NVIDIA Nemotron 3 Ultra现已登陆Amazon SageMaker JumpStart

TL;DR · AI 摘要
NVIDIA Nemotron 3 Ultra已在Amazon SageMaker JumpStart上线,支持一键部署。该550B参数MoE模型专为长程Agent设计,推理速度提升5倍,成本降低30%,支持1M上下文。
核心要点
- Nemotron 3 Ultra采用混合Transformer-Mamba MoE架构,550B总参仅激活55B,显著降低Agent任务计算开销。
- 针对Agentic工作负载优化NVFP4精度,实现5倍推理加速和30%成本节约,适合多步推理与工具调用场景。
- 通过SageMaker JumpStart一键部署,支持ml.p5en/g7e等GPU实例,提供Studio界面与Python SDK两种接入方式。
结构提纲
按章节快速跳转。
NVIDIA Nemotron 3 Ultra在SageMaker JumpStart首日可用,为Agent场景提供5倍推理加速和30%成本优化。
该模型基于混合Transformer-Mamba MoE架构,拥有550B总参数和55B激活参数,支持1M token上下文长度。
MoE稀疏激活机制使模型在百万级上下文中保持高吞吐,支撑数百轮次的规划、工具调用与自我修正循环。
适用于Agent编排、代码生成调试、深度研究及复杂业务流程自动化等需持续多步推理的任务。
用户可通过SageMaker Studio界面或Python SDK一键部署模型,需注意GPU实例计费并及时释放端点资源。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- Nemotron 3 Ultra on SageMaker
- 模型特性
- 550B/55B MoE架构
- 1M Token上下文
- NVFP4精度优化
- Agent场景优势
- 5倍推理加速
- 30%成本降低
- 多步推理与工具调用
- 部署方式
- SageMaker Studio一键部署
- Python SDK集成
金句 / Highlights
值得收藏与分享的关键句。
Nemotron 3 Ultra为Agentic工作负载提供5倍推理加速和高达30%的成本降低。
其MoE架构每次前向传播仅激活550B参数中的55B,即使在百万token上下文长度下也能保持高吞吐量。
Agent并非只回答一次,它们会规划、调用工具、委派子代理、检查结果,并在数百轮对话中持续运行。
部署此模型会创建SageMaker端点并在运行期间产生费用,ml.p5en.48xlarge等GPU实例每小时成本可达数美元。
标题:NVIDIA Nemotron 3 Ultra 现已在 Amazon SageMaker JumpStart 上线 | Amazon Web Services
URL 来源:https://aws.amazon.com/blogs/machine-learning/nvidia-nemotron-3-ultra-now-available-on-amazon-sagemaker-jumpstart/
发布时间:2026-06-04T08:59:08-08:00
Markdown 内容:
[人工智能](https://aws.amazon.com/blogs/machine-learning/)
今天,我们很高兴地宣布 NVIDIA Nemotron 3 Ultra 已在 Amazon SageMaker JumpStart 实现首日上线。
通过此次发布,您现在可以使用一键部署体验来部署 Nemotron 3 Ultra 模型。Nemotron 3 Ultra 是一个开放模型,专为长期运行的自主智能体中的前沿推理和编排而构建,可为智能体工作负载提供 5 倍推理速度提升和高达 30% 的成本降低。Nemotron 3 Ultra 针对 NVFP4 格式进行了优化,使模型托管更加快速且更具成本效益。
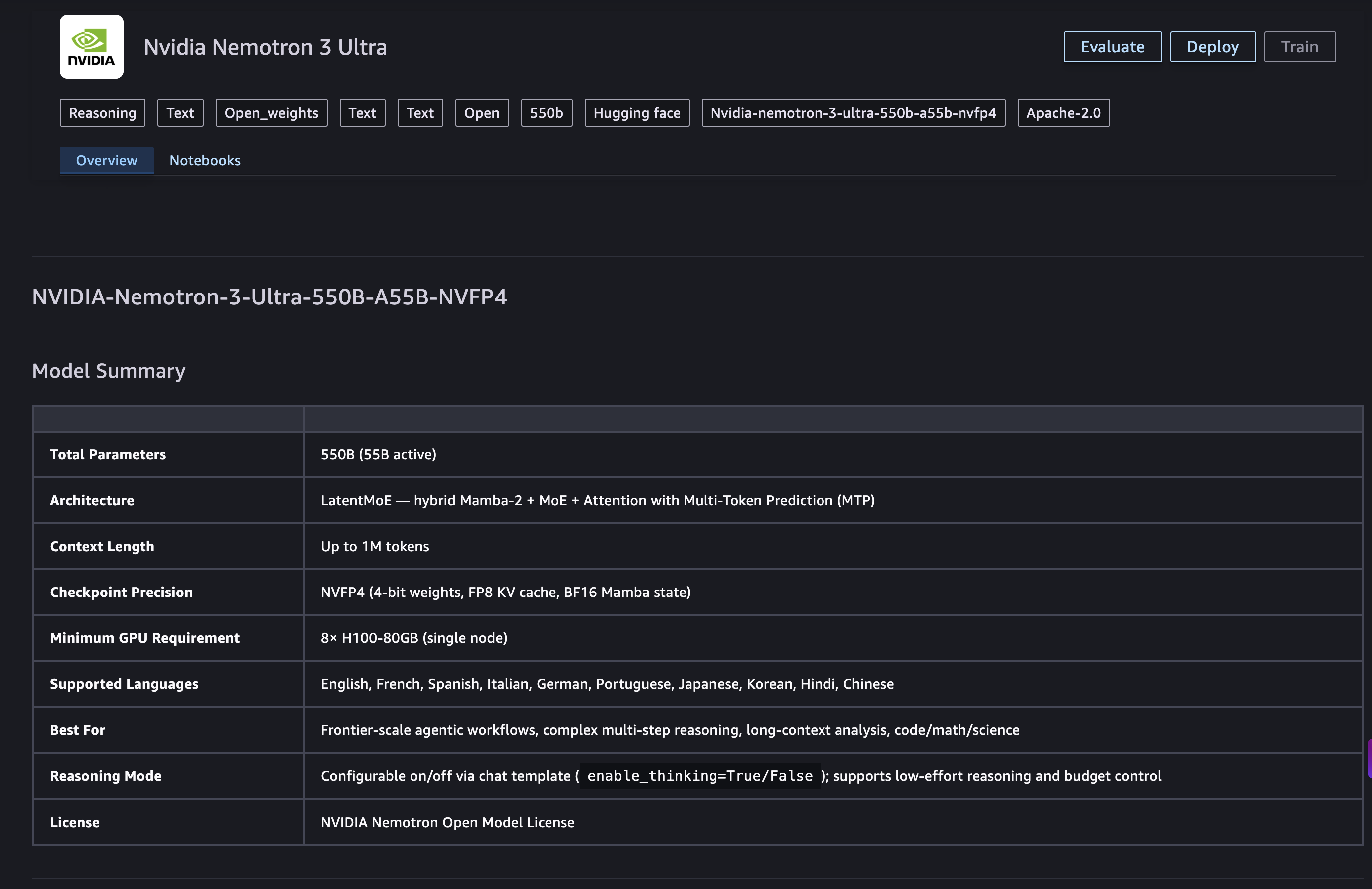
NVIDIA Nemotron 3 Ultra 概述
NVIDIA Nemotron 3 Ultra 是一个开放的大语言模型,拥有 5500 亿总参数和 550 亿激活参数。它基于混合 Transformer-Mamba 专家混合(MoE)架构构建,旨在以同等质量稠密模型计算成本的一小部分,提供前沿智能。
| 规格 | 详情 | | --- | --- | | 架构 | 混合 Transformer-Mamba MoE | | 参数 | 总计 5500 亿 / 激活 550 亿 | | 上下文长度 | 最高 100 万 token | | 输入 / 输出 | 文本输入,文本输出 | | 精度 | NVFP4 | | 推理速度 | 长期运行的智能体工作流快 5 倍 | | 成本 | 复杂智能体任务成本降低高达 30% |
为什么智能体 AI 需要专用模型
智能体并非只回答一次问题。它们会进行规划、调用工具、将工作委派给子智能体、检查结果,并在数百轮对话中持续运行。每一步都会增加 token 和计算消耗,因此真正重要的指标是有效准确率下的任务完成率、完成时间和单任务成本。
Nemotron 3 Ultra 直接解决了这一问题。其 MoE 架构在每次前向传播中仅激活 5500 亿参数中的 550 亿,即使在百万级 token 上下文长度下也能保持高吞吐量。这意味着智能体可以维持跨越数百轮的规划、工具调用和自我纠正循环,同时有助于保持连贯性并控制成本。
企业应用场景
Nemotron 3 Ultra 在需要持续多步推理的工作负载中表现出色:
- 智能体编排器 – 协调多个子智能体,管理长工具调用链中的状态
- 编程智能体 – 在大型代码库中生成、测试、调试和迭代代码
- 深度研究 – 综合多源信息,在扩展上下文中保持连贯的推理
- 复杂企业工作流 – 通过决策分支和错误恢复自动化多步业务流程
开始使用 SageMaker JumpStart
您可以通过 Amazon SageMaker JumpStart 一键部署 Nemotron 3 Ultra,无需管理基础设施或配置服务框架。
先决条件
在开始之前,请确保您具备:
- AWS 账户
- 适用于 SageMaker JumpStart 的适当权限范围
- 充足的 GPU 实例服务配额(例如 ml.p5en.48xlarge、ml.p5.48xlarge 或 ml.g7e.48xlarge)
重要提示: 部署此模型会创建一个 SageMaker 端点,该端点在运行期间会产生费用。像 ml.p5en.48xlarge 这样的 GPU 实例每小时可能花费数美元。详情请参阅 Amazon SageMaker AI 定价。完成后请务必删除您的端点,以避免持续产生费用。
使用 SageMaker Studio 部署
- 打开 Amazon SageMaker Studio
- 在左侧导航窗格中,选择 SageMaker JumpStart
- 搜索 Nemotron 3 Ultra
- 选择模型卡片
- 选择“部署”
- 选择您的实例类型(支持的实例类型为 ml.p5en.48xlarge、ml.p5.48xlarge 或 ml.g7e.48xlarge)
- 查看部署设置(默认设置足以满足大多数用例)
- 选择“部署”以创建端点
- 等待端点状态显示为 InService,然后再进行推理

使用 SageMaker Python SDK 部署
import sagemaker
from sagemaker.jumpstart.model import JumpStartModel
model = JumpStartModel(
model_id="huggingface-reasoning-nvidia-nemotron-3-ultra-550b-a55b-nvfp4", # Verify in SageMaker JumpStart model card
role=sagemaker.get_execution_role(), # Your SageMaker execution role ARN
)
predictor = model.deploy(accept_eula=True)Python
运行推理
payload = {
"messages": [{
"role": "user",
"content": "Break this task into subtasks, identify which tools are needed, and run them in sequence."
}],
"max_tokens": 20480,
"temperature": 0.6,
"top_p": 0.95,
}
response = predictor.predict(payload)
print(response["choices"][0]["message"]["content"])Python
清理资源
为避免产生不必要的费用,请在完成后删除 SageMaker 端点:predictor.delete_endpoint()
结论
NVIDIA Nemotron 3 Ultra 将前沿级推理能力引入 Amazon SageMaker JumpStart,为智能体工作负载提供 5 倍推理速度提升和高达 30% 的成本降低。其混合 Transformer-Mamba MoE 架构和百万级 token 上下文窗口,使其专为生产环境智能体所需的持续、多步推理而构建。
无论您是在构建智能体编排器、编程智能体、深度研究系统还是复杂的企业自动化,Nemotron 3 Ultra 现已可通过 SageMaker JumpStart 随时部署。
立即在 Amazon SageMaker JumpStart 中搜索 Nemotron 3 Ultra 开始使用。
- * *
关于作者
Dan Ferguson 是 AWS 的解决方案架构师,常驻美国纽约。作为机器学习服务专家,Dan 致力于支持客户高效、有效且可持续地集成 ML 工作流。
Malav Shastri 是 AWS 的软件开发工程师,任职于 Amazon SageMaker JumpStart 和 Amazon Bedrock 团队。他的工作重点在于帮助客户充分利用最先进的开源及专有基础模型。Malav 拥有计算机科学硕士学位。
Vivek Gangasani 是 SageMaker Inference 全球解决方案架构负责人。他负责领导 SageMaker Inference 的解决方案架构、技术上市 (GTM) 策略以及对外产品战略。他还协助企业和初创公司部署和优化生成式 AI 模型,并利用 SageMaker 和 GPU 构建 AI 工作流。目前,他专注于制定推理性能优化及相关应用场景(如 Agentic 工作流、RAG 等)的策略与内容。在业余时间,Vivek 喜欢徒步旅行、看电影和品尝各种美食。