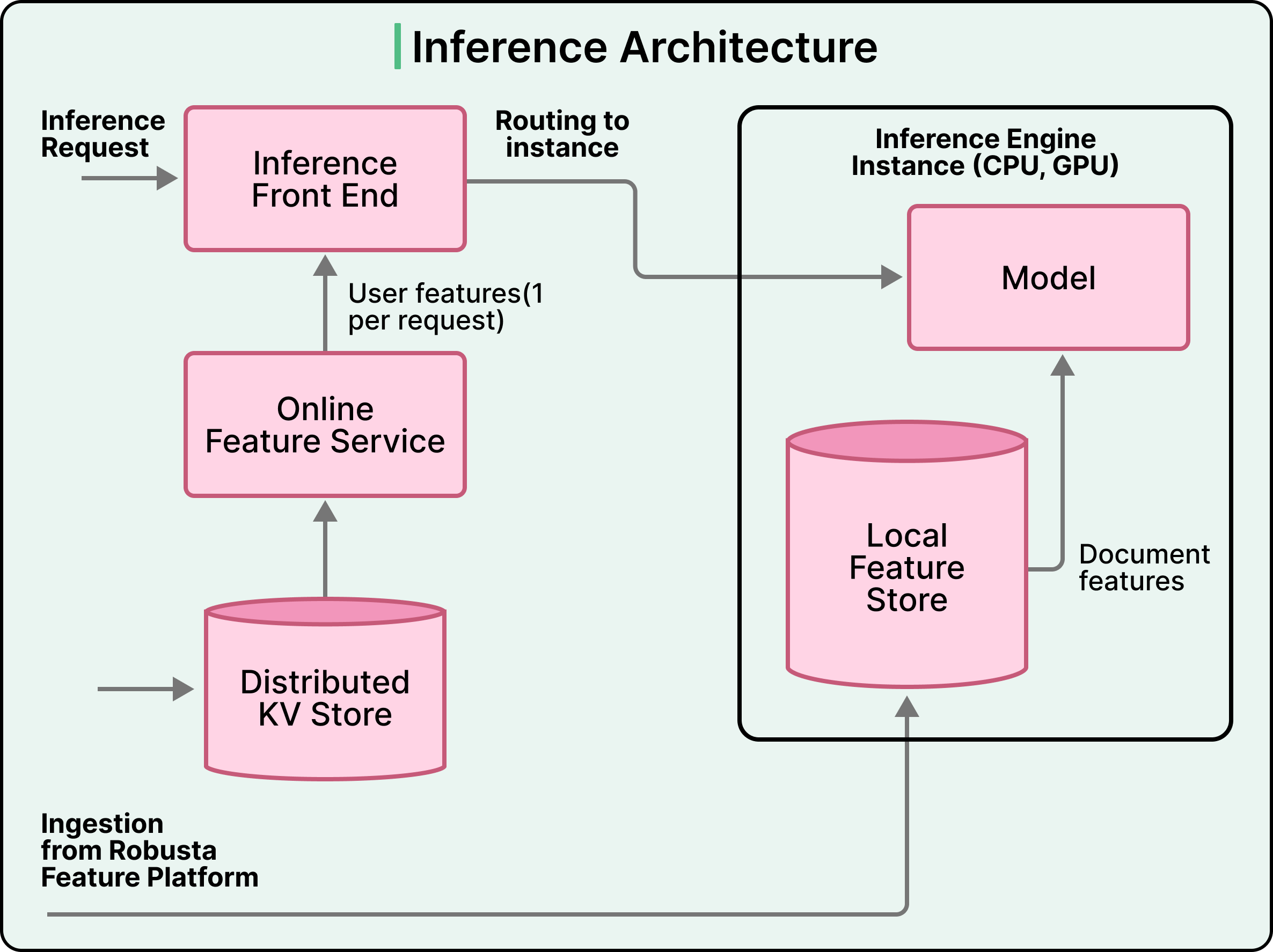
当一个请求进来时,必须获取特征,模型必须对数百或数千个候选进行打分,且结果必须在延迟预算内返回。这些步骤中的每一步都带来了各自的挑战,而 Bento 的设计反映了针对如何处理这些问题的特定抉择。
在这些选择中,影响最深远的一项涉及特征存储,它位于模型训练的离线世界和模型服务的在线世界之间。
特征是模型从原始数据中提取的数值输入。一个简单的例子是用户在过去 24 小时内观看的视频数量。更复杂的特征可能涉及在训练期间学习到的嵌入、基于时间窗口的统计聚合,或按各种键分组的计数。模型接收数十或数百个特征作为输入,并产生预测结果。
挑战在于,特征必须同时存在于两个地方。
- 在离线环境(即模型训练的地方),特征存储在大型的分析数据库中,Snap 使用 Apache Iceberg 来实现这一目的。
- 在在线环境(即模型提供服务的地方),特征存储在针对低延迟读取进行了优化的快速键值存储中。
这两个存储必须保持一致。如果同一个特征在两个地方的计算方式不同,模型就会在一个数据分布上进行训练,而在另一个数据分布上进行服务,这会导致一类被称为“训练与服务偏差”的 Bug。这种情况下,模型在离线评估中表现良好,但在生产环境中却表现糟糕。这个问题是每个成熟 ML 团队最核心的运营关注点,但在教程中却很少涉及。
Snap 的特征平台名为 Robusta,它是基于 Apache Spark 构建的。
Robusta 负责保持这两个存储的同步。它每天处理 10 万亿个事件,在滑动时间窗口上计算聚合特征,并将结果写入离线 Iceberg 存储和在线键值存储。仅在线特征存储就拥有 800 TB 的数据,并支持每秒 1 TB 的读取量。
前面提到的非对称工作负载在特征层变成了一个具体的问题。单个排序请求需要一个用户的特征以及许多候选文档的特征,如果通过网络获取所有这些特征,速度将会太慢。
Bento 根据用例采用两种不同的策略。
第一种策略很不寻常。对于许多排序工作负载,Snap 将文档特征直接与推理引擎实例共置。当请求到达时,系统从中央在线存储执行一次用户特征查找,并将请求转发给推理。推理引擎随后在评分期间从本地内存读取文档特征,这完全消除了网络扇出。其代价是每个推理实例必须在内存中保存完整的文档特征语料库,这非常昂贵。在 Snap 的规模下,这笔账算得过来,因为延迟的降低和成本的节约超过了内存成本。在较小规模下,这种方法会很浪费,远程特征存储则是标准答案。
第二种策略处理文档语料库太大而无法放入每个推理实例的情况。对于这些情况,Snap 构建了一个单独的检索服务,该服务执行近似最近邻(ANN)搜索(一种对学习到的嵌入向量的快速相似性搜索),以及单次遍历中的倒排索引查找和正排索引查找。检索服务返回一个小的、预填充的候选集,并附上特征,准备好发送给推理引擎。
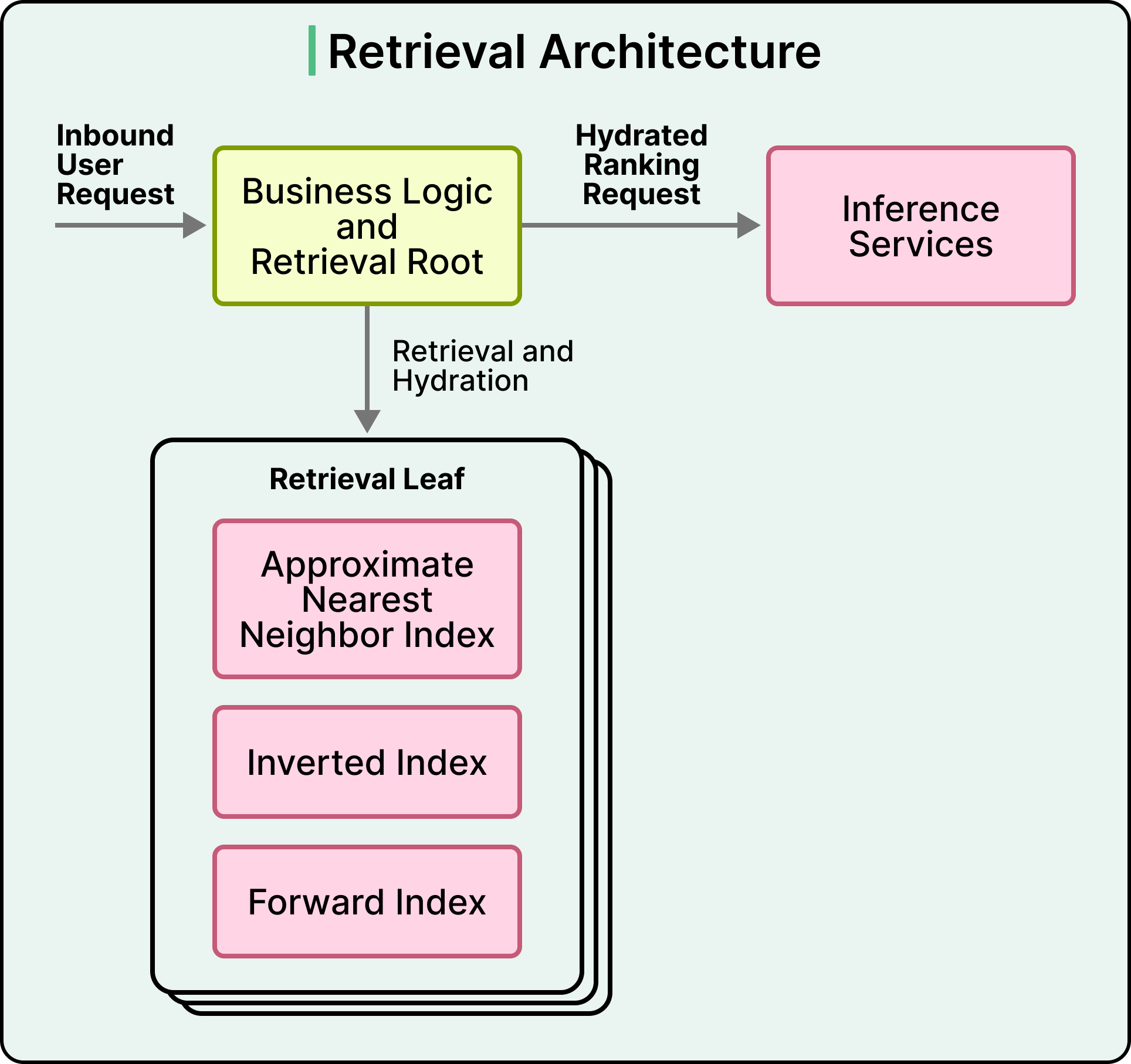
这两种策略都是有效的,选择哪一种取决于语料库大小、访问模式以及推理实例上可接受的内存量。
一旦请求到达模型,几项优化使得实际评分既快速又经济。其中两项优化值得详细了解。
第一项是前面提到的 GPU 和 CPU 计算图分离。模型导出步骤生成一个特定于硬件的版本,将密集矩阵运算放在 GPU 上,而将嵌入查找和特征解析放在 CPU 上。这种分离同时避免了两种浪费模式。将嵌入放在 GPU 上会浪费稀缺的 GPU 内存用于存储查找表,而将密集运算放在 CPU 上则会浪费 GPU 本可以轻松并行化的操作时间。这种分离在导出阶段需要更多的工程投入,但在服务阶段会带来数倍的回报。
第二项是数据平面优化,这是整篇博客中最引人注目的具体结果。Bento 的工程师发现,很大一部分推理延迟花在了特征数据的序列化和反序列化上,而不是模型本身。他们重新设计了推理 API,以便特征可以作为原始字节获取和传输,反序列化仅在推理引擎内部进行。结合自定义 Protobuf 优化,这一单一更改导致延迟降低了 2 倍,数据平面成本降低了 10 倍。教训是,在大规模场景下,系统的枯燥底层机制(包括序列化、RPC 帧和网络传输)往往主导着成本。大部分成本存在于模型之外。
还存在其他优化。请求批处理、推理集群间的模型共置以及针对底层硬件的构建级调优,都对性能和成本有增量贡献。上述两项优化包含了大部分的经验教训。
一旦做出预测并返回排序后的信息流,系统的工作仍在继续。ML 平台最重要的部分发生在响应发出之后。
Bento 做出的每一个预测都会被记录,以及用于做出该预测的特征。用户采取的响应操作也会被记录,包括他们是否观看了视频、关闭了广告或发送了好友请求。这些日志流回训练数据管道,在那里生成新的训练记录。然后对更新后的数据运行增量训练,导出新的模型版本,并在通过验证后,部署系统推出新版本,旧版本随之退役。
在此循环旁边持续运行着两种监控:
- 第一种监控随时间观察特征和预测的统计属性。如果特征的均值发生漂移,或者预测的分布发生偏移,这种变化通常是上游出现故障的信号。
- 第二种监控直接比较在线和离线的行为。利用离线特征存储离线重新计算相同的预测,并将结果与在线系统产生的结果进行比较。
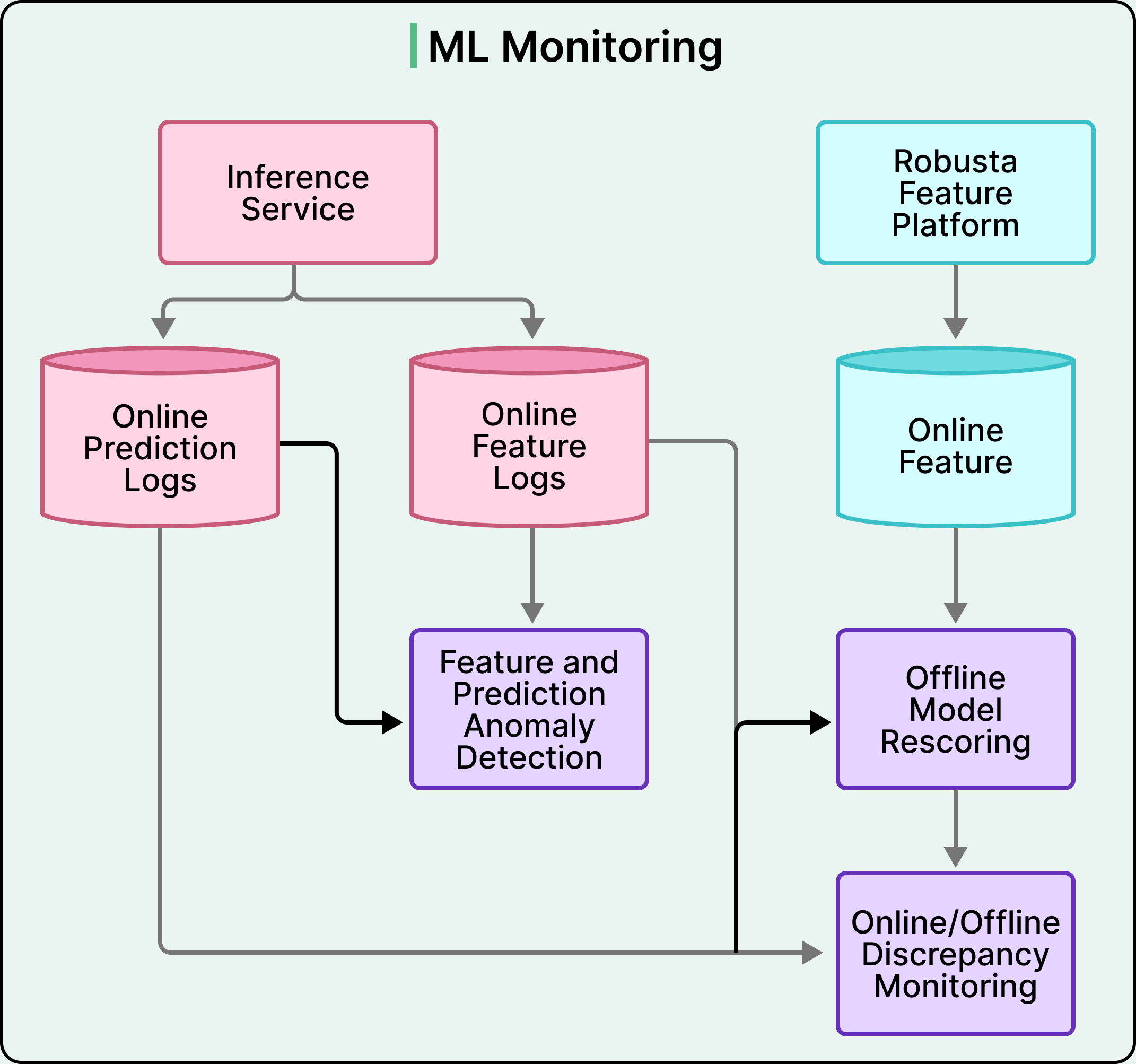
任何差异都指向前面提到的训练与服务偏差问题。
部署控制平面使用了借鉴自 Kubernetes 的协调模式。系统存储一个期望状态,描述了应该部署哪些模型、以何种配置以及在哪些集群上,并持续将此期望状态与实际运行状态进行比较。任何差异都会自动消除。这种方法使得大规模 ML 部署在此体量下是安全的,因为在此规模下手动部署太容易出错,根本不可行。
Snap 的博客提到,在最近两年中,排序模型的规模增长了 20 倍,训练数据增长了 40 倍。该平台在正常运行过程中消化了这种增长。这种扩展空间正是反馈循环带来的价值。该平台与其说是一个生产模型的固定流水线,不如说是一个持续运行的系统,它生产出一连串的模型版本,每个版本都由前一个版本生成的数据所塑造。
Bento 的构建基于对其工作性质的一个核心观察。排序请求是不对称的,因为一个用户请求会扩展成数百或数千次模型评估,然后再收拢成一个简短的排序列表。这种设计,乘以 4.74 亿日活用户,以及在延迟、规模、新鲜度和迭代方面产生的四个运营压力,驱动了平台中几乎所有的架构决策。
该平台将工作分为两部分来处理。
训练部分通过一个四阶段工作流生成模型,采用分层代码结构使工程师每天能够运行数百个实验,并包含一个模型导出步骤,将计算图在 GPU 和 CPU 之间拆分,以匹配推荐模型独特的计算形态。
服务部分处理更棘手的运营问题,包括特征在离线和在线存储中的双重存在,通过特征并置或专用检索服务解决的高扇出问题,以及带来延迟降低 2 倍和数据平面成本降低 10 倍的推理时优化。围绕所有这些的是一个持续的反馈循环,它将每个预测转化为下一轮的训练数据,并配有监控漂移的监控系统和自动协调期望状态与运行状态的部署控制平面。
Bento 运行的规模数字非常庞大,包括每天训练数百个模型,每天超过 100,000 小时的训练计算时间,800 TB 的在线特征数据,每秒 1 TB 的特征读取量,以及每秒超过 10 亿次预测。这些数字本身很有趣,但更重要的是,它们作为条件使得整个平台的架构选择变得合乎情理。
参考