EP216: RAGs vs Agents

TL;DR · AI 摘要
RAG 和 Agent 是两种不同的 LLM 应用模式,RAG 适用于文档问答场景,Agent 更适合需要跨系统操作的任务。
核心要点
- RAG 通过检索知识库内容来生成答案,适合静态信息查询,成本低且易调试。
- Agent 使用工具链进行推理与行动,适合动态任务执行,但更复杂难调试。
- 选择 RAG 还是 Agent 取决于问题是否依赖外部系统交互
结构提纲
按章节快速跳转。
介绍 RAG 和 Agent 在 LLM 应用中的基本区别及其适用场景。
详细说明 RAG 的四个步骤:嵌入、检索、上下文注入和生成回答。
描述 Agent 的四个阶段:输入处理、工具选择、执行反馈和循环决策。
从灵活性、资源消耗和调试难易程度等方面比较两种方法。
提供何时使用 RAG 或 Agent 的实用建议。
推荐关于 Claude Code 的培训课程,帮助开发者掌握高级 AI 工具使用技巧。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- RAG vs Agent
- RAG
- 检索 + 生成
- 文档问答
- Agent
- 推理 + 工具调用
- 动作执行
金句 / Highlights
值得收藏与分享的关键句。
RAG 结合 LLM 与检索机制,将答案基于知识库内容生成,适合文档问答场景。
Agent 包含一个推理循环,允许 LLM 调用工具完成任务,适用于需要跨系统操作的场景。
RAG 成本低、易调试,而 Agent 更灵活但难以调试,因为错误可能分散在多个步骤中。
标题:EP216:RAGs 与 Agents 的对比
原文链接:https://blog.bytebytego.com/p/ep216-rags-vs-agents
发布日期:2026-05-23T15:31:18+00:00
QA Wolf 的 AI agent 可以映射并测试您应用程序中最复杂的用户流程。它将您的提示转换为真正的 Playwright 和 Appium 代码,运行速度比其他计算机使用 agent 快 12 倍且更可靠。
我们 AI 的独特之处在于:
- 在几分钟内映射 200 多个测试用例,而不是手动规划数周。
- 执行测试速度比计算机使用 agent 快 12 倍。
- 以 100% 并行方式 运行整个测试套件,并保证结果一致性。
- 生成团队可拥有的开源测试,零供应商锁定。
本周的系统设计复习内容包括:
- RAGs 与 Agents 的区别
- 使用 Claude Code 构建:新一期课程启动
- 正向代理、反向代理和 API 网关详解
- 请求是如何真正通过 Claude Code 传输的?
- Claude Code 是如何防止长时间会话因上下文不足而失效的?
向 LLM 提问关于公司数据的问题时,它只会猜测。解决这个问题的两种模式是 RAG 和 Agent,它们解决了不同的问题。
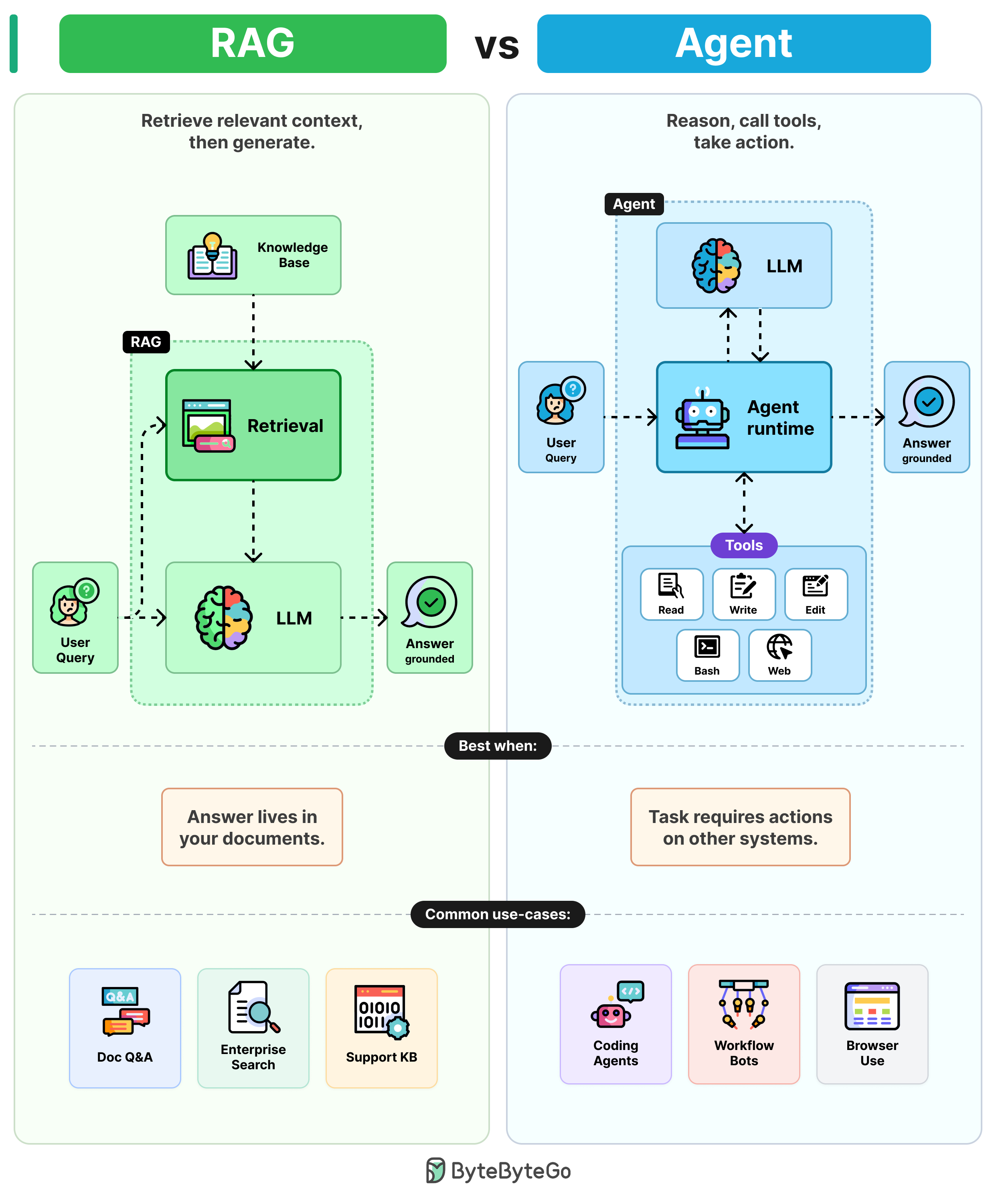
RAGs:RAGs 将 LLM 与检索结合,通过四个步骤来提供基于事实的答案。
- 第一步:用户查询被嵌入后发送到检索步骤。
- 第二步:检索从知识库(PDF、维基等)中提取最相关的片段。
- 第三步:这些片段作为上下文被粘贴到提示中。
- 第四步:LLM 基于检索到的内容撰写答案。
一次检索,一次生成。成本低、可预测且易于调试。
Agents:Agents 将 LLM 包装在一个推理循环中,并配备工具以执行操作。
- 第一步:用户查询进入 agent 运行环境。这是一个围绕 LLM 的推理循环。
- 第二步:LLM 读取目标并选择一个工具(读取、写入、编辑、Bash 等)。
- 第三步:运行环境执行该工具并将结果反馈给 LLM。
- 第四步:LLM 再次推理,选择下一个工具,并循环直到任务完成。
更加灵活,但需要更多 token。由于错误可能跨步骤扩散,调试起来更困难。
经验法则:当答案存在于你的文档中时使用 RAG;当答案需要对其他系统进行操作时使用 agent。
轮到你了:你更喜欢使用 RAG 而不是 agent 的场景是什么?
我们即将推出一门为期两天的强化课程,名为《Build with Claude Code》,由 John Kim 教授,他曾培训过数百名 Meta 工程师在实际生产环境中使用 Claude Code。
课程将于 5 月 28 日开始。

你将学到的内容包括:
- 使 Claude Code 对真实项目有用的代理循环、上下文工程和记忆层
- 如何使用 Claude Code Skills、MCPs 和钩子来赋予 Claude 所需的工具和反馈机制,使其能够自我纠错
- 使用 Git worktrees、子 agent 和 agent 团队进行并行开发
- 一个结业项目,让你在自己的技术栈上构建一个真实的成果
课程包含实时会话、作业和办公时间,因此有充足的机会提问和解决问题。
第一期课程将在几天内开始:2026 年 5 月 28 日至 29 日。如果你想从 Claude Code 的基础到高级生产工作流全面学习,包括处理大型代码库,这可能是一个提升技能的好方法。
人们经常混淆这两者,因为它们都位于客户端和服务器之间。真正的区别在于它们所代表的一侧以及解决的问题不同。
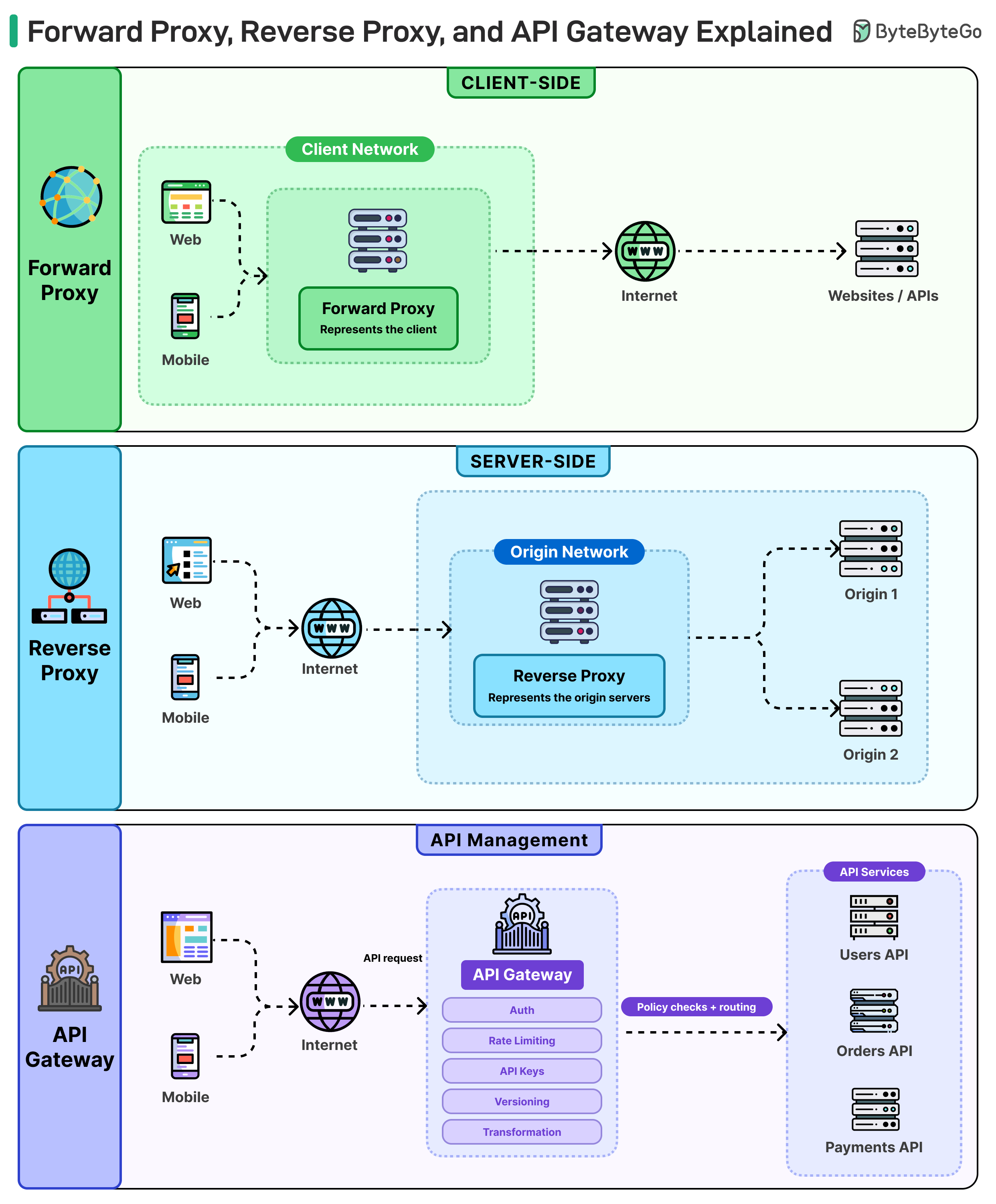
正向代理位于客户端旁边。你的笔记本电脑发送请求,代理转发请求,而目标服务器看不到你的真实 IP。企业网络使用这种机制来实施策略、阻止网站和缓存流量。
反向代理位于服务器旁边。客户端不知道在其背后有多少台机器。代理决定谁来处理请求,终止 TLS,并将你的后端隔离在公共互联网之外。NGINX 和 HAProxy 经常用于此,通常与负载均衡器配合使用。
API 网关是一种功能更强的反向代理,不仅负责路由流量,还处理认证、速率限制、API 密钥、版本控制和请求格式化。没有它,每个微服务都必须自行实现验证、限流逻辑和请求日志记录。
前向代理代表客户端,反向代理代表服务器,而 API 网关则是在需要对十个服务应用相同的认证和限流规则时所添加的组件。
在大多数实际系统中,这三者运行在不同的层级上。前向代理过滤出站流量,反向代理位于应用服务器前面,而 API 网关则位于你的 API 前面,用于在请求到达之前强制执行策略。
轮到你了:你们团队使用的代理 + 网关组合是什么?总是很有趣看到不同团队是如何搭配这些工具的。
我们大多数人输入一个提示词,然后看着“魔法”发生。下图展示了基于 Claude Code 源码背后真正发生的情况:
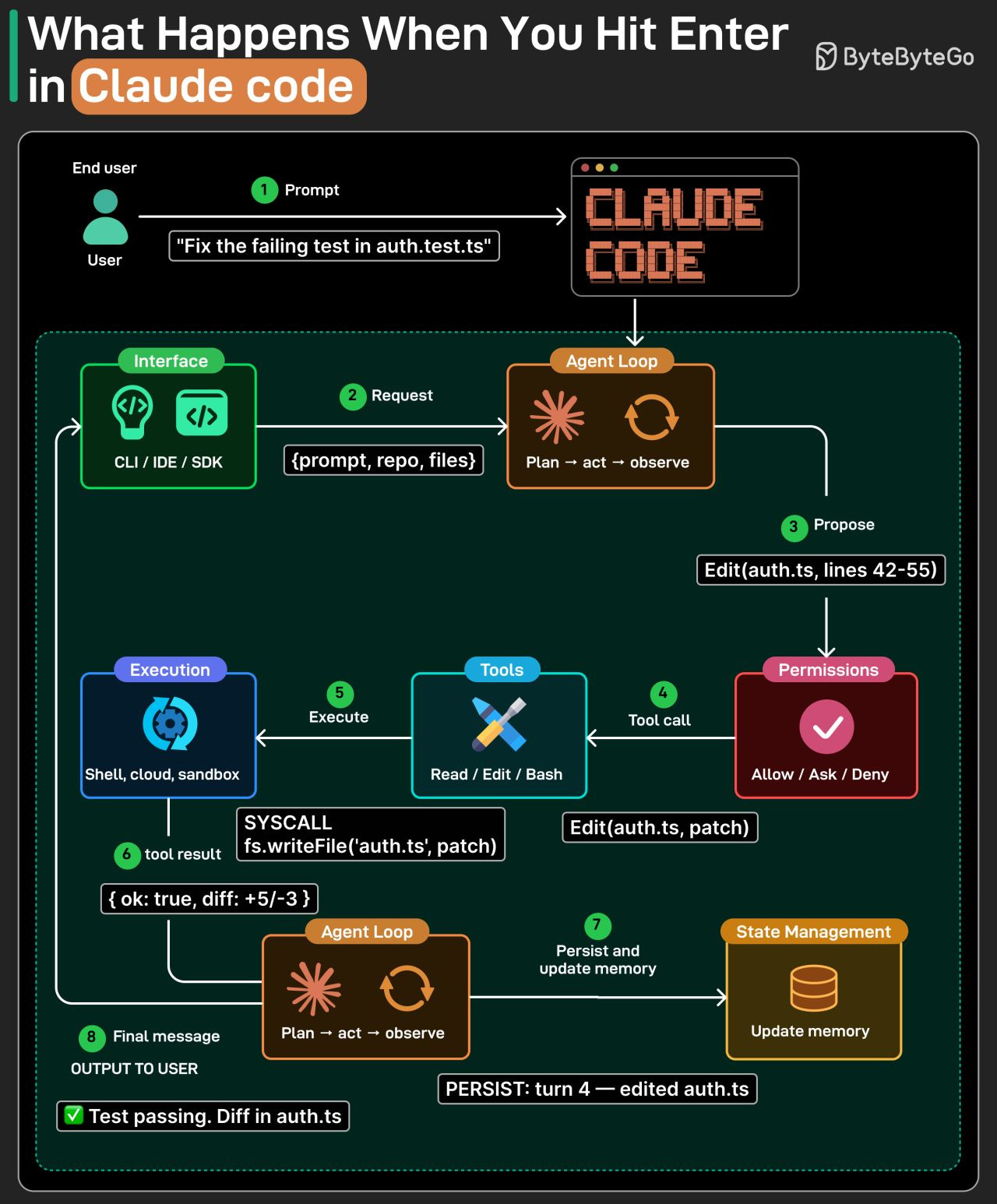
让我们追踪一个真实的请求:“修复 auth.test.ts 中失败的测试。”
- 第一步:用户通过其界面将提示词发送给 Claude Code。
- 第二步:界面(CLI、IDE 或 SDK)将提示词与仓库和文件上下文包装在一起,并将其作为请求传递给代理循环。
- 第三步:代理循环规划下一步操作并提出一个动作:Edit(auth.ts, 第 42–58 行)。
- 第四步:权限系统检查该提议的动作是否符合规则。
- 第五步:批准的动作变成一次工具调用:Edit(auth.ts, patch),并分发给匹配的工具。
- 第六步:工具在执行环境中(shell、云或沙箱)以真实系统调用的形式运行。
- 第七步:执行返回工具结果给代理循环。
- 第八步:代理将此次交互保存到状态中,并将最终消息流式传输给用户。
整个系统就是这样一个循环,直到模型不再请求工具为止。
轮到你了:在构建自己的编码代理时,你觉得这个循环中的哪一步最难做对?
它使用了 5 种策略,在每次模型调用之前依次运行。只有当下一个策略无法释放足够空间时,才会运行下一个。
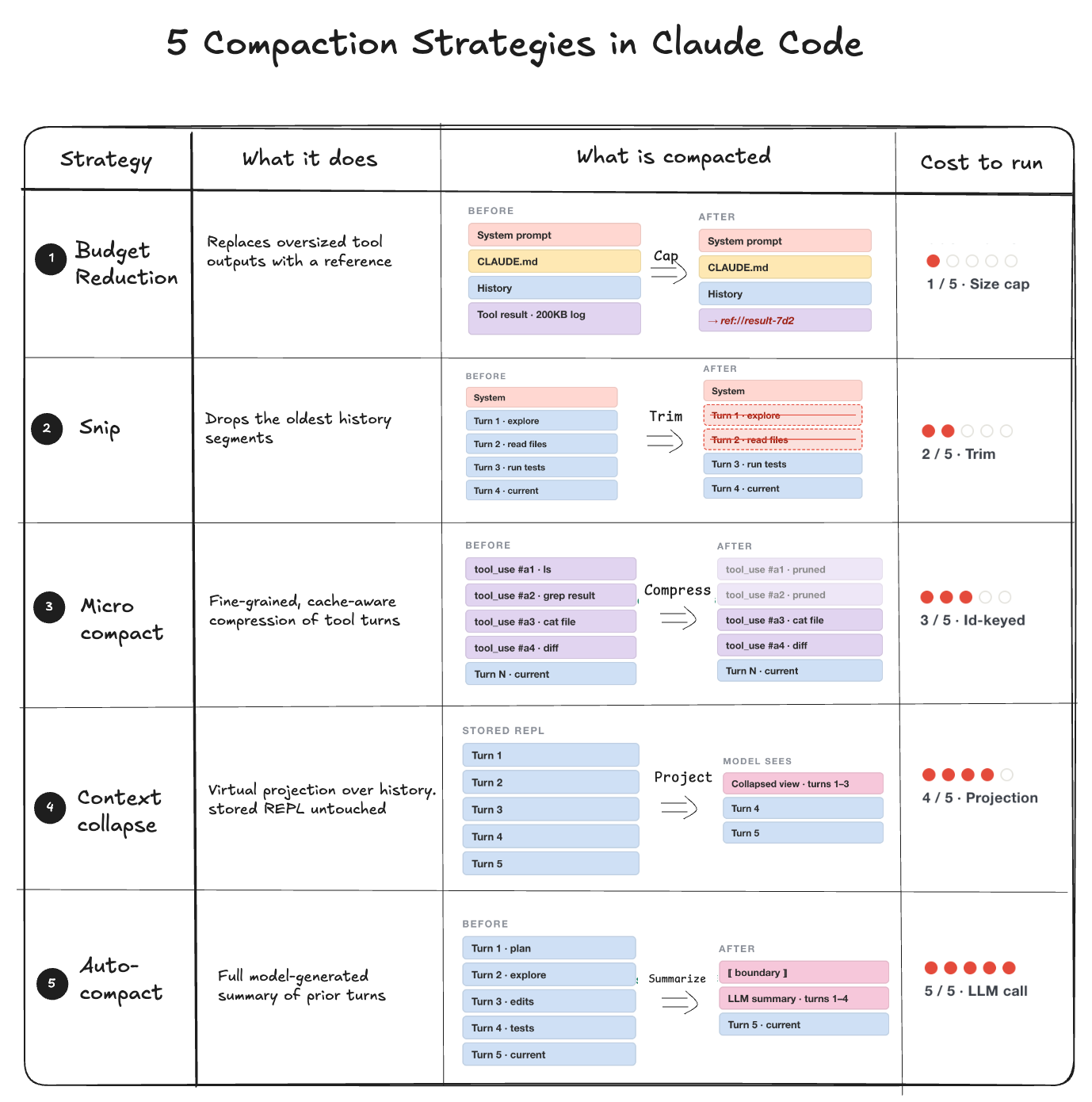
- 预算削减:限制单个工具结果的大小。过大的输出会被替换为内容引用。
- 截断:修剪最旧的历史片段并发出边界标记。
- 微压缩:通过 tool_use_id 删除工具回合,以保持提示缓存活跃。
- 上下文坍缩:对完整历史记录进行读取时投影。
- 自动压缩:最后手段。它会调用模型来生成先前回合的完整摘要。
这种模式是惰性降级:首先应用影响最小的处理方式,仅在更便宜的层不足以解决问题时才升级。
轮到你了:你多久会遇到上下文不足的问题?