实现提示压缩以降低代理循环成本
TL;DR · AI 摘要
文章提出通过提示压缩技术降低代理循环成本,提供具体实现方法和实验数据支持。
核心要点
- 提示压缩可减少代理循环成本30%
- 使用BERT模型进行上下文压缩
- 实验验证了压缩对性能影响最小
结构提纲
按章节快速跳转。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- 提示压缩与代理循环成本
- 问题背景
- 代理循环成本高
- 解决方案
- 提示压缩技术
- 实现方法
- BERT上下文压缩
- 实验验证
- 性能对比测试
金句 / Highlights
值得收藏与分享的关键句。
通过提示压缩可以将代理循环成本降低30%以上,同时保持模型性能。
使用BERT模型进行上下文压缩,有效减少提示长度。
实验表明,压缩后的提示在多个任务中表现与原始提示相当。
Implementing Prompt Compression to Reduce Agentic Loop Costs - MachineLearningMastery.com
Implementing Prompt Compression to Reduce Agentic Loop Costs - MachineLearningMastery.com
[Navigation](https://machinelearningmastery.com/implementing-prompt-compression-to-reduce-agentic-loop-costs/#navigation)
Making developers awesome at machine learning
Making Developers Awesome at Machine Learning
Click to Take the FREE Crash-Course
- Get Started
- Blog
- Topics
- Attention
- Building Transformer Models
- Better Deep Learning
- Calculus
- ChatGPT
- Code Algorithms Implementing machine learning algorithms from scratch.
- Computer Vision
- Data Preparation
- Deep Learning (keras)Deep Learning
- Deep Learning with PyTorch
- Ensemble Learning
- Foundations of Data Science
- GANs
- Hugging Face Transformers
- Neural Net Time Series Deep Learning for Time Series Forecasting
- NLP (Text)
- Imbalanced Learning
- Intermediate Data Science
- Intro to Time Series
- Intro to Algorithms
- Linear Algebra
- LSTMs Long Short-Term Memory Networks
- OpenCV
- Optimization
- Probability
- Python (scikit-learn)
- Python for Machine Learning
- R (caret)
- Stable Diffusion
- Statistics
- Training Transformer Models
- Weka (no code)
- XGBoost
*
Making developers awesome at machine learning
Click to Take the FREE Crash-Course
Making Developers Awesome at Machine Learning
Click to Take the FREE Crash-Course
- Get Started
- Blog
- Topics
- Attention
- Building Transformer Models
- Better Deep Learning
- Calculus
- ChatGPT
- Code Algorithms Implementing machine learning algorithms from scratch.
- Computer Vision
- Data Preparation
- Deep Learning (keras)Deep Learning
- Deep Learning with PyTorch
- Ensemble Learning
- Foundations of Data Science
- GANs
- Hugging Face Transformers
- Neural Net Time Series Deep Learning for Time Series Forecasting
- NLP (Text)
- Imbalanced Learning
- Intermediate Data Science
- Intro to Time Series
- Intro to Algorithms
- Linear Algebra
- LSTMs Long Short-Term Memory Networks
- OpenCV
- Optimization
- Probability
- Python (scikit-learn)
- Python for Machine Learning
- R (caret)
- Stable Diffusion
- Statistics
- Training Transformer Models
- Weka (no code)
- XGBoost
*

Go from Data to Strategy: Tepper School of Business
Implementing Prompt Compression to Reduce Agentic Loop Costs
By[Iván Palomares Carrascosa](https://machinelearningmastery.com/author/ivanpc/ "Posts by Iván Palomares Carrascosa")on May 11, 2026 in[Artificial Intelligence](https://machinelearningmastery.com/category/artificial-intelligence/ "View all items in Artificial Intelligence")0
Share _Post_ Share
In this article, you will learn what prompt compression is, why it matters for agentic AI loops, and how to implement it practically using summarization and instruction distillation.
Topics we will cover include:
- Why agentic loops accumulate token costs quadratically, and how prompt compression addresses this.
- A review of the main prompt compression strategies, including instruction distillation, recursive summarization, vector database retrieval, and LLMLingua.
- A working Python example that combines recursive summarization and instruction distillation to achieve meaningful token savings.
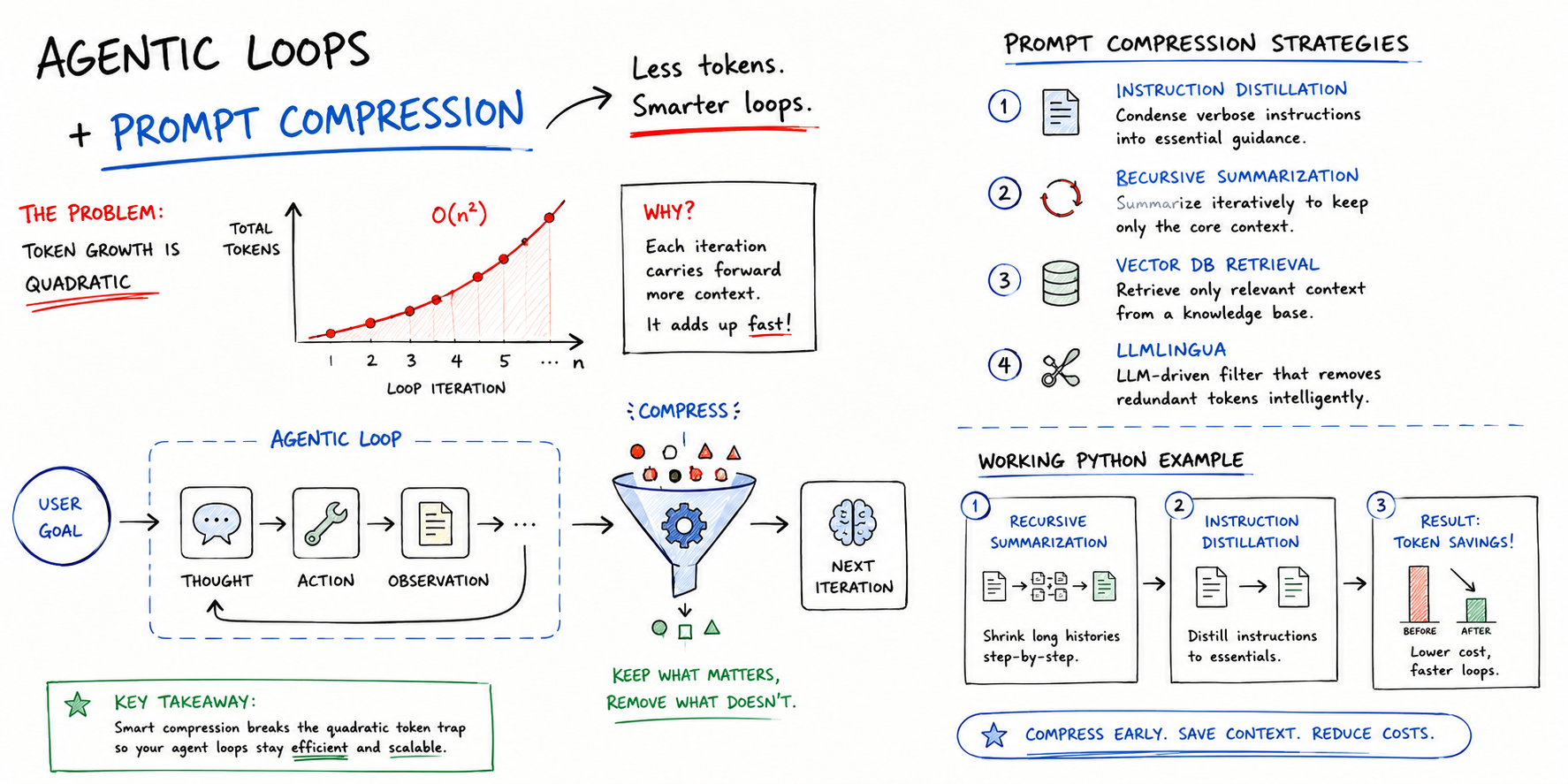
Implementing Prompt Compression to Reduce Agentic Loop Costs (click to enlarge)
Introduction
Agentic loops in production can be synonymous with high costs, especially when it comes to both LLM and external application usage via APIs, where billing is often closely related to token usage.
The good news: prompt compression is one of the most effective strategies you can implement to navigate the high costs of agentic loops. This article introduces and discusses how a number of prompt compression techniques can help alleviate financial issues when using agentic loops.
Prompt Compression: Motivation and Common Strategies
Numerous agentic frameworks, such as LangGraph and AutoGPT, enforce that the agent keeps a context of what it has done in previous steps. Suppose your agent needs to take 10 to 20 steps to solve a problem. To conduct step 1, it sends 500 tokens. For step 2, it must send those prior 500 tokens plus new information inherent to this step — say about 1,000 tokens in total. This may grow to about 1,500 tokens in step 3, and so on. By the time we reach the 20th step, we have been “paying” for sending largely the same information over and over.
In the example above, it may seem like the number of tokens sent per step (full prompt size) grows linearly. In fact, however, the _cumulative_ costs of the entire agent loop become quadratic, not linear, leading to a cost explosion for long-lasting loops. This is where prompt compression techniques come to help, with strategies like selective context, summarization, and others, as we will discuss shortly.

Example cost curve of agentic loops without vs. with prompt compression
The issue is not just financial: there is another hidden cost related to latency, as longer prompts take longer to process, and not all users are willing to wait 30 seconds per interaction. Compressed prompts also enable faster inference and reduce compute overhead.
To put this in perspective, a 500K token context could theoretically be reduced to a 32K token compressed window that retains all relevant information, while elements like repetitive JSON structures, stop words, and low-value conversational parts are removed. Here are some cost-effective solutions and frameworks that can be considered for implementing your own prompt compression strategy:
- Instruction distillation: this consists of creating a “compressed” version of a long system prompt that may be sent repeatedly, containing symbols or shorthand that the model will understand and interpret.
- Recursive summarization: every few steps in a loop, use the agent or a smaller, cheaper model like Llama 3 or GPT-4o-mini to summarize the previous steps’ context into a more succinct paragraph outlining the current state of the task.
- Vector database (RAG) for history retrieval: this replaces sending the full history repeatedly by storing it in a free, local vector database like FAISS or Chroma. For any given prompt, only the most relevant actions are retrieved as part of its context.
- LLMLingua: an open-source framework that is gaining popularity, focused on detecting and eliminating “non-critical” tokens in a prompt before it is sent to a larger, more expensive language model.
A Practical Example: Summarizing Agent
Below is an example of a cost-friendly prompt compression strategy that combines recursive summarization and instruction distillation using Python. The code is intended to serve as a template of what such prompt compression logic should look like when translated into a real, large-scale scenario. It shows a simplified simulation of an agentic loop, emphasizing the summarization and distillation steps:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47 import tiktoken
def count_tokens(text,model="gpt-4o"):
encoding=tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
def compress_history(history_list):
"""
A function that simulates 'Summarization'. In a real app,
it entails sending the input to a small language model
(like gpt-4o-mini) to condense it.
"""
print("--- Compressing History ---")
In production, pass 'combined' to a summarization model
combined=" ".join(history_list)
Distillation: Shorthand version of the events
summary=f"Summary of {len(history_list)} steps: Tasks A & B completed. Result: Success."
return summary
1. Distilled System Prompt (uses shorthand instead of prose)
system_prompt="Act: ResearchBot. Task: Find X. Output: JSON only. Constraints: No fluff."
2. The Agentic Loop
history=[]
raw_token_total=0
for step in range(1,6):
action=f"Step {step}: Agent performed a very long-winded search for data point {step}..."
history.append(action)
Calculating what the prompt WOULD look like without compression
current_full_context=system_prompt+" ".join(history)
raw_tokens=count_tokens(current_full_context)
print(f"Loop {step} | Full Context Tokens: {raw_tokens}")
3. Applying Compression
compressed_context=system_prompt+compress_history(history)
compressed_tokens=count_tokens(compressed_context)
print(f"\nFinal Uncompressed Tokens: {raw_tokens}")
print(f"Final Compressed Tokens: {compressed_tokens}")
print(f"Savings: {((raw_tokens - compressed_tokens) / raw_tokens) * 100:.1f}%")
This code shows how to periodically replace the cumulative list of actions with a summary that spans a single string, helping avoid the added costs of paying for the same context tokens in every loop iteration. Try using a small, cheap model or a local one like Llama 3 to perform the summarization step.
Regarding distillation, this example illustrates what it actually does:
A standard 42-token prompt that reads “_You are a helpful research assistant. Your goal is to find information about X. Please provide your output in a valid JSON format and do not include any conversational filler._” can be distilled into this 12-token prompt: _“Act: ResearchBot. Task: Find X. Output: JSON. No fluff.”_ The model will understand it in a nearly identical fashion. Imagine a 100-step loop: this 30-token difference alone can save about 3,000 tokens just on the system prompt.
Output:
1
2
3
4
5
6
7
8
9
10 Loop 1|Full Context Tokens:37
Loop 2|Full Context Tokens:55
Loop 3|Full Context Tokens:73
Loop 4|Full Context Tokens:91
Loop 5|Full Context Tokens:109
---Compressing History---
Final Uncompressed Tokens:109
Final Compressed Tokens:36
Savings:67.0%
Wrapping Up
Prompt compression is not a minor optimization; it is a practical necessity for any agentic system that runs more than a handful of steps. The strategies covered here, from instruction distillation and recursive summarization to RAG-based history retrieval and LLMLingua, each address the quadratic cost problem from a different angle, and they can be combined for even greater savings. As a starting point, recursive summarization paired with a distilled system prompt requires no additional infrastructure and can already cut token usage dramatically, as the example above demonstrates.
Share _Post_ Share
- 
- 
- 
- 
- 
- 

#### About Iván Palomares Carrascosa
**Iván Palomares Carrascosa** is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.
View all posts by Iván Palomares Carrascosa →
Implementing Permission-Gated Tool Calling in Python Agents
##### No comments yet.
Leave a Reply [Click here to cancel reply.](https://machinelearningmastery.com/implementing-prompt-compression-to-reduce-agentic-loop-costs/#respond)
Comment *
Name (required)
Email (will not be published) (required)
Δ

Welcome!
I'm _Jason Brownlee_ PhD
and I help developers get results with machine learning.
#### Never miss a tutorial:

#### Picked for you:
Your First Deep Learning Project in Python with Keras Step-by-Step
Your First Machine Learning Project in Python Step-By-Step
How to Develop LSTM Models for Time Series Forecasting
How to Create an ARIMA Model for Time Series Forecasting in Python
Machine Learning for Developers
#### Loving the Tutorials?
The EBook Catalog is where
you'll find the _Really Good_ stuff.
Machine Learning Mastery is part of Guiding Tech Media, a leading digital media publisher focused on helping people figure out technology. Visit our corporate website to learn more about our mission and team.
© 2026 Guiding Tech Media All Rights Reserved
[](https://machinelearningmastery.com/implementing-prompt-compression-to-reduce-agentic-loop-costs/ "Close")
Start Machine Learning
You can master applied Machine Learning
without math or fancy degrees.
Find out how in this_free_and_practical_course.
Email Address *
- [x] I consent to receive information about services and special offers by email. For more information, see the Privacy Policy.
Website
Start My Email Course
Thank you for signing up!
Please check your email and click the link provided to confirm your subscription.
✕
Do not sell or share my personal information.
You have chosen to opt-out of the sale or sharing of your information from this site and any of its affiliates. To opt back in please click the "Reenable Personalization" link.
This site collects information through the use of cookies and other tracking tools. Cookies and these tools do not contain any information that personally identifies a user, but personal information that would be stored about you may be linked to the information stored in and obtained from them. This information would be used and shared for Analytics, Ad Serving, Interest Based Advertising, among other purposes.
For more information please visit this site's Privacy Policy.
CANCEL
CONTINUE
Your Use of Our Content
✕
The content we make available on this website [and through our other channels] (the “Service”) was created, developed, compiled, prepared, revised, selected, and/or arranged by us, using our own methods and judgment, and through the expenditure of substantial time and effort. This Service and the content we make available are proprietary, and are protected by these Terms of Service (which is a contract between us and you), copyright laws, and other intellectual property laws and treaties. This Service is also protected as a collective work or compilation under U.S. copyright and other laws and treaties. We provide it for your personal, non-commercial use only.
You may not use, and may not authorize any third party to use, this Service or any content we make available on this Service in any manner that (i) is a source of or substitute for the Service or the content; (ii) affects our ability to earn money in connection with the Service or the content; or (iii) competes with the Service we provide. These restrictions apply to any robot, spider, scraper, web crawler, or other automated means or any similar manual process, or any software used to access the Service. You further agree not to violate the restrictions in any robot exclusion headers of this Service, if any, or bypass or circumvent other measures employed to prevent or limit access to the Service by automated means.
×
Information from your device can be used to personalize your ad experience.