[AINews] 微软Build大会:MAI-Thinking-1与MAI模型家族发布
![[AINews] 微软Build大会:MAI-Thinking-1与MAI模型家族发布](/api/img-proxy?url=https%3A%2F%2Fsubstackcdn.com%2Fimage%2Ffetch%2F%24s_!PL7Y!%2Cw_1456%2Cc_limit%2Cf_auto%2Cq_auto%3Agood%2Cfl_progressive%3Asteep%2Fhttps%253A%252F%252Fsubstack-post-media.s3.amazonaws.com%252Fpublic%252Fimages%252F1e8ca90a-629c-44d5-af2f-0b0cd2a60aa2_1510x886.png)
TL;DR · AI 摘要
微软在Build大会发布7款自研MAI模型,旗舰推理模型MAI-Thinking-1采用零蒸馏全量预训练并公开109页技术报告,确立其作为Tier 2前沿实验室及支持领域微调的差异化定位。
核心要点
- MAI-Thinking-1是微软首款推理模型,强调数据血缘纯净且无第三方模型蒸馏。
- 微软发布109页MAI技术报告,透明度获社区好评,区别于闭源前沿实验室。
- MAI家族包含7款从零预训练模型,覆盖代码、图像、语音及转录等垂直领域。
结构提纲
按章节快速跳转。
微软在Build大会宣布推出7款全新MAI系列模型,涵盖推理、代码生成、图像处理及语音交互等多个模态。
MAI-Thinking-1作为首款自研推理模型,采用清洁数据 lineage 且完全未使用第三方模型蒸馏技术。
微软公开了长达109页的MAI-Thinking-1技术报告,其详细程度和透明度获得了技术研究社区的积极评价。
Build大会强调了Agent安全执行层、Surface RTX Spark Dev Box及GitHub Copilot桌面端等本地化与Agent原生基础设施。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- Microsoft Build MAI Release
- MAI Model Family
- MAI-Thinking-1 (Reasoning)
- Code/Image/Voice Models
- R&D Strategy
- Zero Distillation Pretrain
- 109-page Tech Report
- Ecosystem Integration
- Agent-native Windows
- GitHub Copilot Desktop
金句 / Highlights
值得收藏与分享的关键句。
MAI-Thinking-1采用清洁数据血缘构建,且完全未使用第三方模型蒸馏。
微软发布了109页MAI-Thinking-1技术报告,因其透明度获得强烈正面反响。
MAI是一个优秀的Tier 2新兴实验室,有明显动力支持特定领域微调。
GitHub Copilot应用被定位为Agent原生软件开发的桌面主页,支持画布和跨设备连续。
标题:[AINews] Microsoft Build 大会:MAI-Thinking-1 与 MAI 系列模型
URL 来源:https://www.latent.space/p/ainews-microsoft-build-mai-thinking
发布时间:2026-06-03T05:49:02+00:00
Markdown 内容: 今天是个大日子,不仅因为我们回顾了 GitHub 与 Agent 的现状,还录制了一期 No Priors 与 Satya Nadella 的特别播客——在 MS Build 大会上,Satya 和 Mustafa 发布了 7 款全新的 MAI 模型:
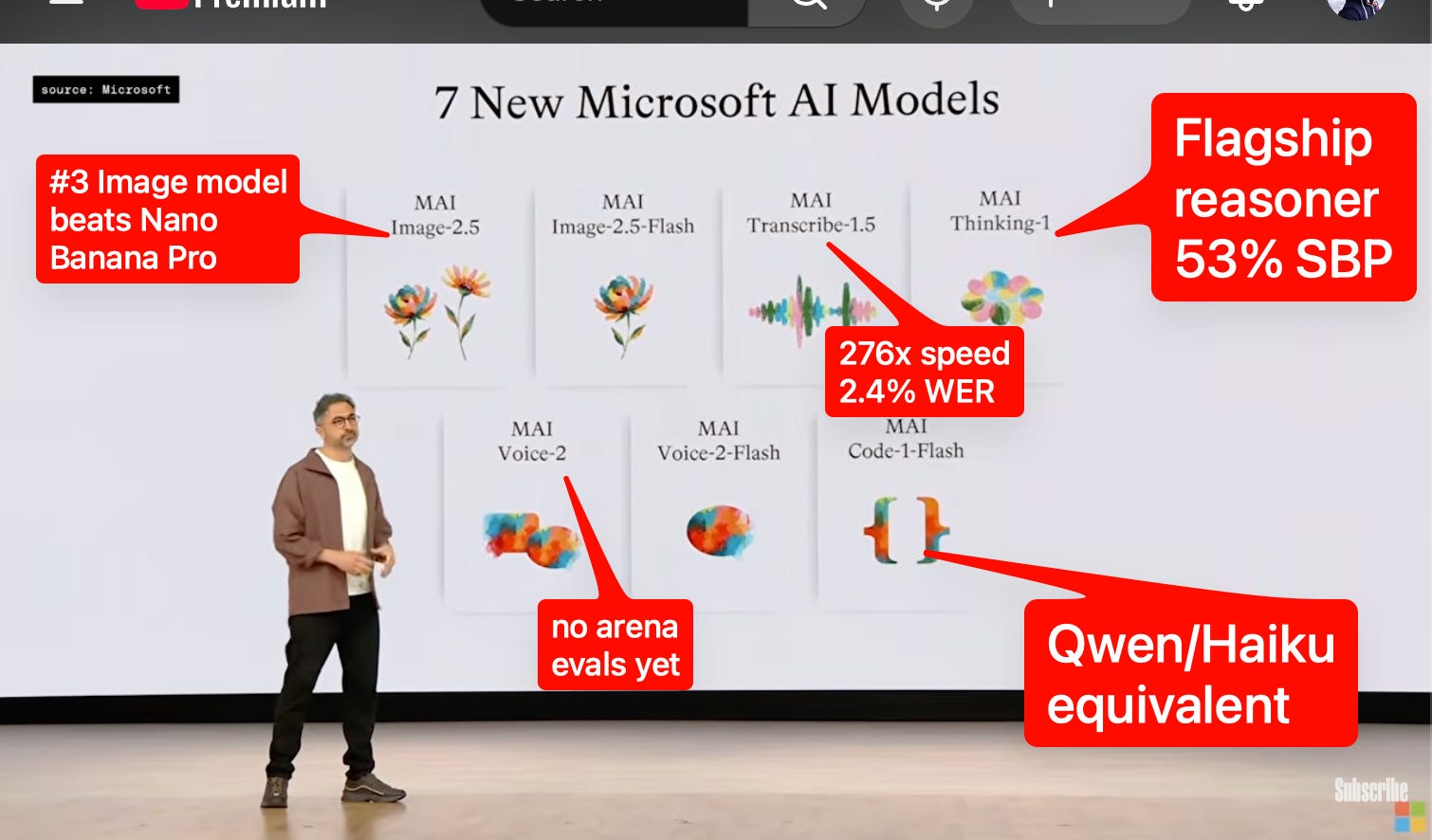
这一阵容令人印象深刻,尤其是考虑到 奠定 MAI 基础的微软-Inflection 交易仅在两年前才达成,而且这些模型均为从零开始的预训练模型。如今的 MAI 虽算不上绝对顶尖的前沿实验室,但已是一个优秀的第二梯队新兴实验室,并且有明显的动力去支持特定领域的微调(这与 几乎都已放弃微调的前沿实验室形成了鲜明对比)。
本次发布的亮点是 长达 100 多页的 MAI 技术报告,研究界对此给予了高度评价:
您可以通过 The Verge 的精彩回顾以及下方的推文摘要了解其余所有发布内容:
2026年6月1日至6月2日的 AI 新闻。我们监测了 12 个 subreddit、544 个 Twitter 账号,未覆盖其他 Discord 频道。AINews 网站支持搜索所有往期内容。提醒一下,AINews 现已成为 Latent Space 的一个专栏。您可以随时订阅或退订邮件推送!
头条新闻:Microsoft Build 大会回顾及新 MAI 模型技术细节
微软利用 Build 大会将自身定位为兼具 AI 平台公司与前沿模型实验室的双重角色,在广泛的产品发布之外,还罕见地详细披露了其全新 MAI 模型家族的技术细节。
- 据 @MicrosoftAI 和 @mustafasuleyman 透露,微软 AI 部门宣布了 七款全新 MAI 模型,涵盖推理、代码、图像、语音转录和语音领域,领衔产品包括 MAI-Thinking-1、MAI-Code-1-Flash、MAI-Image-2.5、MAI-Transcribe-1.5 和 MAI-Voice-2。
- 旗舰推理模型 MAI-Thinking-1 被定位为微软的首款推理模型。@mustafasuleyman、@baseten、@tuhinone 和 @HannaHajishirzi 在帖子中强调,该模型采用清晰的数据溯源构建,且未从第三方模型进行任何蒸馏。
- 微软为 MAI-Thinking-1 发布了一份 109 页的技术报告。@eliebakouch、@ethanCaballero、@nrehiew_、@yacinelearning 和 @stochasticchasm 等技术导向型读者对其透明度给予了强烈好评。
- 微软还重点强调了本地 AI 和原生 Agent Windows:Build 大会的宣传突出了面向 Agent 的安全执行层、全新的 Surface RTX Spark Dev Box、Windows AI 对更广泛 Windows GPU 装机量的访问能力,以及 Project Solara/Scout 等概念硬件。相关内容由 @yusuf_i_mehdi、@TheTuringPost、@kimmonismus 和 @kimmonismus 进行了总结。
- Build 大会还大力推广了 GitHub Copilot 应用,将其打造为“原生 Agent 软件开发的桌面大本营”,新增了 Canvas(画布)、跨设备连续性以及更紧密的 GitHub Agent 工作流。相关消息来自 @pierceboggan 和 @lukehoban,@techgirl1908 也发表了评论。
- 微软推出了 Web IQ,这是一套面向 AI Agent 的全新基准/搜索 API 技术栈。@JordiRib1 表示,这些 API 目前已驱动“当今业界几乎所有的 AI Agent 和聊天机器人,包括 Copilot 和 ChatGPT”。
- Satya Nadella 将 Build 大会定义为生态系统的里程碑时刻,而非单一产品的发布会;而 Mustafa Suleyman 则将其描述为微软内部“爬坡机器”的产出成果。相关推文来自 @satyanadella 和 @mustafasuleyman,@nrehiew_ 也作出了回应。
- @mustafasuleyman 介绍称,MAI-Thinking-1 是一款拥有 35B 活跃参数的 MoE 模型,支持 256K 上下文窗口。
- @scaling01 的另一份独立摘要指出,该模型为 1T@35B 参数模型,使用 30T token 进行预训练,并采用 8192 块 GB200 GPU 完成训练;这似乎是对技术报告的解读,而非微软的营销文案。
- @kimmonismus 同样将其概括为 激活参数为 45B 的中型 MoE 模型,但这与 Mustafa 本人公布的 35B 激活参数 数据相矛盾;在这些推文中,更具权威性的数据应为官方公布的 35B 激活参数。
- 据 @mustafasuleyman 和 @asadovsky 透露,微软宣称该模型在 AIME 2025 上得分 97%,在 SWE-Bench Pro 上得分 53%;Surge 平台的盲测人工评估员总体上更倾向于选择该模型,而非 Sonnet 4.6。
- 据 @mustafasuleyman 表示,微软称该模型已针对 MAIA 200 进行优化;在端到端运行 MAI 模型时,与 GB200 相比,其 每美元性能提升 30%,每瓦性能提升 1.4 倍。
- 据 @baseten、@tuhinone 和 @MicrosoftAI 的消息,微软及其合作伙伴反复强调 未使用第三方蒸馏、“数据来源清晰”,并通过 Baseten 实现企业可控的微调,确保后训练数据“100% 不可见”。
- 微软推出了 MAI-Code-1-Flash,这是一款适用于 VS Code 和 GitHub Copilot CLI 的快速代码模型,由 @pierceboggan 首次宣布,随后由 @mariorod1 重点推介。
- 微软官方通过 @mustafasuleyman 表示,Code-1-Flash 虽仅有 5B 参数,但在 SWE-Bench Pro 上仍取得了 51% 的成绩,使其在规模/成本方面接近 Haiku 级别。
- @scaling01 的一份竞争性摘要将其描述为 137B 参数的 MoE 模型,支持 256K 上下文,使用 超过 10T token 训练,且“比 Claude 4.5 Haiku 更强、更高效”。这可能指的是 5B 激活参数 而非总参数量;虽然这些推文并未完全厘清这一区别,但综合来看,均暗示其 在一个大得多的 MoE 架构中仅激活了极少量的参数。
- 据 @scaling01 和 @mariorod1 称,该模型发布时的可用性被强调为 优先支持 GitHub Copilot / VS Code。
- 微软发布了 MAI-Image-2.5 及其 Flash 变体,宣称两者均在排行榜上位列 第二;@mustafasuleyman 表示它们在图像编辑方面超越了 Nano Banana 2。
- 独立排行榜账号也印证了这一高排名:@arena 报告其在 Image Edit Arena 中排名第二,得分为 1401,比 Nano Banana 2、Grok Imagine 和 ChatGPT Image Latest HF 高出 10 分。
- @arena 进一步指出,MAI-Image-2.5 “推进了帕累托前沿”,这意味着在同价位模型中,没有模型在该基准测试上的得分能超过它。
- 分发合作伙伴迅速跟进,包括 @OpenRouter 和 @fal。
- @ArtificialAnlys 报告称,MAI-Transcribe-1.5 在语音转文本(STT)前沿领域展现出极为出色的速度与精度平衡:约为实时速度的 276 倍,AA-WER 为 2.4%,在其排行榜上 综合排名第三。
- 据 @ArtificialAnlys 介绍,该模型支持 43 种语言,包括英语、法语、阿拉伯语、日语和中文,并支持针对人名和医学术语等生僻词的 关键词偏置(keyword biasing) 功能。
- 据 @ArtificialAnlys 报道,通过 Microsoft Foundry 使用的定价为 每 1,000 分钟音频 6 美元。
- OpenRouter 也在 @OpenRouter 中将此模型列为当天上线的三个 MAI 模型之一。
- MAI-Voice-2 出现在微软的“七大模型”阵容以及 OpenRouter 的可用性公告 @OpenRouter 中。
- 除发布/可用性信息外,这批推文中关于 Voice-2 本身的技术细节寥寥无几。
- 技术社区的主要反响是认为微软发布了一份异常详尽的前沿模型报告:@eliebakouch 称其为“同规模模型中最透明的报告之一”,@nrehiew_ 表示它“完全可以作为当今 LLM 训练的更新版教科书”,而 @stochasticchasm 则称之为“金矿”。
- 多位读者强调,该报告披露了 流水线细节、扩展阶梯方法论、数据整理流程、基础设施指标及 MFU 数值;正是这种详尽程度赢得了 @ethanCaballero、@eliebakouch 和 @nrehiew_ 的赞誉。
- 评论中反复提及的一项重大技术声明是,MAI-Thinking-1 不仅在后期训练阶段,而且在整个已披露的流程中都未使用合成数据且未进行蒸馏,相关讨论来自 @eliebakouch、@stochasticchasm 和 @HannaHajishirzi
- @eliebakouch 指出,报告明确提到数据源自 Common Crawl 及私有来源,并针对不同领域设计了专门的子处理流程,进行了大量的数据提取与去重工作,且有意识地选择了不使用合成数据
- 报告中用于扩展决策的内部私有 NLL 评估集被 @eliebakouch 概括为以下构成:
- 50% 代码
- 17.5% STEM(科学、技术、工程、数学)
- 17.5% 数学
- 10% 通用知识
- 5% 多语言
- @eliebakouch 表示,在扩展阶梯中进行架构晋升是基于效率增益 (EG) 指标:即基线模型需要多少额外算力才能达到候选模型的损失水平
- 同一讨论串还提到了在大约 每参数 100/200 tokens 规模下进行的消融实验,该设置被描述为接近“Chinchilla 最优”,同时指出由于 MoE 结构的存在,这与稠密模型的经验法则有所不同,详见 @eliebakouch
- 最受关注的技术选择是,微软似乎是从一个此前未接触过推理任务的检查点开始进行强化学习 (RL) 的,这一做法令许多读者印象深刻。@stochasticchasm 称这是一个“非常有趣的决定”,而 @stochasticchasm 则对图表中显示的从 AIME25 <20% 跃升至 >95% 的表现做出了反应
- @HannaHajishirzi 将这种“从零攀登”的训练方案描述为:简单的配方、严谨的科学、自蒸馏、耐心以及强大的基础设施
- @soldni 将这一过程形容为“像大厂那样,不靠蒸馏向上攀登”
- 一些独立读者从报告中推断,尽管微软在此处刻意避免使用,但在更广泛的领域中,合成数据对于 Agent 性能仍然极具价值;参见 @stochasticchasm
- 一个引起 DSPy/晚期交互 (late-interaction) 社区高度关注的细节是:据报道,微软在预训练数据筛选和质量评分中使用了 GEPA / DSPy 优化的 LLM 评判器
- 这一点由 @bj2rn、@LakshyAAAgrawal 和 @lateinteraction 重点指出
- 据 @eliebakouch 透露,微软据报公开了各迭代阶段的精确 MFU(模型 FLOPs 利用率),多位读者表示在这一规模下极少有团队会分享此类数据
- @scaling01 总结此次训练运行使用了 8192 块 GB200 GPU
- @eliebakouch 特别提到报告中每瓦吞吐量提升约 40% 之类的数据,认为这“令人印象深刻,看好微软芯片”,不过这可能指的是机架级预算或服务配置,推文中并未完全展开说明
- 微软官方将模型设计与 MAIA 200 定制芯片联系起来,并强调相较于 NVIDIA GB200,其具有更优的性价比和能效比,详见 @mustafasuleyman
- Build 大会关于 Windows/本地 AI 的宏大叙事也围绕硬件规格展开,例如:
- 在 DGX Station 上本地运行 1 万亿参数模型
- 128GB 统一内存
- 110 TOPS AI 算力
- 20 个 CPU 核心
- 70 多款 PowerToys 实用工具,来自 @TheTuringPost
- 相关反响也指向了大模型的本地运行,例如 @kimmonismus 提到的在 RTX Spark 上本地运行 1200 亿参数模型
- GitHub 发布了 GitHub Copilot 应用,@pierceboggan 将其定位为面向 Agent 原生软件开发的桌面端界面
- 核心主题包括:
- 支持用户与 Agent 双向协作的 Canvas(画布),来自 @Techmeme
- 跨 CLI、移动端、Web、本地和云端的连续性体验,来自 @lukehoban
- GitHub 作为 Agent 工作流中心的地位日益凸显,体现在 @techgirl1908 和 @OrenMe 的评论中
- Copilot CLI 还推出了实验性的终端 UI,支持标签页、内置反馈/橡皮鸭调试、提示词调度和语音输入,来自 @GHchangelog
- 微软 Windows 团队将 Build 大会的主题围绕“更快的开发者执行速度、安全的 Agent 执行层以及在设备本地运行的无计量智能”展开,来自 @yusuf_i_mehdi
- 多篇帖子强调,微软希望 Windows 成为 Agent 的可信执行平台,而不仅仅是 Azure
- @TheTuringPost 将 Project Solara 描述为一个面向 Agent 优先设备的平台,其概念包括:
- 一款桌面端 AI 伴侣
- 一枚集成摄像头、麦克风、传感器及安全认证功能的可穿戴徽章
- @kimmonismus 将这些设备视为用于控制智能体(Agent)的手持或桌面终端,并将其与人们对 OpenAI 独立硬件的预期进行了对比。
- @kimmonismus 还特别提到了 Microsoft Scout,称其为“面向工作场景的常驻个人智能体”。
- @JordiRib1 发布了 Microsoft Web IQ,这是一套专为网页、新闻、图像和视频设计的 AI 原生基准化(Grounding)API。
- 他的这一表述提供了重要的背景信息:传统搜索引擎是为人类设计的,但微软认为未来的搜索需求将主要来自智能体,其查询量可能达到人类搜索流量的 1000 倍。
- 他表示,Web IQ 基于 Bing 技术栈进行了重构,旨在优化质量、延迟和 Token 效率,并且目前已为包括 Copilot 和 ChatGPT 在内的主流聊天机器人提供支持。
- @jeffboudier 提到,Satya 指出 Microsoft Foundry 中已提供超过 11,000 个模型,其中 10,928 个来自 Hugging Face。
- 这也印证了微软在 Build 大会上展现的双重定位:既是自研模型构建者,也是大型多模型托管与分发平台。
- 多位观察者注意到,Build 大会期间关于数据中心扩建引发了社区争议,而微软则辩称 AI 基础设施的扩张不会导致当地社区的电力成本上升;相关讨论参见 @kimmonismus 和 @kimmonismus。
- @scaling01 重点提及 Mustafa 的观点:未来三年内 AI 算力将增长 1000 倍,即从当前前沿规模约 5e27 FLOPs 提升至 2029 年的 5e30 FLOPs。
- @mustafasuleyman 将公司的核心哲学理念概括为“人文主义超级智能”。
- 微软在 Build 大会上发布了 七款全新 MAI 模型:@MicrosoftAI。
- MAI-Thinking-1 官方指标:35B 激活参数的 MoE 架构、256K 上下文窗口、AIME 2025 得分 97%、SWE-Bench Pro 得分 53%,且在盲测中的人类偏好度优于 Sonnet 4.6:@mustafasuleyman。
- MAI-Code-1-Flash 官方指标:SWE-Bench Pro 得分 51%,推文文案中标注参数量为 5B:@mustafasuleyman。
- 关于 MAI-Image-2.5 的排名表现,独立评测账号 @arena 也给出了相同的结论。
- MAI-Transcribe-1.5 的速度与精度详情源自独立基准测试账号 @ArtificialAnlys。
- 微软发布了一份长达 109 页的技术报告:@eliebakouch。
- @teortaxesTex 发出的“微软现在开始训练正经模型了?”是对该模型及报告质量的解读性反应,并非独立事实陈述。
- 关于该报告是“最透明的报告之一”或“堪称更新版教科书”的说法,分别出自 @eliebakouch 和 @nrehiew_ 的个人观点,尽管许多读者对此表示认同。
- @kimmonismus 和 @TheTuringPost 将 Build 大会解读为微软从纯云端 AI 向本地推理与智能体方向的战略转型;这属于分析观点,而非官方措辞。
- 部分帖子声称微软“泄露”了 Anthropic Mythos 的 FLOPs 数据,包括 @swyx 和 @scaling01 的发文,这些均是对某张幻灯片的推测性解读,随后同一批评论者也对此提出了质疑。
- 技术领域的读者普遍对该报告的透明度以及微软愿意公开同体量下通常保密的细节表示赞赏:@eliebakouch、@nrehiew_、@ethanCaballero、@stochasticchasm。
- 一些人认为 MAI-Thinking-1 证明了微软正成为真正的顶尖前沿实验室,而不仅仅是模型转售商或应用层厂商,例如 @teortaxesTex、@echen、@NandoDF。
- 多篇帖子的重点在于阅读和解析这份技术报告,而非单纯为产品发布欢呼,尤其是 @stochasticchasm、@nrehiew_ 和 @eliebakouch。
- 部分评论者在解读基准测试结果时保持了审慎态度。@kimmonismus 指出,微软似乎是在整体层面上与 Sonnet 4.6 进行对比,仅在 SWE Pro 测试中才具备与 Opus 相当的水平。
- @iScienceLuvr 特别赞赏了报告中对 健康基准测试(如 HealthBench Professional 和 MedXpertQA)的关注,而不仅仅局限于代码/数学能力。
- 部分人士质疑所有数据和比较是否得到了正确解读,尤其是在活跃参数(active params)和外部模型对比方面。
- 最明显的质疑集中在所谓的 Mythos FLOP“泄露” 上。@iScienceLuvr 认为这可能只是一个估算值,而非真实泄露;@scaling01 随后指出原始的 6.1e27 FLOP 数据并不现实,并提供了一个较低的替代估算值,之后又在 @scaling01 中发布了更正声明。
- 业界也对 零合成数据 / 零蒸馏 是否是实现最佳智能体性能的长期正确方案持保留态度,正如一些读者强调合成数据差异的重要性一样,例如 @stochasticchasm。
- Build 大会的发布之所以重要,是因为它们表明微软不再满足于仅仅扮演以下角色:
- Azure/OpenAI 的云托管商
- GitHub 的开发者平台
- Copilot 的应用外壳
它正致力于成为拥有自有模型系列、芯片堆栈和后训练平台的 第一方前沿模型开发商。
- 强调 清晰的数据来源 / 无蒸馏 具有战略意义。这回应了企业在知识产权溯源、未来可控性以及对外部实验室依赖性方面的担忧。
- 强调 本地 AI 同样重要,因为微软正将 AI 战略与 Windows 和设备分发渠道绑定,而不仅仅是依赖 Azure。Build 大会的信息反复传递了一个理念:推理模型、规划器和智能体将越来越多地在 设备端 运行,而不仅限于云端:@TheTuringPost、@yusuf_i_mehdi。
- 这份 109 页的报告 意义重大,因为前沿模型的透明度一直在下降,尤其是在数据、基础设施和训练方法方面。多位研究人员明确指出,这种规模的披露程度实属罕见:@eliebakouch、@nrehiew_。
- Build 大会回顾还显示微软正试图整合技术栈的所有层级:
- 模型:MAI 系列
- 芯片:MAIA 200
- 云:Azure + Foundry
- 操作系统:Windows 智能体运行时
- 开发者体验:Copilot 应用 / VS Code / CLI
- 检索/落地:Web IQ
- 硬件形态:Solara / Scout 概念产品
- 正是这种组合,使得多位观察家认为此次活动与其说是一场普通的开发者大会,不如说是向 涵盖云、边缘、操作系统和自研模型的智能体平台 迈出的协同一步,例如 @satyanadella、@mustafasuleyman 和 @TheTuringPost。
- 在 Build 大会期间及之后,有用户声称微软的一张幻灯片无意中泄露了 Anthropic 传闻中的 Claude Mythos 的训练算力,@swyx 询问 Mustafa 是否泄露了 FLOP 数量。
- @scaling01 通过像素测量估算出该幻灯片暗示了 6.1e27 FLOPs 及相应的置信区间,而 @kimmonismus 指出这大约相当于 Gemini 3.1 Pro 级别 的算力。
- 这一解读随后受到 @iScienceLuvr 的挑战,他认为这可能只是一个估算值;接着 @scaling01 发布了一个基于模型的较低范围估算值,即 3.37e26 至 1.46e27 FLOPs,并随后在 @scaling01 中表示原始数据是 错误的。
- 这一插曲主要作为背景参考颇具价值:Build 大会关于算力/扩展的信息足够详细,以至于人们开始尝试从演示材料中推断竞争对手的训练预算。
开发者工具、智能体和编程工作流
- OpenAI 推出了 Codex Sites,允许团队将创意/文档/计划转化为已部署的内部网站/应用,支持身份验证和动态数据,首批面向商业/企业用户开放,详见 @OpenAI、@TheRohanVarma 和 @gdb。
- OpenAI 还扩展了 特定角色的 Codex 插件,覆盖销售、数据分析、创意制作、产品设计和公共股权工作流,提供对 62 个应用和 110 项技能 的访问权限,来自 @OpenAI 和 @OpenAIDevs。
- GitHub 的 Copilot 应用 以及微软在 Build 大会上围绕智能体原生软件开发的推广是当日工具类新闻的核心:@pierceboggan、@lukehoban、@GHchangelog。
- Anthropic 发布了 Claude Platform CLI,并升级了 Claude Code 的
/fork命令,使其能够运行带有精确上下文和提示缓存的后台智能体,详见 @ClaudeDevs 和 @ClaudeDevs。
- Nous 发布了 Hermes Desktop,这是一个面向 Hermes 智能体的本地/原生桌面交互界面,相关公告来自 @NousResearch 和 @Teknium,随后 @Teknium 和 @ollama 还分享了 Tailscale/Ollama 的集成说明。
- Cognition 推出了 Devin Desktop,定位为智能体中立的桌面平台,用于管理本地/云端智能体,并支持在本地规划与云端执行之间进行任务交接,相关信息来自 @cognition、@ScottWu46 以及 @russelljkaplan。
模型、本地推理与路由
- H Company 发布了 Holo 3.1,这是一个基于 Qwen 架构的本地计算机操作模型系列,参数规模覆盖 0.8B 至 35B,支持 NVFP4、FP8 和 Q4 GGUF 等格式;一篇广受关注的评测指出其 35B 模型在 AndroidWorld 上取得了 79.3% 的成绩(来自 @TeksEdge),发布推文见 @hcompany_ai。
- Perplexity 宣布为 Perplexity Computer 推出混合智能体推理功能,将任务分配给设备端本地模型和前沿云端模型,以兼顾隐私保护和 Token 效率,详见 @perplexity_ai 和 @AravSrinivas。
- @ttunguz 分享的 OpenRouter 数据显示,开放权重模型的 Token 消耗量占比达 69.1%,而闭源模型仅占 30.9%。
- 关于模型路由作为未来关键抽象层的讨论,可参见 @ClementDelangue、@garrytan 和 @matanSF 的观点;@glennko 则提出了反对意见,认为企业生产环境对可靠性的严苛要求使得通用路由的实施难度远高于爱好者的预期。
- 本地 AI 的用户体验也得到了改善,包括 Hugging Face 推出的硬件兼容性检测功能,以及 oMLX 发布的原生 macOS 应用,分别来自 @m_newhaus 和 @jundotkim。
研究与评估
- Google DeepMind 发布了 Co-Scientist,这是一个基于 Gemini 的多智能体科学假设生成系统。据称该系统已在多项合作研究中发挥作用,协助发现了肝纤维化靶点、ALS(肌萎缩侧索硬化症)治疗方案以及与衰老相关的遗传线索,详见 @GoogleDeepMind、@GoogleDeepMind 和 @GoogleDeepMind。
- 新提出的 Crafter / CraftEditor 研究因其在可编辑科学图表生成方面的进展而备受关注。该工作采用五智能体工作流,实现了图表的生成与优化,并支持光栅图像到 SVG 格式的转换,相关讨论来自 @HuggingPapers、@_akhaliq 和 @TheTuringPost。
- Tilde Research 提出了 Wall Attention,这是一种无需 RoPE 且带有对角遗忘门的注意力机制。该方法在 4k 长度下训练,却能泛化至 200k+ Token,同时提供了 Triton kernel 实现及出色的解码吞吐量,详见 @tilderesearch。
- @jbhuang0604 分享了一种机器人视觉编码器,该方法通过编码动态感知能力而非依赖静态图像预训练,声称在真实世界 OOD(分布外)场景下的成功率提升了 +22.5%。
- 值得关注的新评估/基准测试:
- PaintBench:用于精确图像编辑的基准测试,目前最优模型准确率仅为 17.1%,来自 @itskaixu。
- VSTAT:用于视频状态跟踪的基准测试,指出当前前沿 MLLM 在追踪动态变化的世界状态方面仍然较弱,来自 @PinzhiHuang 和 @sainingxie。
- Data Agent Benchmark:面向企业数据工作流的智能体基准测试,来自 @sh_reya。
推理、基础设施与智能体系统
- Harvey 与 LangChain 联合分享了针对法律智能体的低成本验证器研究成果。结果表明,使用 DeepSeek V4 Flash 可在保持与 Opus 4.7 94–96% 一致性的同时,将单条标准验证成本降低 18 倍,批量模式成本降低约 1000 倍;在 3,200 次 RL rollout 的场景下,验证成本从 $18,000 降至 $18,详见 @harvey、@hwchase17 和 @nikogrupen。
- W&B 重新发布了 Weave,将其定位为“智能体优先”的可观测性平台,集成了主流测试框架,并支持自动检测故障模式,详见 @wandb 和 @neutralino1。
- Prime-RL 将 Mooncake Store 与 vLLM 集成,实现了跨节点的 prefix / KV cache 复用,这被认为是智能体 rollout 的关键技术,详见 @m_sirovatka。
- Together 详细介绍了 MiniMax-M3 的服务端优化方案,通过 KV-block-major 稀疏注意力、分页解码、索引评分优化及多模态预处理等技术,实现了 81–125% 的吞吐量提升,详见 @togethercompute。
- MiniMax 官方在 @MiniMax_AI 中重点介绍了其 100 万上下文窗口、原生多模态能力、桌面端操作功能,以及通过 MSA 技术将注意力机制在解码阶段的耗时占比从 约 30% 降至约 5%。
生态系统、硬件与产业能力
- Westmag 结束隐身模式正式亮相,致力于打造美国本土的机器人执行器和无人机电机。该公司已完成 1100 万美元融资,由 a16z 领投,Founders Fund、Lux、NFDG、Menlo 等机构参投。详见 @boxcardavid、@packyM 及 @oyhsu。
- PyTorch 在 @PyTorch 中指出,NVIDIA 已在四个开源模型系列中采用了 OpenMDW-1.1——一种宽松的 AI 模型许可框架。
- 马丁·斯科塞斯(Martin Scorsese)公开演示了与 Black Forest Labs 合作,在前期制作阶段有限度地使用 FLUX 进行故事板创作。他强调此举旨在探索新技术,作为手绘工作的补充,而非用生成式 AI 取而代之。详见 @robrombach 和 @TheRundownAI。