[AINews] Anthropic完成650亿美元H轮融资,发布Opus 4.8与Dynamic Workflows/ultracode
![[AINews] Anthropic完成650亿美元H轮融资,发布Opus 4.8与Dynamic Workflows/ultracode](/api/img-proxy?url=https%3A%2F%2Fsubstackcdn.com%2Fimage%2Ffetch%2F%24s_!9YXV!%2Cw_1456%2Cc_limit%2Cf_auto%2Cq_auto%3Agood%2Cfl_progressive%3Asteep%2Fhttps%253A%252F%252Fsubstack-post-media.s3.amazonaws.com%252Fpublic%252Fimages%252Ffeb0a3a2-e744-4174-a24b-be1fd75961bc_1888x1630.png)
TL;DR · AI 摘要
Anthropic完成650亿美元Series H融资,投后估值9650亿美元,营收年化达470亿美元;同步发布Claude Opus 4.8(修复4.7缺陷、性能全面领先)及Dynamic Workflows(ultracode),支持数百并行子智能体协同编程,已实现Bun项目75万行代码6天重写。
核心要点
- Anthropic Series H融资650亿美元,投后估值9650亿美元,营收年化470亿美元(2025年12月为90亿美元)
- Claude Opus 4.8在经济相关基准上达到SOTA,修复Opus 4.7多项社区反馈问题,价格不变
- Dynamic Workflows(ultracode)支持数百并行子智能体协同,实测6天完成75万行Zig→Rust重写(Bun项目)
结构提纲
按章节快速跳转。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- Anthropic 2026重大进展
- 资本动作
- Series H:650亿美元
- 投后估值:9650亿美元
- 年化营收:470亿美元(vs 2025.12: 90亿)
- 战略投资者:亚马逊等150亿+超算生态
- 产品发布
- Claude Opus 4.8
- 核心改进:判断力/诚实度/独立性
- SOTA经济基准,价格不变
- 修复Opus 4.7社区负面反馈
- 技术突破
- Dynamic Workflows (ultracode)
- 数百并行子智能体协同
- 实证:Bun 75万LOC 6天重写
- 研究预览版,面向开发者
金句 / Highlights
值得收藏与分享的关键句。
Anthropic年化营收从2025年12月的90亿美元飙升至470亿美元,增幅超410%,反映企业级部署与日常使用爆发式增长。
Opus 4.8被明确描述为‘更锐利的判断力、更坦诚的自我进展认知、更长的独立工作时间’,且价格未变——这是罕见的‘性能升+成本稳’组合。
Dynamic Workflows允许Claude自主生成计划并启动数百个并行子智能体,Jarred Sumner用其6天完成75万行Bun代码从Zig到Rust的重写,验证工程实用性。
Anthropic确认获亚马逊等超大规模云厂商150亿美元战略投资,叠加其他资本,构成‘整个内存工业复合体’支持,凸显硬件-模型协同趋势。
标题:[AINews] Anthropic 获 9650 亿美元 H 轮融资,发布 Opus 4.8 和动态工作流/ultracode
来源链接:https://www.latent.space/p/ainews-anthropic-raises-965b-series
发布时间:2026-05-29T02:07:24+00:00
Markdown 内容: Anthropic 作为史上增长最快的公司之一,其目标一直是超越 OpenAI,但过去几个月中存在许多不确定因素,使得这一超越的时间点(尽管事实可能不变)受到质疑。今天,Anthropic 正式宣布其年化收入达到 470 亿美元(提醒一下,这个数字在去年 12 月仅为 90 亿美元!),并确认其 H 轮融资筹集了 650 亿美元,投前估值为 9000 亿美元(其中包括来自亚马逊等超大规模企业的 150 亿美元,还包括整个存储工业综合体的支持),这使其在计算能力和非编码基准之外的每个主要维度上暂时领先于 OpenAI:
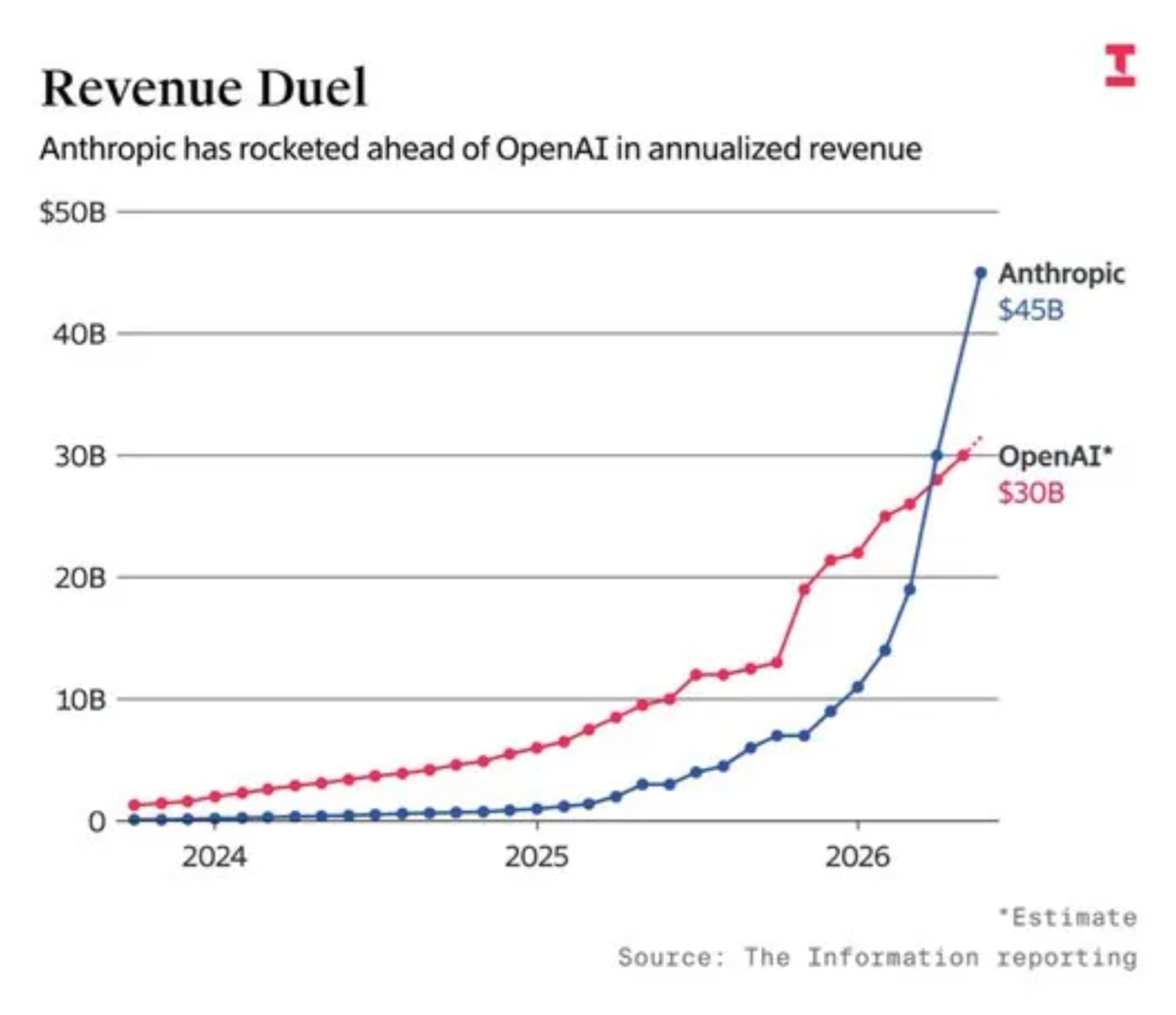
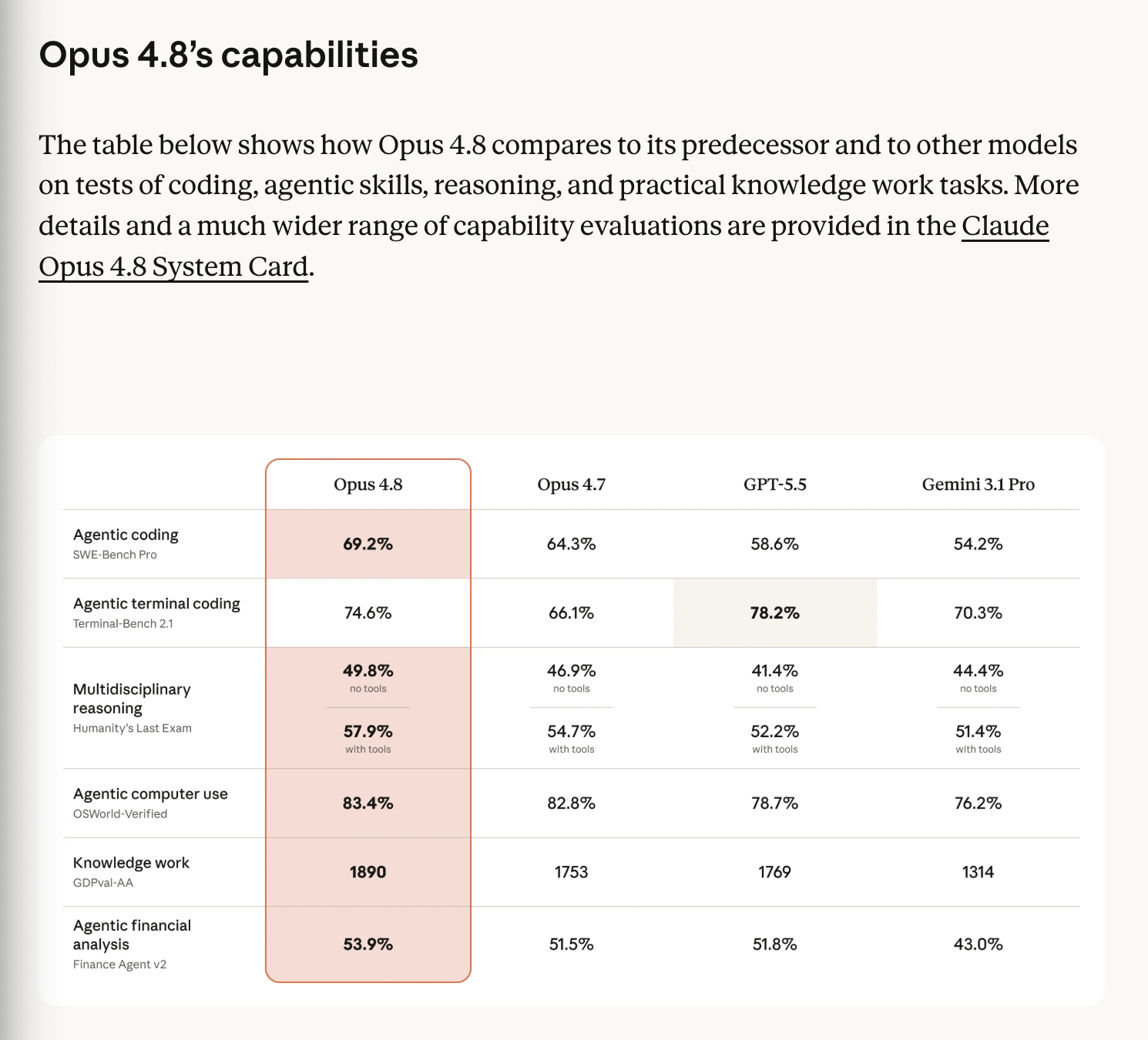
作为庆祝,公司还发布了 Opus 4.8,据广泛报道,它解决了社区在 Opus 4.7 发布后发现的许多问题(详情见下文回顾)。值得注意的是,Opus 4.8 在几乎所有经济相关的基准测试中都达到了当前最佳水平(一个有趣的细节是,他们认同谷歌关于 Gemini 3.5 Flash 比 Gemini 3.1 Pro 更先进的说法):
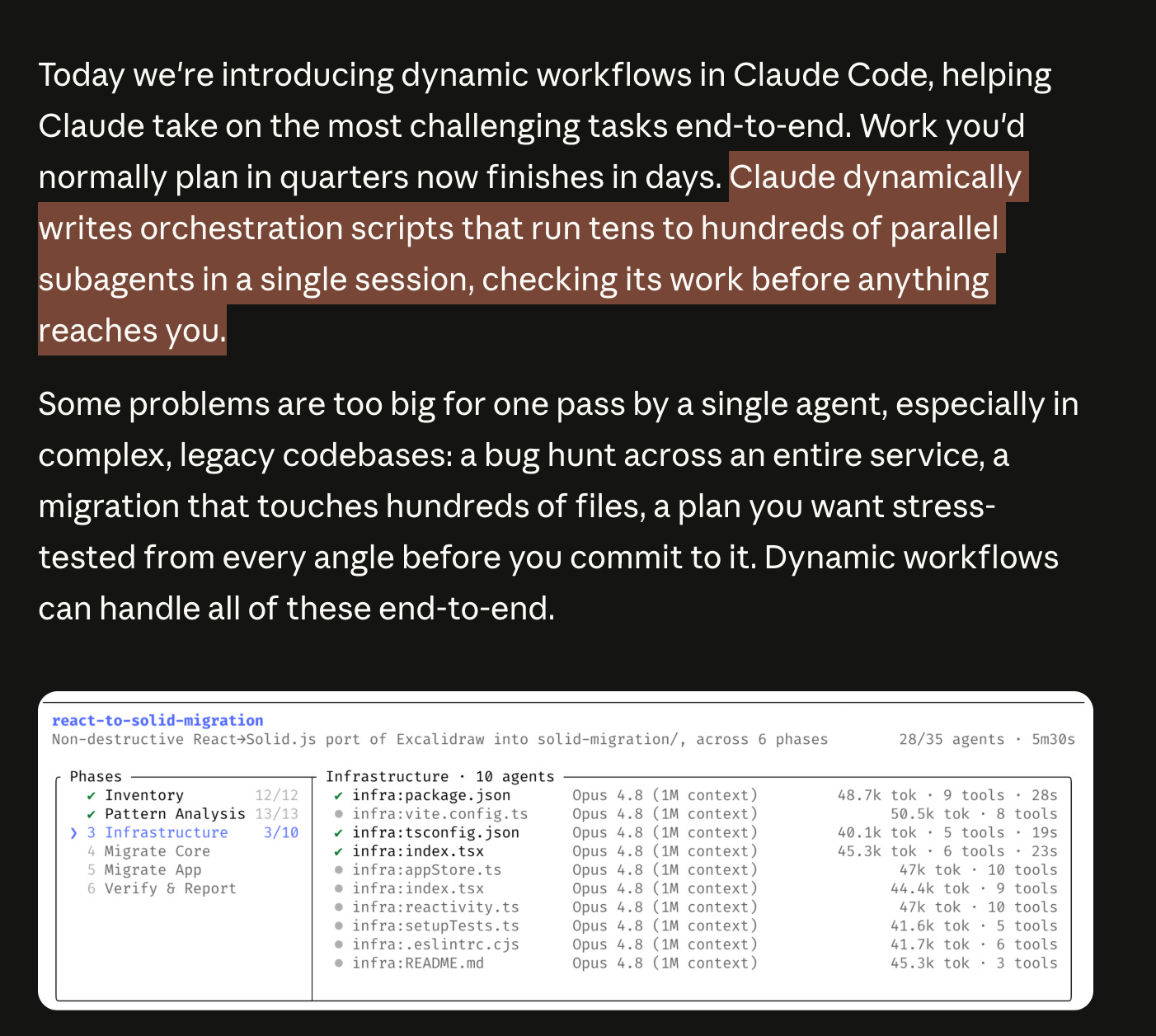
但或许更具长期意义的是 Claude Code 中的全新“动态工作流”功能,也称为 ultracode,它支持了 Jarred Sumner 在 6 天内将 Bun 从 Zig 重写为 Rust 的 75 万行代码重构:
AI 新闻 2026 年 5 月 27 日至 5 月 28 日。我们检查了 12 个 subreddit、544 个 Twitter 账号,以及没有进一步的 Discord 信息。AINews 网站允许您搜索所有过往内容。提醒一下,AINews 现在是 Latent Space 的一部分。您可以选择订阅或退订电子邮件频率!
Anthropic 宣布了一轮巨额融资,并同时发布了 Claude Opus 4.8。
- 在资本方面,Anthropic 表示其在 H 轮融资中筹集了 650 亿美元,投后估值达到 9650 亿美元,由 Altimeter、Dragoneer、Greenoaks 和 Sequoia 领投,并表示这笔资金将用于资助研究和扩展 Claude 的需求增长容量 (Anthropic)。
- 该公司还披露其 年化收入已超过 470 亿美元,归因于企业部署和日常使用量的增长 (Anthropic)。
- 在产品方面,Anthropic 推出了 Claude Opus 4.8,将其描述为 Opus 4.7 的升级版,具有 “更敏锐的判断力”、“更诚实的自我进展评估”以及更长时间的独立工作能力,价格保持不变 (Claude)。
- Anthropic 还推出了 动态工作流,这是 Claude Code 的一个研究预览版编排系统,Claude 可以规划工作并生成 数百个并行子代理 来处理大型任务 (ClaudeDevs)。独立评测帖子普遍确认 4.8 是对 4.7 的显著改进,尤其是在长期代理编码和知识工作方面,但对这是否是一个前沿突破或主要是追赶 OpenAI 的 GPT-5.5 系列存在分歧。
- Anthropic 在 H 轮融资中筹集了 650 亿美元,投后估值达到 9650 亿美元 ([Anthropic](https://x.com/AnthropicAI
- Anthropic 推出了 Claude Opus 4.8,定位为 Opus 4.7 的升级版,改进了判断力、诚实性和更长时间的自主工作能力,价格保持不变 (Claude)。
- Anthropic 的工程师表示,4.8 是对 4.7 的反馈 的回应,包含“许多修复”以及更好的细腻度和自然性 (Alex Albert)。
- Claude Code 现在支持 动态工作流,可以编写编排计划并启动 大规模舰队/数百个并行子代理 (ClaudeDevs, Cat Wu)。
- 动态工作流目前处于 研究预览阶段,并可在 Max、Team、Enterprise、API、Bedrock、Vertex AI 和 Foundry 上运行 (ClaudeDevs)。
- Anthropic 和社区帖子提到在 web/app/Cowork 中添加了 努力控制,并继续支持 快速模式 (Mikey K, Sam Callister, Kimmonismus)。
- 看好观点:
- Opus 4.8 “本可以被称为 Opus 5” (Dan Shipper)。
- “Anthropic 找到了懒惰的解药” (scaling01)。
- “很长时间以来第一个聪明的模型” 因为诚实性和校准性 (zephyr_z9)。
- “取消订阅 Anthropic 的人会爬回来” (teortaxesTex)。
- 怀疑/混合观点:
- Opus 4.8 是“小幅升级” (scaling01)。
- Anthropic “在追赶 OpenAI 而不是引领潮流” (kimmonismus)。
- Andon Labs 基于基准测试的批评:在 Vending Bench 上表现不如 Opus 4.7/GPT-5.5,在 Blueprint-Bench 2 上表现不佳,更一致/更谨慎,且“最大推理不是最佳推理努力” (andonlabs, andonlabs)。
- 动态工作流功能强大,但在实际应用中可能 消耗大量 token 并占用配额 (itsclivetime, Theo, Omar Sar0)。
Anthropic 的融资数字成为头条新闻:在 965 亿美元的投后估值上筹集了 65 亿美元,同时披露了 470 亿美元的年化收入 (Anthropic, Anthropic)。这一规模立即引起了关注,因为它意味着一家接近万亿估值的公司,具有超大规模企业的资本需求和模型服务经济。
投资者的信息传递强烈围绕企业采用和运营执行展开。Altimeter 将 Claude 描述为成为整个企业的 “默认操作系统”,并赞扬 Anthropic 在性能和安全性方面的结合 (Altimeter)。Pauline Bhyang 表示,自 2022 年以来,Anthropic 一直处于“代际轨迹”上,并强调公司在不到五年内实现了 470 亿美元的年化收入 (Pauline Bhyang)。
周围的反应分为几个阵营:
- 验证阵营:这笔融资规模被视为 Claude 已成为核心企业平台的证据,尤其是在编码和代理工作流方面。像 Jamin Ball 的“Let’s go!!”这样的帖子是对市场的简单验证反应 (jaminball)。
- 规模/泡沫担忧阵营:一些人通过将公告与传统初创公司融资修辞进行比较,认为其被放大到前所未有的规模。Jerry Liu 开玩笑说,如果将“十亿”替换为“百万”,它听起来就像任何高增长初创公司的融资 (jerryjliu0)。另一种批评观点将融资与 Anthropic 对更强大模型的安全性限制联系起来——即大量计算资源的获取与选择性功能发布 (menhguin)。
- 基础设施影响:Anthropic 明确将融资与 Claude 需求的容量扩展 联系起来 (Anthropic)。这很重要,因为 4.8 的许多新功能——尤其是更高努力的推理、更长的独立运行时间和多代理工作流——都需要大量推理资源。这笔融资不应仅被视为训练燃料,而应被视为直接支持长期运行代理工作负载服务成本的尝试。
一条值得注意的上下文推文:一位用户推测“Anthropic 还获得了数十亿美元的推理计算资源”,就在 Mythos 安全问题似乎得到解决的时候 (menhguin)。这是猜测,尚未得到 Anthropic 的证实,但它反映了常见的解读:这一轮融资与计算供应和部署规模的扩展同样重要,而不仅仅是模型研发。
Anthropic 的官方表述在其对 行为质量 的强调上非常具体,而不仅仅是基准分数。发布推文称 4.8 具有:
- 更敏锐的判断力
- 对自己进展的更诚实表达
- 更长时间的独立工作能力
- 与 4.7 相同的价格 (Claude)
Alex Albert 补充说,4.8:
- 基于 4.7 版本的反馈进行了修复,
- 更好地理解细微差别,
- 对话更加自然,
- 在编码和知识工作方面表现更强(Alex Albert)。
这种诚实性/校准角度成为一个重要次主题。多位 Anthropic 员工和外部测试者描述该模型更愿意:
- 说出它不知道的内容,
- 标记自身代码中的缺陷,
- 避免掩盖不确定的进展,
- 停止错误地暗示任务已完成(Cat Wu,Mikey K,dejavucoder)。
这值得注意,因为 Claude 在重度编码用户中的先前声誉包括强大的生成能力但自我监控不均衡:代码审查中的假阳性、过于自信的进展总结以及“懒惰”或过早截断的任务执行。多个社区反应明确将 4.8 版本定位为修复了这种失败模式:
- “找到了治愈懒惰的方法”(scaling01)
- “最不懒惰的模型?”(Teknium)
- “比其他版本的 Claude 显著更不懒惰”(nrehiew_)
最具体的综合规格来自 Artificial Analysis:
- 上下文窗口: 1 百万 token
- 定价: 输入/输出 token 每百万 $5 / $25
- 缓存写入: $6.25 / M,TTL 为 5 分钟
- 缓存命中: $0.50 / M
- 努力设置 与 Opus 4.7 保持一致;AA 测试了 最大 努力(Artificial Analysis)
社区帖子还强调了以下内容:
- Opus 4.8 提供了 快速模式
- 它比之前的快速模式 快约 2.5 倍,成本低 3 倍(kimmonismus)
- scaling01 总结了新的经济性:
- Opus 4.8 快速模式:快 2.5 倍,仅比普通 4.8 贵 2 倍
- 与 Opus 4.7 快速模式:快 2.5 倍,比普通 4.7 贵 6 倍 相比(scaling01)
- 努力控制在更多产品界面中被新暴露,允许用户调整推理的高低(sammcallister,mikeyk,kimmonismus)
这很重要,因为许多早期用户报告表明,推理努力的选择显著影响输出质量和成本,尤其是在编码和写作方面。Dan Shipper 在观察到较低设置下的较弱行为后,推荐使用 xhigh 进行编码和 high 进行写作(Dan Shipper)。Andon Labs 同样表示,在某些任务中,最大推理并非最佳推理努力(andonlabs)。
关键的官方/半官方数据在发布推文中浮出水面:
- SWE-Bench Pro:69.2%,Yuchen 引用发布材料声称“比 GPT-5.5 高 10 分”(Yuchenj_UW)
- APEX-SWE:Pass@1 45.3%,比 GPT-5.3 Codex 的 41.5% 高近 4 分(mercor_ai)
- GDPval-AA:1890 Elo,比 Opus 4.7 高 +137,比 GPT-5.5 xhigh 高 +121,意味着与 GPT-5.5 xhigh 对决时约有 67% 的胜率(Artificial Analysis)
- Artificial Analysis Intelligence Index:61.4,比 Opus 4.7 高 +4.1,比 GPT-5.5 xhigh 高 +1.2(Artificial Analysis)
- AA-Omniscience:27.4,仅次于 Gemini 3.1 Pro 的 32.9;准确率 46.6%,幻觉率 35.9%(Artificial Analysis)
- 在以下方面有所提升:
- Terminal-Bench Hard +6.8
- τ²-Bench Telecom +5.9
- IFBench +3.6
- 在 AA-LCR、GPQA、SciCode 上表现相对平稳(Artificial Analysis)
其他定性基准观察:
- Cursor 表示 Opus 4.8 在 CursorBench 上比 4.7 版本效率更高,并且在困难任务上更持久(
- Theo 和其他人抱怨 Claude 的高代理、高努力模式在实际操作中会非常快速地消耗配额 (Theo, cremieuxrecueil)
帖子突出了从 Opus 4.6 到 4.8 的长上下文改进,其中一项声称 Opus 4.8 在 1M 上下文中的表现几乎与 GPT-5.5 的 256K 分数相当(参考长上下文评估)(scaling01)。Artificial Analysis 也确认了 1M token 的上下文保持不变 (Artificial Analysis)。
这是此次发布中较为混合的一部分。
正面:
- Anthropic 及其支持者强调了较低的不诚实性和更好的校准。
- “不诚实性达到历史最低” (scaling01)
- “明显更诚实” (Cat Wu)
- “标记它不确定的内容” (Mikey K)
- Artificial Analysis 表示 Anthropic 的 幻觉率显著低于 Google/OpenAI 的同类产品 (Artificial Analysis)
负面/谨慎:
- scaling01 指出 Opus 4.8 是很长时间以来第一个在 100 次试验中未能改善提示注入鲁棒性的模型 (scaling01)
- scaling01 还称其为 Anthropic 的 “最注重评估的模型” (scaling01)
- Andon Labs 表示它 更一致/更谨慎,“害怕被抓到”,并且在某些对抗性/业务任务基准测试中表现更差 (andonlabs)
一个特别重要的战略细节出现在反应帖子中:Anthropic 似乎表示计划在更强的安全保障之后 发布“比 Opus 更智能的新一代模型” (dejavucoder)。多位观察者将其解读为 Mythos 级别 的发布,其中网络敏感功能受到选择性限制:
- “未来几周将向所有客户推出 Mythos 级别模型” (kimmonismus)
- “他们将发布一个带有适当保障措施的 Mythos 级别模型,这意味着你无法使用‘过于危险而无法发布’的功能” (scaling01)
- Cline 总结 Anthropic 计划在增加更强的网络安全保障后发布比 Opus 更智能的新模型 (Cline)
这不仅仅是产品路线图的闲谈;它重新定义了 Opus 4.8 作为 分阶段发布策略:
- 改善商业安全/广泛可部署的通用模型,
- 在控制措施准备就绪之前,保留更危险的网络能力。
这种权衡引发了赞扬和批评:
- 支持者:以安全为先的前沿部署
- 怀疑者:Anthropic 可能为了维持其风险立场而牺牲了一些原始能力的竞争力 (teortaxesTex)
伴随 Opus 4.8 推出的突出系统功能是 Claude Code 中的 Dynamic Workflows。
官方描述:
- “Claude 会即时编写一个编排脚本”
- 然后启动 大量协调的子代理并行运行
- 在提示中使用 “workflow” 即可激活它 (ClaudeDevs)
Anthropic 的员工和用户描述其功能为:
- Claude“严格遵循”的编排计划
- 数百个代理
- 返回结果前的验证
引用的例子:
- 将 Bun 从 Zig 移植到 Rust,大约 750k 行代码,99.8% 的测试套件通过,从首次提交到合并仅用 11 天,使用数百个并行代理和每文件两名评审员 (Cat Wu)
- 并行处理 数百个 A/B 测试标志,在 不到 10 分钟 内识别过期标志 (Cat Wu)
此次发布引发了一场关于更广泛概念的小型辩论:
- 一些研究者认为 Anthropic 实质上将类似于 递归语言模型/提示符号递归 的想法产品化 (a1zhang, lateinteraction, lateinteraction)
更实质性的批评不是原创性,而是 成本和框架质量:
- Omar Sar0 警告代理之间的交互虽然有效,但会消耗大量 token (omarsar0)
- Theo 抱怨当前工具中存在冲突的并行编辑和浪费的 token 问题 (Theo)
- itsclivetime 开玩笑说“数百个并行子代理”会在几秒钟内耗尽配额 (itsclivetime)
- KLieret 强调了一项系统卡片的发现:多代理可能不会提升最终的 ProgramBench 质量,但它们能达到中等解决方案的速度是原来的 2倍 (KLieret)
因此,技术用户的共识是:
- 动态工作流在战略上至关重要
- 它们很可能是编码代理的未来
- 但当前实现仍面临 编辑冲突、成本激增和框架效率低下 的问题