[AINews] Anthropic与SpaceXai达成300MW/$50亿/年协议,用于Colossus I,ARR增长达8000%
![[AINews] Anthropic与SpaceXai达成300MW/$50亿/年协议,用于Colossus I,ARR增长达8000%](/api/img-proxy?url=https%3A%2F%2Fsubstackcdn.com%2Fimage%2Ffetch%2F%24s_!yEoG!%2Cw_1456%2Cc_limit%2Cf_auto%2Cq_auto%3Agood%2Cfl_progressive%3Asteep%2Fhttps%253A%252F%252Fsubstack-post-media.s3.amazonaws.com%252Fpublic%252Fimages%252Fd591a434-a112-4fb9-829a-30ff2e4efbf5_2260x1442.png)
TL;DR · AI 摘要
Anthropic在开发者大会上宣布与SpaceXai达成300MW/$5B/年的Colossus I算力合作,年化ARR增长达8000%,并发布Claude托管代理三大新功能。
核心要点
- Anthropic与SpaceXai达成约50亿美元/年的算力协议,快速接管Colossus I超算集群。
- 公司年化ARR增长率高达8000%,反映AI需求爆发和商业化加速。
- 未来聚焦三大趋势:微型团队创业、多智能体系统、企业服务。
结构提纲
按章节快速跳转。
Anthropic未发布新模型,重点展示合作进展与产品更新。
快速接管Colossus I,达成300MW/$5B/年协议,强化AI基建布局。
ARR年化增速达8000%,体现Claude产品线强劲采用势头。
聚焦微型团队、多智能体协作与企业级AI服务拓展。
应用Amdahl定律识别并优化软件工程中的关键瓶颈。
推出托管代理三项新能力,提升个体与组织生产力。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- Anthropic 2026 开发者大会
- 核心合作
- SpaceXai
- Colossus I (300MW/$5B/yr)
- 商业成果
- ARR年化增长8000%
- Claude最大发布之一
- 战略方向
- 微型团队
- 多智能体系统
- 企业服务
- 技术洞察
- Amdahl定律应用
- 安全与可验证性
金句 / Highlights
值得收藏与分享的关键句。
There’s a unique opportunity for single individuals or very tiny teams to do things that are incredible.
Starting with a team of smart people in a room and working our way up to a ‘country of geniuses in a datacenter’.
We’re increasingly going to help whole teams and organizations be more productive and more than the sum of its parts.
Taking over all of Colossus 1 in the next few days — a roughly $5B/year deal.
The ARR growth is 8000% annualized — one of the fastest scaling AI businesses ever.
Security, verifiability — finding the bottlenecks in software engineering and removing them.
标题:[AINews] Anthropic与SpaceXai达成300MW/$50亿/年的Colossus I协议,ARR增长年化达8000%
来源网址:http://www.latent.space/p/ainews-anthropic-spacexais-300mw5byr
发布时间:2026-05-07T05:57:14+00:00
Markdown 内容: 今天是Anthropic的第二届年度开发者活动,现场氛围极为热烈。虽然没有发布重磅新模型——这是某些(预期不准的)人所期待的——但重点基本集中在与SpaceX的合作官宣(有望挑战Claude有史以来最大规模的发布),为Claude托管代理推出的3项新功能,以及对过去六个月所有已发布成果的回顾、重新介绍和庆祝:
在埃隆亲自批准后,可能还带有战略意图,恰逢他针对OpenAI的诉讼正在审理中,Anthropic正以惊人速度接管整个Colossus 1系统(“未来几天内”),据一些估算,这大约是一笔每年50亿美元的交易,使xAI成为一家新型云服务商:
另一大亮点是Amodei兄妹参与的访谈环节,宣布了公司ARR实现80倍增长,并就中美竞争对手情况发表了评论:
Dario关注的趋势包括:
- [微型团队](https://www.latent.space/p/tiny):他仍然认为2026年将见证一人创立十亿美元公司的出现。“_一个人或极小团队具备巨大的潜力去完成不可思议的事情……在过去,如果你有一个想法或愿景,你需要积累多年资源才能实现它;而现在,个人或极小团队拥有了独特的机会,从模型编写代码,到模型协助我们将软件工程视为一项任务,再到模型帮助我们思考如何将创建企业或经济单元本身当作一项任务。_”
- [多智能体系统](https://www.latent.space/p/scaling-test-time-compute-to-multi?utm_source=publication-search):“从房间里一群聪明人开始,逐步扩展成‘数据中心里的天才国度’。”
- [企业服务](https://www.latent.space/p/ainews-silicon-valley-gets-serious):“Claude Code帮助个体提升效率,但我们越来越致力于帮助整个团队和组织提升效率,并实现整体大于部分之和的效果。”
- 瓶颈问题:Claude当然在加速自身发展,但他也在思考Amdahl定律——安全性和可验证性——即找出软件工程中的瓶颈并消除它们,从而加快整体流程。
主舞台其余环节内容还包括:
必须了解的Claude Code更新:

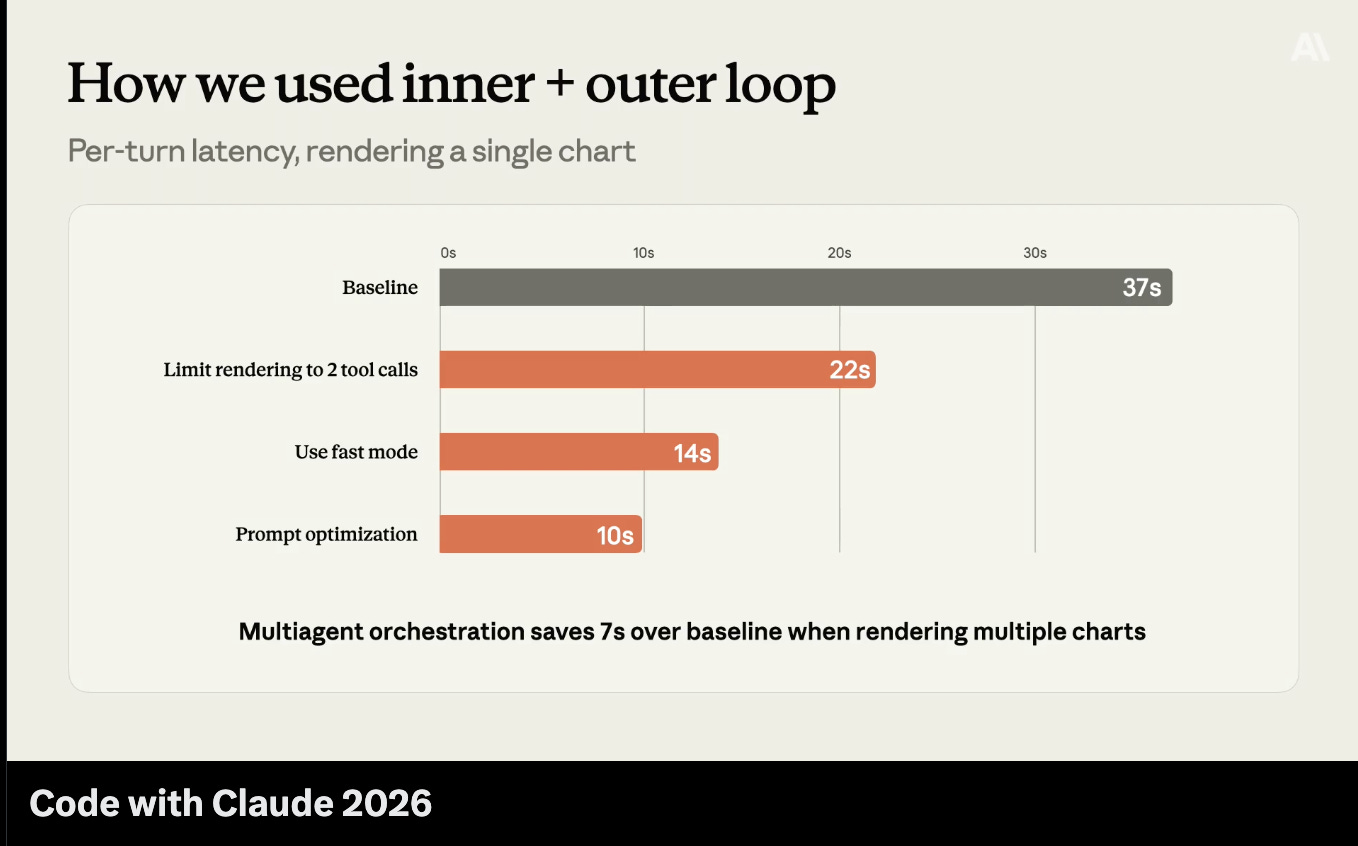
关于内循环与外循环的更多成果内容……

……用于代理的自动优化:
AI 新闻,2026年5月5日-5月6日。我们检查了12个子版块、544条推文,未查看其他Discord频道。AINews官网支持搜索所有过往期数。提醒一下,AINews现已成为Latent Space的一个栏目。你可随时选择订阅或退订邮件推送频率!
Anthropic迎来密集新闻周期,核心围绕算力、Claude Code使用限制及代理平台发展方向。
- 官方宣布,Anthropic与SpaceX达成新的算力合作,将“显著提升”其算力容量,并立即转化为Claude产品更高的使用上限:@claudeai 表示该协议带来的算力增长足以提高使用限制,随后 @claudeai 公布具体细节:Claude Code的5小时速率限制对Pro、Max、Team以及按席位计费的企业版用户翻倍;Pro和Max用户的高峰时段限流取消;Opus API的速率限制也大幅提高。
- xAI将此交易描述为Anthropic通过SpaceXAI获得 Colossus 1 的访问权限,以获取“更多Claude运行容量”@xai,而Anthropic首席技术官Tom Brown补充称,Claude推理将在“未来几天内”开始在Colossus上逐步扩大规模@nottombrown。
- 公司还举办了 “Code with Claude” 活动,包括直播主题演讲,以及关于Claude Code、GitHub级应用和托管代理的专题会议 @ClaudeDevs,引发开发者和观察者实时大量讨论 @simonw, @latentspacepod。
- 围绕这些动态,讨论延伸出四个主题:
- (1) 算力瓶颈比许多人预想的更严重,据称是由于意外激增的使用量所致;
- (2) 用户欢迎5小时限制的提升,但质疑每周限制为何未变;
- (3) 人们争论Anthropic新推出的托管代理功能(如记忆/“梦境”和评分标准/“成果”)究竟是真实的产品差异化,还是可被轻易复制的封装特性;以及
- (4) Anthropic在安全与治理方面的立场继续引发赞扬与批评,有批评者指出部分Anthropic员工表现出“只有我们才配拥有AGI”的态度,而与Anthropic关系密切的声音则反驳称,公司内部更普遍的看法其实是“没人能被信任拥有AGI”,而非“只有我们” @_aidan\_clark_, @kipperrii。
- Anthropic宣布与 SpaceX建立算力合作伙伴关系,以提升其算力容量 @claudeai。
- 自即日起,Anthropic表示将实施以下措施:
- 将Claude Code的5小时速率限制对Pro、Max、Team和按席位计费的企业版用户翻倍
- 取消Pro和Max用户在高峰时段的使用限制下调
- 大幅提高Opus模型API的速率限制
来源:@claudeai
- Anthropic发布了官方说明链接,解释更高使用限制及与SpaceX的算力合作 @claudeai。
- xAI的公告将该安排描述为 SpaceXAI向Anthropic提供Colossus 1的访问权限,以增加Claude的算力 @xai。
- Anthropic CTO Tom Brown表示,Claude推理将在数日内开始在Colossus上逐步扩展@nottombrown。
- Anthropic产品与工程负责人Amol Avasare澄清,目前尚未提高每周使用限制,因为仅有一小部分用户触及每周上限,而触及5小时限制的用户比例要大得多;随着新算力资源到位,未来可能还会进一步调整 @TheAmolAvasare, @TheAmolAvasare。
- Anthropic/Claude举办了 “Code with Claude” 活动,内容包括主题演讲、Claude Code更新、GitHub级使用案例和托管代理等环节 @ClaudeDevs。
- Anthropic的Alex Albert推广了此次活动,并在之后总结此次发布为 “更多芯片,更多Claude”@alexalbert__, @alexalbert__。
- 专用账号 @claude_code 重申了对Pro/Max/Team用户的限制提升 @claude_code。
多条推文补充了有关SpaceX/xAI合作规模的量化信息。这些并非来自Anthropic官方公告推文,但被广泛传播:
- @scaling01 称Colossus 1包含 约15万台H100、5万台H200和3万台GB200。
- @Yuchenj_UW 重复了 22万台GPU 的数字,并添加一项未经证实的说法:Anthropic已承诺投入 2000亿美元用于Google TPU。
- @eliebakouch 将该协议解读为 Anthropic 实际上获得了 Colossus 1 的全部算力,而不仅仅是空闲的 GPU。
- 埃隆·马斯克随后表示,SpaceXAI 愿意出租 Colossus 1 是因为 xAI 已经将训练迁移至 Colossus 2@elonmusk,而 @eliebakouch 声称 Colossus 2 目前已有约 50 万个 Blackwell 芯片。
这些数字最好被视为接近官方但未被 Anthropic 自身公告线程完全确认的信息。比起具体的设备数量,更可靠的结论是:Anthropic 获得了一次规模巨大、短期内即可投入使用的外部推理算力扩展。
一个反复出现的观点是,Anthropic 真正的瓶颈确实是算力,而不仅仅是定价或产品设计问题。
- @kimmonismus 在直播期间及之后提问,Anthropic 是否会免费将 Claude Code 的速率限制提高一倍。
- @kimmonismus 后来总结了 Dario 和 Daniela 一次访谈中的发言:使用量意外增长了约 80 倍,这据称导致了算力短缺,而与 SpaceX 的合作是首次大规模应对这一问题的尝试。
- @czajkadev 明确将此次更新解读为算力是瓶颈的证据。
- @theo 单独指出,行业的问题“不只是钱,而是算力”,尽管这是一个更广泛的论点,但它与 Anthropic 的情况相符。
- @scaling01 从这笔交易中提炼出一个宏观判断:前沿实验室的算力紧张到足以向竞争对手租用数据中心。
这是数据集中最有力的事实和市场信号之一:Anthropic 面向用户的速率限制只有在达成重大算力协议后才出现了实质性调整。
Anthropic 对用户的实际影响显而易见:
- Claude Code 的重度用户在 5 小时窗口期内可使用的突发容量增加。
- Pro/Max 用户在高峰时段的限流情况得到缓解。
- Opus API 用户获得更高的速率限制,这对智能体工作负载和生产级集成尤为重要。
此次事件也凸显了 Anthropic 在智能体平台方面的更大野心。虽然主要的官方推文大多聚焦于事件本身,但相关评论提到了以下功能:
- Dreaming = 记忆 / 跨会话上下文
- Outcomes = 评分标准 / 评估 / 目标追踪
- 智能体编排 / 受管智能体方向
评论分析:
- @RichNwan 认为 Anthropic 正在通过 Dreaming 和 Outcomes “构建其受管智能体平台”,但也质疑这些功能相比开源框架是否具有真正的差异化优势。
- @eliebakouch 认为这些功能对重度用户至关重要,尤其是用于保留主智能体的上下文窗口,并使用独立的评估器来管理质量、安全性和奖励欺骗问题。
- @latentspacepod 引述 Anthropic 发言人强调验证的重要性,“例程是高阶提示”,并指出当前的主要差距往往在于部署和落地应用,而非原始能力。
最后这一点表明,Anthropic 正与其他趋势一致,从“单次聊天机器人”转向具备记忆、任务分解、评分和验证的结构化智能体系统。
大量回复将此视为用户的胜利,并认为这证明 Anthropic 正在积极应对挑战。
- @alexalbert__:“更多芯片,更多 Claude。”
- @_sholtodouglas:“更多算力 → 直接惠及你。”
- @kimmonismus 强调了速率限制翻倍以及 Opus API 上限的提升。
- @TheRundownAI 将其总结为一项直接的用户利好。
- @DannyLimanseta 赞赏这种跨公司合作,并希望 Anthropic 的谨慎能与 SpaceXAI 的乐观形成平衡。
- @AmandaAskell 对公告所传递的象征意义表示欢迎。
这些观点欢迎变化,但更关注操作细节和仍存在的限制。
- @btibor91 和 @kimmonismus 立即指出了可能的局限:每周上限保持不变。
- @TheAmolAvasare 直接回应了这一点。
- @sbmaruf 报告称变更后仍遇到速率限制,暗示部署和可靠性调优仍在进行中。
- @zachtratar 呼吁在分阶段推出期间保持耐心。
另一类观点则从 OpenAI 与 Anthropic 的产品竞争角度看待此次公告。
- @scaling01 认为 Anthropic 因等待过久而错失增长优势,可能让 OpenAI 获得了数十亿美元的 ARR(年度经常性收入)。
- @Yuchenj_UW 认为此举表明 Dario 因 OpenAI Codex 的快速增长 而变得激进。
- @dejavucoder 发推称“claude 挂了,圣蒂博请重置 codex 限制”,这反映了当某个服务容量受限时,开发者在多种编程工具之间多栖使用的现实情况。
这是最深层的哲学分歧。
- @_aidan\_clark_ 批评了他反复从 Anthropic 同事那里听到的观点:只有他们自己才值得被信任来构建 AI。
- @kipperrii 部分同意,“只有我们可被信任”这种说法确实有问题,但他认为主流观点更接近于 “没有人能被信任拥有 AGI”,尽管他个人仍比其他公司更信任 Anthropic。
- @elonmusk 在与 Anthropic 领导层会面后,给出了出人意料的支持表态。
- @Yuchenj_UW 指出这一转变颇具讽刺意味,鉴于此前曾批评过 Anthropic。
- @teortaxesTex 嘲笑了 Musk/xAI 与 Anthropic 之间迅速达成的缓和关系。
- @teortaxesTex 还指出,一边警告他人 AI 风险,一边又在构建如“Mythos”这样的强大闭源系统,是前后矛盾的。
- @goodside 的评论虽未直接涉及 Anthropic 的治理问题,但参与了围绕 Anthropic 展开的更广泛的道德与 AI 规范讨论。
尽管这些推文中没有出现新的 Claude 模型,Claude 仍是产品和评估讨论中的重要参照点。
- @giffmana 对“Opus 4.6”、ChatGPT Pro 和 Muse Spark 在一道数学争议题上的表现进行了比较。他的结论是:
- Opus 4.6 坚信一个错误的证明(“精神操控”)
- ChatGPT Pro 正确地统一了公式,但缺乏解释
- Muse Spark 两者都做得很好
这虽然是个例,但却是这批数据中较为具体的一次定性模型对比报告。
- @kimmonismus 总结了一篇 Substack 分析,称 GPT-5.5 在网络安全任务上基本与 Claude Mythos Preview 持平,甚至更具成本效益,而 Mythos 仅在部分通用基准和 SWE-bench Pro 上略微领先;他质疑为何 Mythos 仍如此保密。
- @AssemblyAI 提到其网关已支持 Claude 4.5+ 模型输出结构化 JSON。
- @OpenRouter/TencentHunyuan 将 Claude Code 列为推动 Hy3 使用的主要应用之一,表明即使幕后使用的是第三方模型,Claude 在编程工具生态中依然举足轻重。
这些评论并未确立明确的模型排名,但显示出 Claude 仍是编码代理工作流中的主要基准,且高级用户正越来越多地比较 模型 + 工具链 + 限制 + 可靠性,而不仅仅是基础智能水平。
贯穿整个数据集的一个显著背景主题是:许多工程师现在认为,代理性能高度依赖于工具链(harness)——包括系统提示、工具、中间件、任务分解策略以及针对特定模型的调优。
相关的非 Anthropic 评论还包括:
- @masondrxy:相同模型、相同任务,因提示词/工具/中间件不同而导致评分差异巨大;在 tau2-bench 上得分波动可达 10–20 分。
- @LangChain:发布了适用于 OpenAI、Anthropic 和 Google 模型的工具链配置文件。
- @jakebroekhuizen:区分了随着模型进步而发生的 时间维度上的工具链演化 与 跨模型家族的横向调优。
- @Vtrivedy10:认为定制化的工具链在许多任务上可超越默认的 Codex/Claude Code;当前许多代理设计的有效上下文窗口仍仅为 50–100k。
- @kieranklaassen:“如果你无法在 Claude CLI 中完成工作,那么 Claude 就不会对你有用。”
这一点之所以重要,是因为 Anthropic 的一些平台动向——记忆功能、评分系统、托管代理——可以被理解为 将工具链的某些部分产品化。这也解释了当前的核心争论:这些是具有护城河的平台级能力,还是开放框架也能复制的一方优势包装?
- 推理,而不仅仅是训练,如今已成为前沿瓶颈。
此次发布并非新模型,而是算力容量的扩展。这种情况在技术前沿正变得越来越普遍。
- 算力市场正变得灵活且具有战略性。
Anthropic 与 SpaceX/xAI 基础设施的合作打破了“每家前沿实验室仅依赖自身垂直整合堆栈”的简单叙事。
- 开发者产品份额对可靠性与限制极为敏感。
Claude 虽然拥有较强的开发者亲和力,但速率限制和宕机问题会迅速促使用户转向 Codex、Cursor 或其他工具。
- 竞争战场正从基础模型转向代理系统。
“Code with Claude”、托管代理、Dreaming、Outcomes 以及相关讨论均表明,下一轮竞争的核心将是 记忆能力、编排机制、评估体系和工作流集成。
- Anthropic 的品牌形象仍然两极分化。
它同时具备以下特征:
- 因产品质量和安全严肃性而受到钦佩,
- 因家长式作风或排他性倾向而遭到批评,
- 并且现在在计算资源方面展现出比以往更强的商业进取姿态。
Anthropic 的新闻与其说是一个炫目的新模型,不如说反映了一种结构性现实:Claude 的需求已超过可用算力,Anthropic 为此达成了一项重大的外部基础设施协议,并立即放宽了关键用户限制@claudeai, @claudeai。最重要的技术/经济信号是:容量、速率限制和代理产品的人机交互设计,如今已与排行榜上的性能差距具有同等战略重要性。目前主要的未解问题包括:Anthropic 能否将这种产能转化为持续的产品 momentum,其托管代理功能是否真正具备差异化优势,以及其安全与治理立场在面对 OpenAI、Google、xAI 和开源模型生态日益激烈的竞争时,究竟是助力还是阻碍。
- OpenAI 及其合作伙伴发布了 MRC(多路径可靠连接),这是一种用于大型 AI 训练集群的开放网络协议,目前已部署于 OpenAI 最大的超级计算机上 @OpenAI, @OpenAI。评论强调了多路径路由、微秒级故障切换,以及网络正成为制约系统性能的主要瓶颈之一 @kimmonismus, @gdb。
- Perplexity 表示其构建了内部推理引擎 ROSE,覆盖从嵌入模型到万亿参数 LLM 的各类模型,并使用 CuTeDSL 加速在 Hopper 和 Blackwell 架构上的专用内核开发 @perplexity_ai。
- vLLM 联合 Mooncake 在面向代理工作负载的系统优化中取得显著成果,通过可复用前缀实现了:3.8 倍吞吐量提升、P50 TTFT 降低 46 倍、端到端延迟降低 8.6 倍,缓存命中率从 1.7% 提升至 92.2%,并扩展至 60 块 GB200 GPU@vllm_project。
- Unsloth 联合 NVIDIA 发布了三项训练优化技术,声称可使家用 GPU 上的 LLM 训练速度提升约 25%:序列打包元数据缓存、双缓冲检查点重载,以及更快的 MoE 路由 @UnslothAI。
- NVIDIA 在 强化学习(RL)中实现无损推测解码 的研究被重点提及,称其可在 235B 规模下实现 约 2.5 倍的端到端 RL 加速,在 8B 模型上实现 约 1.8 倍的 rollout 吞吐提升,且不改变策略分布 @TheTuringPost。
- Baseten 推出 Frontier Gateway,为闭源权重实验室提供托管基础设施/API/认证/速率限制/计费一体化服务;Poolside 报告称从项目启动到上线仅用 7 周,Laguna XS.2 的 P50 TTFT 为 146ms,Laguna M.1 为 605ms @tuhinone, @poolsideai。
- ProgramBench 探讨语言模型是否能从零重建程序,超越传统的修复类 SWE 任务 @ComputerPapers,Ofir Press 认为基准测试是“藏宝图”,定义了我们期望的未来 @OfirPress。
- Terminal-Bench 2.1 修复了 TB2.0 中的 28/89 项任务;排名基本保持不变,但绝对得分变动高达 12 分,这提醒我们代理基准的维护具有实际意义 @terminalbench, @ekellbuch。
- OBLIQ-Bench 成为一项重要的信息检索(IR)基准发布,聚焦于困难的首阶段检索任务——当前检索器难以从大规模语料库中发现隐含相关的文档 @dianetc_,获得多位 IR 研究者的高度评价 @lateinteraction, @nlp_mit, @LightOnIO。
- Harvey 推出 LAB,一个开源的长周期法律代理基准,涵盖 24 个实践领域中的 1,200 项任务,获得 LangChain、Baseten、Artificial Analysis 等机构的支持与评论 @saranormous, @ArtificialAnlys。
- 多条推文共同强调了一个主题:评测框架工程是一等一的关键变量,即使使用相同的基座模型,良好的框架设计也能在代理基准上带来 10–20 分 的提升 @masondrxy, @LangChain, @Vtrivedy10。
- Zyphra 发布 ZAYA1-8B,一种推理型 MoE 模型,激活参数少于 10 亿,采用 Apache 2.0 开源许可,声称在数学与推理效率方面表现优异,并可通过测试时计算接近更大模型的性能 @ZyphraAI, @ZyphraAI。评论称赞其架构、后训练栈及与 AMD 的合作 @teortaxesTex, @eliebakouch。
- Google 的 Gemma 4 在 Code Arena 中推动了开源模型的帕累托前沿:Gemma-4-31B 排名第 13,Gemma-4-26B-A4B 排名第 17(在开源模型中)@arena, @_philschmid。
- Google 的 Gemma-4 专用草稿模型 DFlash 被描述为其训练过的最佳草稿模型之一,在编程和数学任务中表现尤为出色 @jianchen1799。
- Qwopus3.6-35B-A3B-v1 声称在单张 RTX 5090 上实现 162 tok/s,目标是在消费级硬件上实现强大的单次前端/网页生成 @KyleHessling1。
- DeepSeek 的评价褒贬不一:据报道其融资谈判正瞄准由一家主要的中国国有半导体基金牵头、高达 450 亿美元估值 的目标 @jukan05,而评测者则对 V4-Pro 在 WeirdML 测试中表现弱于 GLM/Kimi/开源竞品展开了争论 @htihle, @teortaxesTex。
- Cursor 添加了跨规则、技能、MCP 和子代理的 上下文使用情况细项分析,以帮助调试上下文问题 @cursor_ai,并描述了如何使用早期 Composer 模型引导未来版本 Composer 的训练 @cursor_ai。
- Cognition 在 Windsurf 2.0 中推出了 Devin Review 和 Quick Review / SWE-Check 功能,明确针对 AI 生成代码审查这一新瓶颈 @cognition, @ypatil125。
- OpenAI 推广了 Codex 子代理,将其定位为将任务分配给多个专业化代理,并将结果合并回单一回答的方法 @reach_vb。
- Nous/Hermes 继续推进高度可插拔的本地代理架构:推出插件扩展、社区文档、Windows/WSL2 配置指南以及用例汇总 @Teknium, @witcheer, @NousResearch。
- Perplexity 在其 Agent API 中新增 金融搜索(Finance Search),集成授权数据、实时市场数据和引用来源,声称在 FinSearchComp T1 测试中准确率最高、每条正确答案成本最低 @perplexity_ai, @AravSrinivas。
- 谷歌 Gemini API 在文件搜索中加入 多模态检索 功能,通过
gemini-embedding-2实现对 PDF 和图像的统一检索流程 @_philschmid。
- Genesis AI 推出 GENE-26.5,介绍了一个端到端的机器人项目,包含原生面向机器人的基础模型、类人手部结构、数据手套及模拟器;该模型在 语言、视觉、本体感知、触觉和动作 多个模态上进行训练 @gs_ai_, @theo_gervet。
- Meta FAIR 发布 NeuralBench,一个采用 MIT 许可证的 NeuroAI 统一基准框架,涵盖 36 项 EEG 任务 和 94 个数据集,并计划支持 MEG/fMRI @hubertjbanville, @JeanRemiKing。
- Sander Dieleman 发布了一篇关于 流图(flow maps) 的长篇技术文章,探讨学习扩散模型积分以实现更快采样及相关技巧 @sedielem。
- François Fleuret 提出了一个构建更强系统的设想方案:类似潜在扩散的推理机制 + 真实循环状态 + 世界模型预预训练@francoisfleuret,引发关于扩散式推理是否能正确外推的深入讨论 @willdepue, @jeremyphoward。
- HeadVis 被引入作为研究注意力头的新可解释性工具 @kamath_harish。
- 微软研究院关于 代理可读的可解释性 的工作提出了“Agentic-imodels”概念,即编码代理会演化出其他大语言模型也能理解的模型;报告在 65 个表格数据集 上取得提升,下游 BLADE 性能从 8% 提高至 73%@dair_ai。