Netflix如何利用多模态AI驱动视频搜索

TL;DR · AI 摘要
Netflix通过多模态AI系统整合多个专用模型,解决视频搜索中的跨模态数据对齐与高效查询难题,实现亚秒级响应。
核心要点
- Netflix使用角色识别、场景分类、对话转录等专用AI模型,因专精模型在特定任务上比通用模型准确率高30%以上
- 三层管道系统通过时间轴对齐算法,将216亿帧视频数据转化为可融合的多模态索引,支持跨模态亚秒级查询
- 正在探索的MediaFM统一模型可同时处理音频、视频和文本,可能将系统复杂度降低60%
结构提纲
按章节快速跳转。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- Netflix多模态视频搜索系统
- 专用模型层
- 角色识别模型
- 场景分类模型
- 对话转录模型
- 数据融合层
- 时间轴对齐算法
- 跨模态特征融合
- 查询引擎层
- 混合检索策略
- 分布式索引
金句 / Highlights
值得收藏与分享的关键句。
Netflix单季剧集可产生超过2000小时原始素材,相当于2.16亿帧画面。
存储、对齐和交叉索引这些数据同时保持亚秒级查询响应,远超传统数据库能力。
专用模型在特定任务上表现更优,如人脸识别模型比通用视觉模型准确率高30%。

大多数 AI 代理在演示中表现良好,但在生产环境中却失败。本文将介绍如何使用 Orkes Agentspan 和 Conductor 等开源框架构建持久可靠的、企业级 AI 代理。这份白皮书探讨了如何编排具备容错能力的长期运行代理工作流,并内置治理、可观测性、重试机制和人工审批功能。文中还将对比 Agentspan 与 LangGraph、CrewAI、AutoGen 在真实企业级 AI 系统中的差异。若您正在构建需要可靠性、扩展性和控制力的 AI 工作流,本指南将展示实现生产级代理的架构模式。
一季 Netflix 节目可产生超过 2,000 小时的原始素材,相当于 2.16 亿帧画面。
当电影剪辑师需要找到特定角色在特定场景说出特定台词的精确时刻时,他们面对的是软件工程领域最复杂的搜索问题之一。而解决方案竟与构建更好的 AI 模型关系不大。事实证明,真正的挑战在于基础设施。
Netflix 的剪辑团队过去需要耗费数天时间在原始素材中寻找关键片段。例如,导演可能需要特定场景中角色的所有镜头,营销团队可能需要某个系列中最引人注目的五个动作场景。寻找这些片段意味着要手动翻阅数千小时的素材,导致创意进程停滞。
解决这一问题的团队打造了一个看似简单的搜索栏,但其底层是一个三层管道系统:协调多个 AI 模型的输出,将结果融合到共享时间轴,并以亚秒级延迟响应混合文本-向量查询。
当多个 AI 模型处理同一素材时,原始 2.16 亿帧数据会扩展为数十亿个多维度数据点。在保持亚秒级查询性能的同时存储、对齐和交叉分析这些数据,远超传统数据库的处理能力。
本文将解析 Netflix 如何构建该系统及其面临的挑战。
_免责声明:本文基于 Netflix 工程团队公开的技术细节。若发现不准确之处欢迎指出。_
为什么 Netflix 要对同一素材运行多个 AI 模型,而不是依赖单一全能模型?
这是因为专用模型在特定任务上始终优于通用模型。专门训练的人脸识别模型能更准确地识别角色,场景分类模型能更精确地映射环境,对话转录模型能更可靠地捕捉语音。
因此 Netflix 采用了多模型集合方案:一个模型识别角色,另一个分类场景环境,第三个转录对话,第四个检测物体。每个模型在其领域表现优异,但输出格式截然不同。
例如,角色识别模型可能输出文本标签如“乔伊”,而场景分类模型会生成一个 512 维向量嵌入(代表场景数学意义的数字列表)。对话模型则输出带时间戳的文本记录。这些不同数据类型需要差异化的搜索策略。
参考下方示意图:
格式问题只是挑战的一半。各模型还将视频分割为不同且重叠的时间区间。角色模型可能在 2-8 秒检测到“乔伊”,场景模型在 4-9 秒标记“厨房场景”。模型间缺乏统一时间轴,区间重叠但未对齐。
因此,工程团队必须解决核心问题:
如何将不同时间分辨率、不同格式的输出整合为可搜索的索引?
Netflix 正通过名为 MediaFM 的统一基础模型探索全新方案,该模型可同时处理音频、视频和文本。但目前生产系统仍依赖三层解耦管道,分阶段处理不同需求。
从原始模型输出到可搜索智能的转换遵循分阶段解耦流程:
每个阶段专注单一任务,这种分离是系统架构的核心。在 Netflix 的规模下,任何两个阶段的耦合都会导致性能瓶颈。
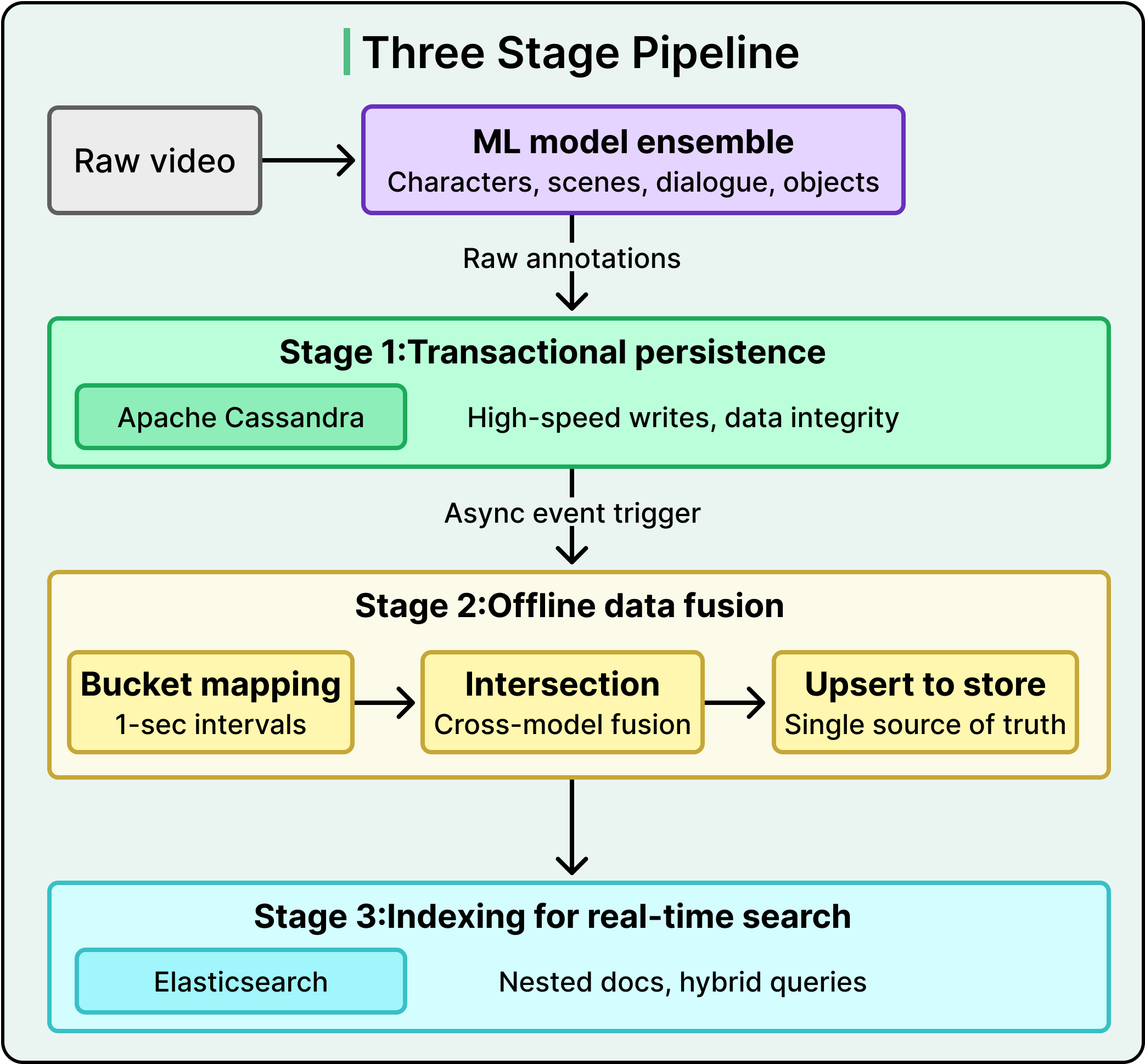
原始模型的所有标注结果被摄入并存储在Apache Cassandra中,这是一款专为高吞吐量写入优化的分布式数据库。此阶段严格保障数据完整性。每个模型输出结果都会被安全捕获,且零数据转换。系统以模型原始生成的格式完整存储数据。
为什么将此阶段与其他后续处理流程分离?
因为如果系统在摄入过程中尝试处理或融合数据,繁重的计算会拖慢实时摄入速度。解耦设计确保无论运行多少个模型或产生多少数据,摄入层都能保持吞吐能力。
当原始数据安全持久化后,会触发一个异步处理作业。这个离线融合层是系统架构的核心。它将计算密集型任务移出实时路径,因此复杂的数据交叉处理永远不会干扰持续摄入。
关键的技术手段是时间桶划分(temporal bucketing)。
请参考下图:
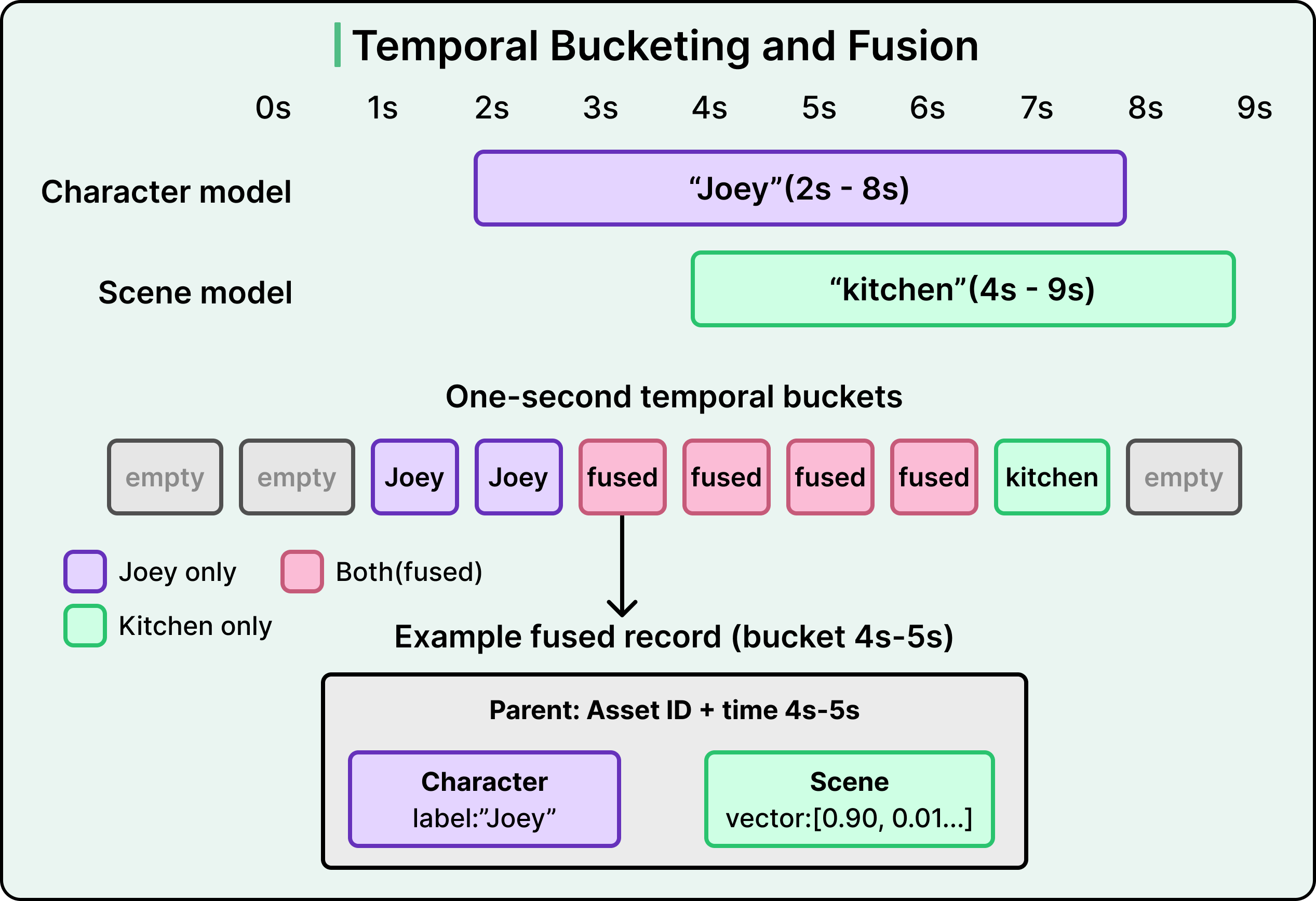
管道通过将其映射到固定的一秒时间间隔来标准化所有模型输出。这一过程分三步进行:
- 首先是桶映射。连续检测结果被分割为离散的一秒间隔。例如,如果角色模型在2到8秒检测到"Joey",管道会将这段连续时间划分为7个独立的一秒时间桶。
- 第二是标注交叉。当多个模型为同一秒时间桶生成标注时,系统会将它们融合为单一综合记录。例如,如果第4到5秒的桶同时包含"Joey"和"kitchen",它们会被合并为"该秒视频片段中Joey在厨房"的记录。
- 第三是优化存储。这些增强后的融合记录作为独立实体写回Cassandra。最终形成按秒划分的多模态交叉索引,精确关联每个融合标注与原始视频资产。
一个重要细节使该过程具备增量特性。
管道使用upsert操作:当存在现有记录时进行更新,否则插入新记录。其复合键(composite key)由资产ID和时间桶共同构成唯一标识。
如果某个视频秒级时间桶已存在(可能由早期模型运行填充),系统会更新现有记录而非创建重复项。这为每个视频秒建立单一数据源真相,并支持随时间新增模型的平滑处理。
选择一秒钟作为时间桶的大小本身是经过权衡的设计决策。
更小的桶提供更高时间精度但产生海量记录。以一秒分辨率计算,2000小时的档案库会产生720万时间桶,每个桶可能包含多个模型的标注。Netflix选择一秒作为精度与可管理性之间的平衡点。
当增强后的时间桶被持久化后,后续事件会触发将其摄入Elasticsearch(系统查询引擎)。
每个时间桶被结构化为嵌套文档:
- 父级记录保存整体资产上下文,包括资产ID、影片ID和时间区间。
- 子文档包含具体多模态标注,如角色数据、场景嵌入和对话文本。这种层级结构使跨标注查询成为可能。
当用户搜索"Joey在厨房"时,Elasticsearch可在同一父级桶内同时匹配角色标注和场景标注。
建立融合索引后,系统准备就绪以支持用户可见的最终阶段。
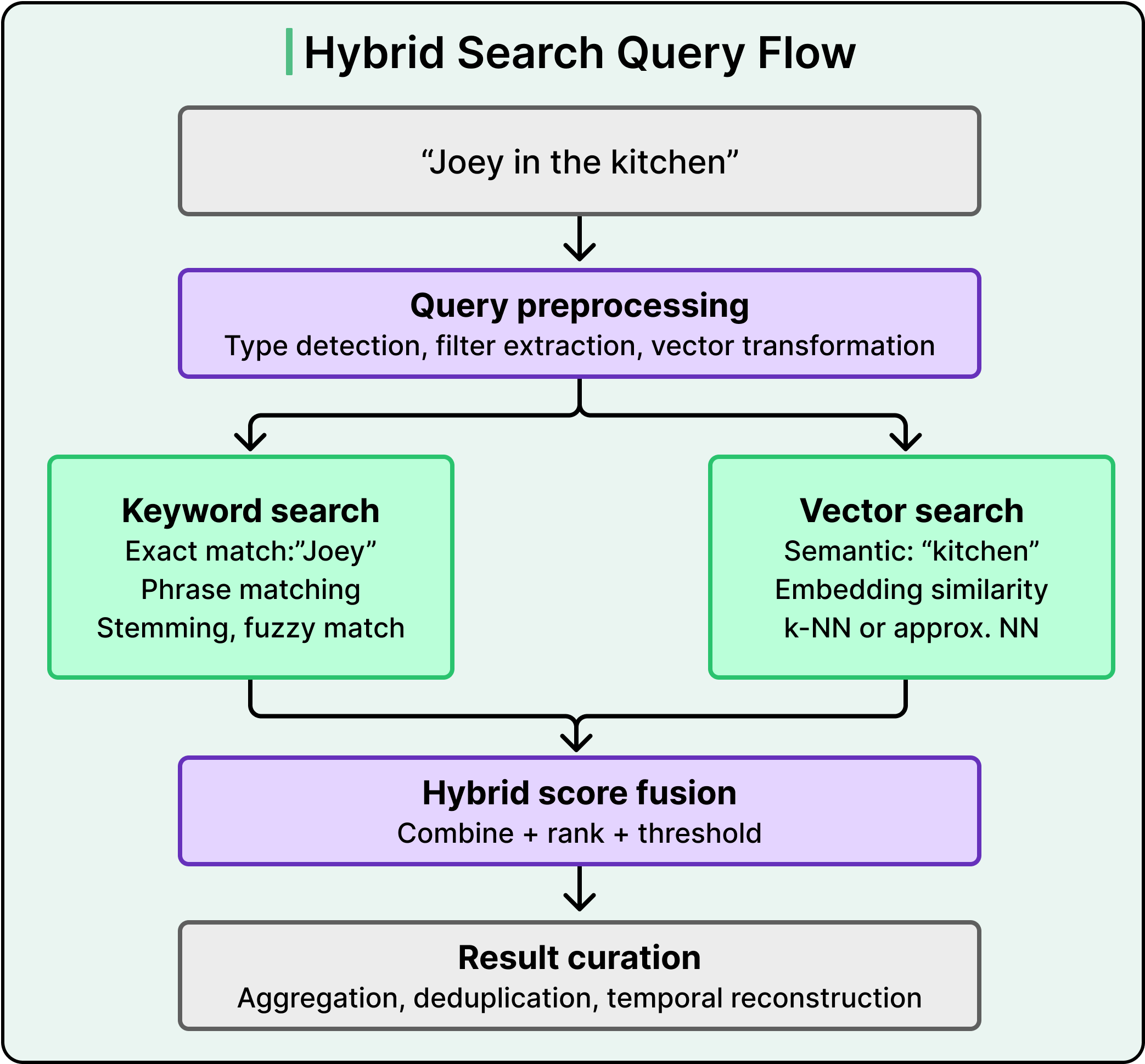
当查询到达时,系统会在触达索引前执行三阶段预处理:
- 查询类型检测动态分类请求,选择最高效的检索路径。
- 过滤提取分离语义约束(如角色名称或环境上下文),在启动高成本计算前缩小候选范围。
- 最后,向量转换将原始文本查询转化为高维模型特定嵌入,用于语义匹配。
系统将结构化查询计划编译为优化的Elasticsearch查询,并执行于预融合的时间桶。
类似"Joey在厨房"的查询需要两种根本不同的匹配方式。
"Joey"是专有名词需要精确关键词匹配。"Kitchen"作为语义概念则受益于向量相似度搜索——系统会比较查询嵌入与索引中场景嵌入的数学距离。
单独使用关键词搜索会遗漏相关术语标注,单纯向量搜索则难以处理专有名词和精确短语。两者的结合称为混合搜索(hybrid search),其表现始终优于单独使用任一方法。
Netflix为用户提供对混合引擎的精细控制。
他们可以在精确的k近邻搜索和近似最近邻算法之间切换。精确k近邻搜索能保证数学意义上的最接近匹配,但计算成本高昂;而近似最近邻算法则通过牺牲少量精度换取在大规模数据集上的显著加速。
他们可以选择不同的距离度量标准(如余弦相似度和欧氏距离),因为不同模型构建的向量空间特性不同,"相近"的定义取决于模型的训练方式。用户还可以设置置信度阈值,即过滤掉低概率匹配项,确保创意团队仅查看符合高相关性标准的结果。
涉及特定台词的搜索时,系统采用分层文本分析策略。
带有可配置“slop”参数的短语匹配功能,能控制搜索词允许的最大词语间隔,从而处理人类记忆的不完美。例如,用户若以略微错误的措辞搜索《怪奇物语》中的台词,系统仍能定位到正确场景。
基于索引词干片段的实时搜索功能,在编辑开始输入时即可返回精确到帧的结果。该功能通过摄取时预处理单词碎片实现。
多语言词干还原确保“running”能匹配标注为“run”或“ran”的场景,将语法变化统一为单一搜索意图。容错匹配可容忍字符级拼写错误,避免因转录误差丢失高价值片段。
原始搜索结果需经过后处理才能实用。
系统通过自定义聚合来聚类输出结果,例如按每集隔离某演员最相关的前5个片段。这可防止单个素材主导结果,并缓解因重复审阅数百个相似帧导致的疲劳感。时间重建层将内部桶边界转换为自然场景边界,使编辑看到连贯的场景级结果而非任意1秒切片。
根据查询意图,系统提供两种结果模式。并集模式返回所有匹配标注的完整时间跨度,优先广度覆盖,捕捉指定特征的任何出现实例。交集模式仅返回所有条件同时满足的精确重叠时段,优先精度。用户可自行选择模式。
Netflix的每个架构选择都涉及权衡,团队对需要付出的成本有明确判断。
离线融合导致新内容在跨模态完全可搜索前需经历延迟。Netflix选择吞吐量而非实时新鲜度,因为摄取时融合数据会拖慢整个管道。
对于每月增长数千小时的生产档案库,这种权衡合理;若需即时搜索则不适用。
精确与近似最近邻搜索的切换是精度与速度的直接权衡。精确k-NN保证最优匹配但规模扩大时计算成本激增,近似方法更快但可能遗漏部分相关结果。Netflix将此权衡交由用户选择而非自行决定。
集成方法本身是种赌注。
通过三阶段管道融合多个专用模型的输出,能实现各任务的高精度,但需要大量基础设施复杂度。单一统一模型可简化架构,但可能牺牲专业任务的精度。Netflix同时投资集成管道和MediaFM基础模型的事实表明,这种权衡尚未定论。
Netflix工程团队的当前系统是更大愿景的第一阶段,三个计划演进方向值得关注:
- 首先是自然语言发现。当前系统接受结构化查询负载,但目标是转向流畅的对话式界面,例如编辑可输入“查找汤姆·赫兰德在屋顶奔跑的最佳跟拍镜头”并获得结果,无需理解底层查询结构。
- 第二是自适应排序。通过构建分析编辑团队如何与片段互动和选择的机器学习反馈循环,系统将逐步自我调整相关性定义。搜索引擎将随使用进化,而非依赖静态评分算法。
- 第三是领域特定个性化。制作高动作预告片的团队与编辑叙事场景或进行深度档案研究的团队,其相关性标准不同。系统将动态调整搜索权重和检索行为以匹配用户场景。
这些扩展指向更宏大的目标:从搜索引擎进化为智能创意伙伴。
但当前系统已阐明重要架构经验:
当多个AI模型为同一实体生成不同数据时,最难的工程挑战在于融合层。模型本身固然重要,但持久化、对齐和索引其输出的管道才是系统运作的关键。
参考: